







写完第一篇字符串匹配文章,发现竟然没有介绍啥是字符串匹配算法,啥是KMP,直接就开讲KMP的next数组有点唐突。而在我打算写第二篇的时候发现,我们为什么要有KMP算法,它到底比普通的算法好在哪里?回过头来想想应该把普通的暴力法也写写,这样才能明白它们的好。同时,不要以为它是暴力法就认为它不好,你没必要掌握它。同学,你知道吗?几乎所有标准库中类似字符串匹配的函数(如: java-indexof)都是采用的我们今天要将的BF(Brute Force)方法,原因见StackOverflow。
好,下面首先正式把问题摆出来,给定两个串S="s0, s1, s2, ...., sn", T="t0, t1, t2,..., tn", 在主串S中查找字串T的过程称为字符串匹配问题,T称为模式串。
BF(Brute Force)算法,应该很容易写出来,下面先给出伪码:一、伪码
1. 首先设定 S 和 T 的起始比较下标 i 和 j;
2. 循环直到 i+m>n 或者T中的字符都比较完(j==m)
2.1 如果S[i]==T[j], 继续比较S和T的下一个字符,否则2.2 将 i 和 j 回溯,准备下一轮比较
3. 如果T中的字符都比较完(j==m),则返回比较的起始下标
否则返回-1,表示匹配失败
二、实现
int strStr(const char *S, const char *T){
if(S==NULL||T==NULL) return -1;
int n = strlen(S);
int m = strlen(T);
int i=0;
while( i+m<=n){
int k=i, j=0;
for(; j<m&&k<n&&S[k]==T[j]; ++k,++j) ;
if(j==m) return i; // 匹配成功,返回比较开始位置
++i;
}
return -1; // 匹配失败
}
三、实例
假定给定主串 S="ababcabcacbab", 模式 T="abcac", BF匹配过程如下:
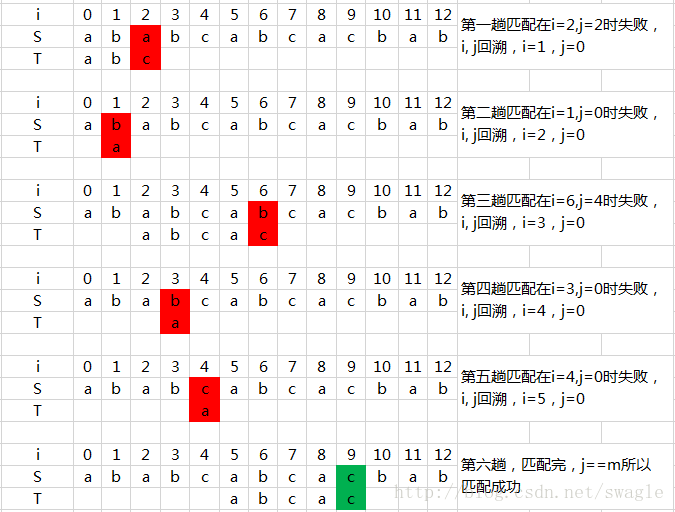
四、BF算法的缺点
BF算法的优点就是简单可靠,这跟现实中的东西一样,越简单的东西越是信得过的(纯属娱乐:东哥也说了'她是我见过的最单纯的女孩'),可见简单就是好,而复杂的东西限制要求多。
BF算法的确定就是一遇到比较失败的时候就需要回退到前面重新开始比较,之前比较匹配过的信息完全用不上,一句话就是不智能嘛。
五、标准库为啥要采用BF而不采用KMP,BM喃?
打开上面StackOverflow的链接,就能见着答案,我这里把英文贴出来,为防止有些童鞋一见English就头大,大概翻译了下。
The more advanced string search algorithms have a non-trivial setup time. If you are doing a once-off string search involving a not-too-large target string, you will find that you spend more time on the setup than you save during the string search.And even just testing the lengths of the target and search string is not going to give a good answer as to whether it is "worth it" to use an advanced algorithm. The actual speedup you get from (say) Boyer-Moore depends on the values of the strings; i.e. the character patterns.
The Java implementors have take the pragmatic approach. They cannot guarantee that an advanced algorithm will give better performance, either on average, or for specific inputs. Therefore they have left it to the programmer to deal with ... where necessary.
大概意思就是,像KMP,BM这些高级算法的会有预处理时间和会消耗一些空间,在处理一些不是非常大的字符串的时候,时间不会有太大优势,而且还会占用一些空间。
另外,我本人开通了微信公众号--分享技术之美,我会不定期的分享一些我学习的东西.

(转载文章请注明出处: http://blog.csdn.net/swagle/article/details/24012567 )















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









