







新闻数据抓取
这篇文章,主要是记录自己学习爬虫过程。
整篇部分会分为2篇文章,
- 1,爬取http的网页(新闻网站):获取各类主题的新闻的内容,eg:金融,体育,娱乐等等。
- 2,爬取https的网页(豆瓣):获取豆瓣电影的影评。
从简到难,所以我们先http从爬取
第一部分:爬虫基础
1,简单的知识的介绍
先简单看一下http和https两者的概念的区别参考
1.1、HTTP和HTTPS的基本概念
HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
HTTPS:是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
1.2、HTTP与HTTPS有什么区别?
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
1.3 HTTPS的工作原理
我们都知道HTTPS能够加密信息,以免敏感信息被第三方获取,所以很多银行网站或电子邮箱等等安全级别较高的服务都会采用HTTPS协议。

简单的来说,对于爬取网页的内容来说:http在爬取过程中不需要输入账号密码,而https需要输入账号和密码,以及由于密码账号会带来的一系列的问题。导致,爬取https相对复杂一点。
二,选用的框架 scarpy
2.1介绍一下scrapy
在 这里
有Scarpy简单的框架的介绍
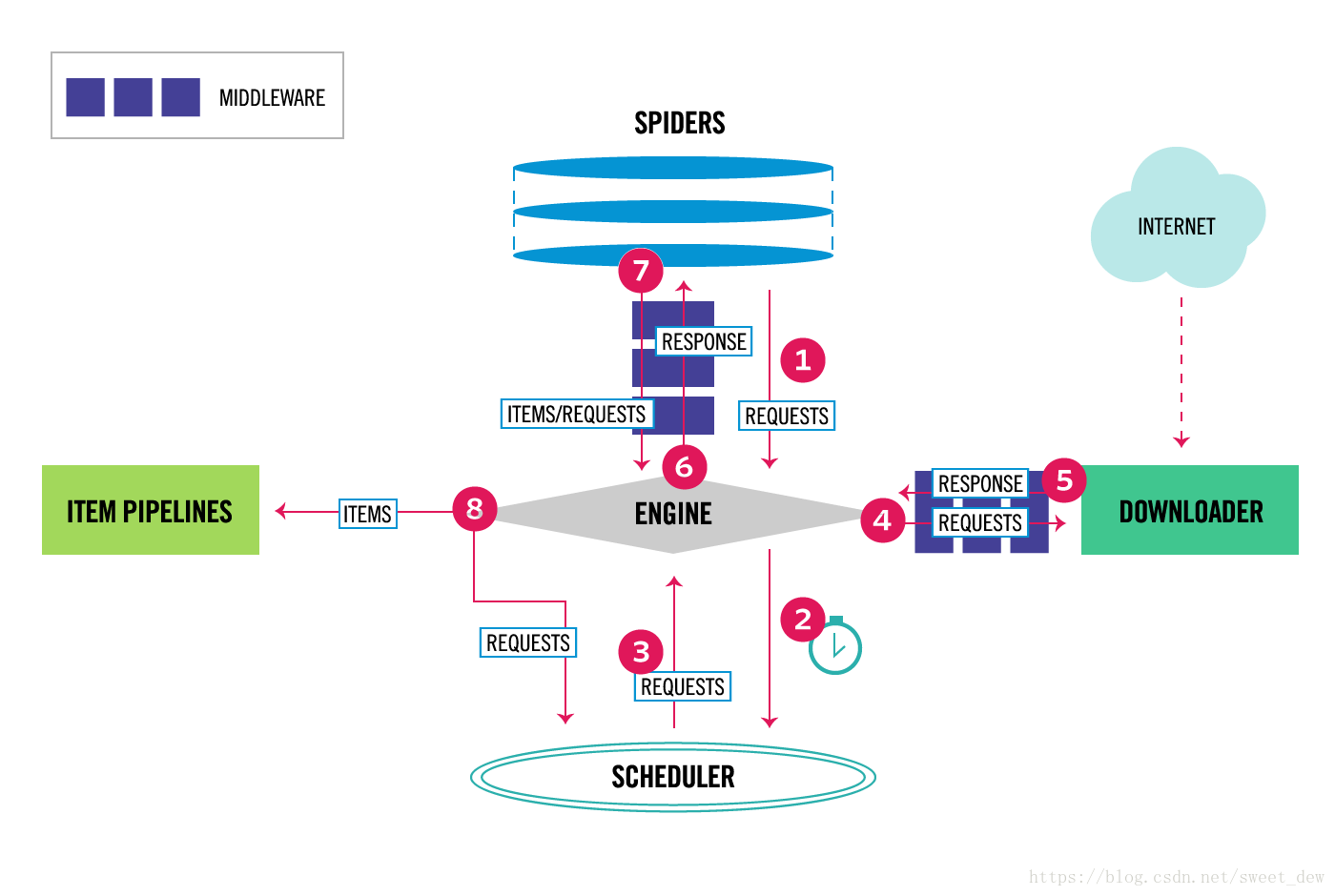
2.1.1 Scrapy结构
- 引擎(Scrapy Engine)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









