







转载处:http://blog.csdn.net/v_JULY_v/article/details/6545192
第二部分、BM算法
为了更好的理解BM算法,我分三步引入BM算法。首先看看下面的一个字符串匹配算法,它与前面的回溯法差不多,看看差别在哪儿。
- /*! int search_reverse(char const*, int, char const*, int)
- */bref 查找出模式串patn在主串src中第一次出现的位置
- */return patn在src中出现的位置,当src中并没有patn时,返回-1
- */
- int search_reverse(char const* src, int slen, char const* patn, int plen)
- {
- int s_idx = plen, p_idx;
- if (plen == 0)
- return -1;
- while (s_idx <= slen)//计算字符串是否匹配到了尽头
- {
- p_idx = plen;
- while (src[--s_idx] == patn[--p_idx])//开始匹配
- {
- //if (s_idx < 0)
- //return -1;
- if (p_idx == 0)
- {
- return s_idx;
- }
- }
- s_idx += (plen - p_idx)+1;
- }
- return -1
- }
仔细分析上面的代码,可以看出该算法的思路是从模式串的后面向前面匹配的,如果后面的几个都不匹配了,就可以直接往前面跳了,直觉上这样匹配更快些。是否真是如此呢?请先看下面的例子。
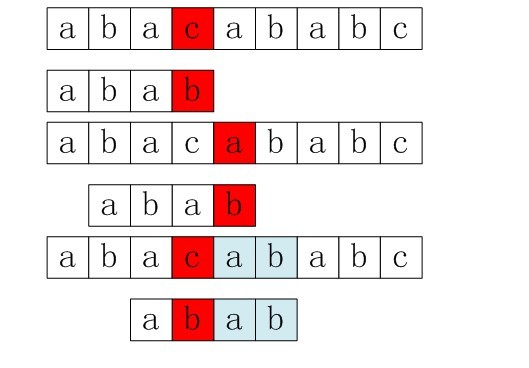

上面是详细的算法流程,接下来我们就用上面的例子,来引出坏2、字符规则,3、最好后缀规则,最终引出4、BM算法。
在上面的例子里面,第一步的时候,S[3] = ‘c’ != P[3],下一步应该当整个模式串移过S[3]即可,因为S[3]已经不可能与P中的任何一个部分相匹配了。那是不是只是对于P中不存在的字符就这样直接跳过呢,如果P中存在的字符该怎么定位呢?
如模式串为P=”acab”,基于坏字符规则匹配步骤分解图如下:
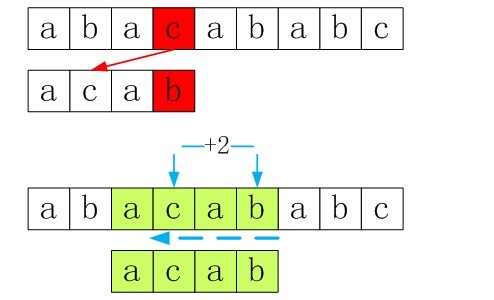
从上面的例子可以看出,我们需要建一张表,表示P中字符存在的情况,不存在,则s_idx直接加上plen跳过该字符,如果存在,则需要找到从后往前最近的一个字符对齐匹配,如上面的例子便已经说明了坏字符规则匹配方法.
再看下面的例子:
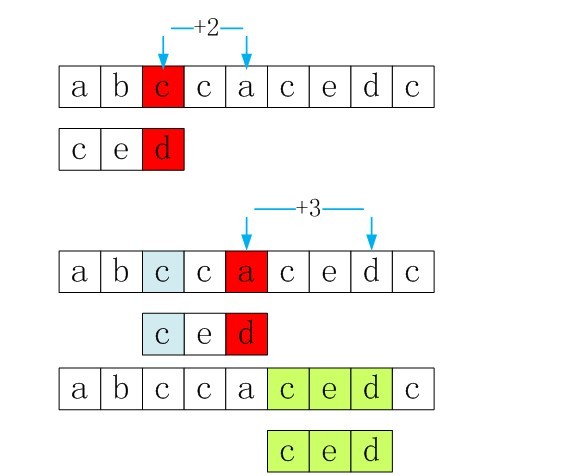
由此可见,第一个匹配失败的时候S[i]=’c’,主串指针需要+2才有可能在下一次匹配成功,同理第二次匹配失败的时候,S[i]=’a’,主串指针需要+3直接跳过’a’才能下一次匹本成功。
对于S[i]字符,有256种可能,所以需要对于模式串建立一张长度为256的坏字符表,其中当P中没出现的字符,表值为plen,如果出现了,则设置为最近的一个对齐的值。具体算法比较简单如下:
- /*
- 函数:void BuildBadCharacterShift(char *, int, int*)
- 目的:根据好后缀规则做预处理,建立一张好后缀表
- 参数:
- pattern => 模式串P
- plen => 模式串P长度
- shift => 存放坏字符规则表,长度为的int数组
- 返回:void
- */
- void BuildBadCharacterShift(char const* pattern, int plen, int* shift)
- {
- for( int i = 0; i < 256; i++ )
- *(shift+i) = plen;
- while ( plen >0 )
- {
- *(shift+(unsigned char)*pattern++) = --plen;
- }
- }
- /*! int search_badcharacter(char const*, int, char const*, int)
- */bref 查找出模式串patn在主串src中第一次出现的位置
- */return patn在src中出现的位置,当src中并没有patn时,返回-1
- */
- int search_badcharacter(char const* src, int slen, char const* patn, int plen, int* shift)
- {
- int s_idx = plen, p_idx;
- int skip_stride;
- if (plen == 0)
- return -1;
- while (s_idx <= slen)//计算字符串是否匹配到了尽头
- {
- p_idx = plen;
- while (src[--s_idx] == patn[--p_idx])//开始匹配
- {
- //if (s_idx < 0)
- //Return -1;
- if (p_idx == 0)
- {
- return s_idx;
- }
- }
- skip_stride = shift[(unsigned char)src[s_idx]];
- s_idx += (skip_stride>plen-p_idx ? skip_stride: plen-p_idx)+1;
- }
- return -1;
- }
-
3、最好后缀规则
在讲最好后缀规则之前,我们先回顾一下本部分第1小节中所举的一个简单后比对算法的例子:
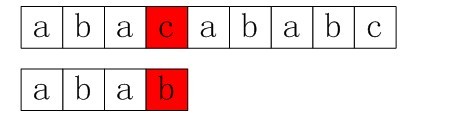
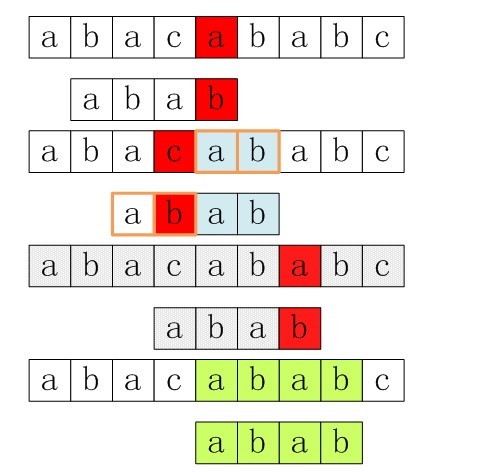
上面倒数第二步匹配是没必要的。为什么呢?在倒数第三步匹配过程中,已有最后两个字符与模式串P中匹配,而模式串中有前两个与后两个字符相同的,所以可以直接在接下来将P中的前两个与主串中匹配过的’ab’对齐,做为下一次匹配的开始。
其实思路与本文第一部分讲过的KMP算法差不多,也是利用主串与模式串已匹配成功的部分来找一个合适的位置方便下一次最有效的匹配。只是这里是需要寻找一个位置,让已匹配过的后缀与模式串中从后往前最近的一个相同的子串对齐。(理解这句话就理解了BM算法的原理)这里就不做数学描述了。
ok,主体思想有了,怎么具体点呢?下面,直接再给一个例子,说明这种匹配过程。看下图吧。
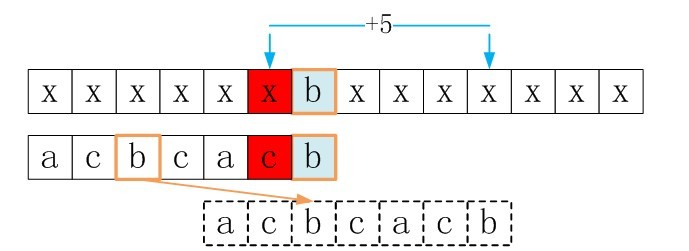
由图可以goodsuffixshift[5] = 5
下面看goodsuffixshift [3]的求解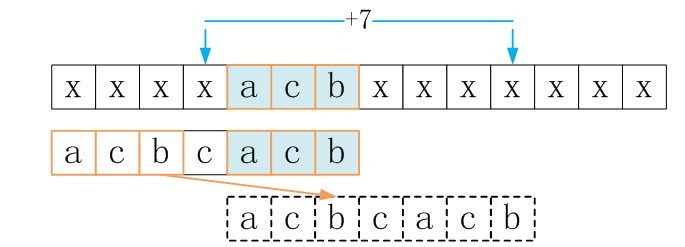
求解最好后缀数组是BM算法之所以难的根本,所以建议多花时间理清思路。网上有很多方法,我也试过两个,一经测试,很多都不算准确,最好后缀码的求解不像KMP的“最好前缀数组”那样可以用递推的方式求解,而是有很多细节。
代码如下:
- /*
- 函数:void BuildGoodSuffixShift(char *, int, int*)
- 目的:根据最好后缀规则做预处理,建立一张好后缀表
- 参数:
- pattern => 模式串P
- plen => 模式串P长度
- shift => 存放最好后缀表数组
- 返回:void
- */
- void BuildGoodSuffixShift(char const* pattern, int plen, int* shift)
- {
- shift[plen-1] = 1; // 右移动一位
- char end_val = pattern[plen-1];
- char const* p_prev, const* p_next, const* p_temp;
- char const* p_now = pattern + plen - 2; // 当前配匹不相符字符,求其对应的shift
- bool isgoodsuffixfind = false; // 指示是否找到了最好后缀子串,修正shift值
- for( int i = plen -2; i >=0; --i, --p_now)
- {
- p_temp = pattern + plen -1;
- isgoodsuffixfind = false;
- while ( true )
- {
- while (p_temp >= pattern && *p_temp-- != end_val); // 从p_temp从右往左寻找和end_val相同的字符子串
- p_prev = p_temp; // 指向与end_val相同的字符的前一个
- p_next = pattern + plen -2; // 指向end_val的前一个
- // 开始向前匹配有以下三种情况
- //第一:p_prev已经指向pattern的前方,即没有找到可以满足条件的最好后缀子串
- //第二:向前匹配最好后缀子串的时候,p_next开始的子串先到达目的地p_now,
- //需要判断p_next与p_prev是否相等,如果相等,则继续住前找最好后缀子串
- //第三:向前匹配最好后缀子串的时候,p_prev开始的子串先到达端点pattern, 这个可以算是最好的子串
- if( p_prev < pattern && *(p_temp+1) != end_val ) // 没有找到与end_val相同字符
- break;
- bool match_flag = true; //连续匹配失败标志
- while( p_prev >= pattern && p_next > p_now )
- {
- if( *p_prev --!= *p_next-- )
- {
- match_flag = false; //匹配失败
- break;
- }
- }
- if( !match_flag )
- continue; //继续向前寻找最好后缀子串
- else
- {
- //匹配没有问题, 是边界问题
- if( p_prev < pattern || *p_prev != *p_next)
- {
- // 找到最好后缀子串
- isgoodsuffixfind = true;
- break;
- }
- // *p_prev == * p_next 则继续向前找
- }
- }
- shift[i] = plen - i + p_next - p_prev;
- if( isgoodsuffixfind )
- shift[i]--; // 如果找到最好后缀码,则对齐,需减修正
- }
- }
注:代码里求得到的goodsuffixshift值与上述图解中有点不同,这也是我看网上代码时做的一个小的改进。请注意。另外,如上述代码的注释里所述,开始向前匹配有以下三种情况:
-
第一 : p_prev 已经 指向pattern的前方,即没有找到可以满足条件的最好后缀子串
-
第二 : 向前匹配最好后缀子串的时候,p_next开始的子串先到达目的地p_now, 需要判断p_next与p_prev是否相等,如果相等,则继续住前找最好后缀子串
-
第三 : 向前匹配最好后缀子串的时候,p_prev开始的子串先到达端点pattern, 这个可以算是最好的子串 。下面,咱们 分析 这个例子 :

从图中可以看出,在模式串P中,P[2]=P[6]但P[1]也等于P[5],所以如果只移5位让P[2]与S[6]对齐是没必要的,因为P[1]不可能与S[5]相等(如红体字符表示),对于这种情况,P[2]=P[6]就不算最好后缀码了,所以应该直接将整个P滑过S[6],所以goodsuffixshift[5]=8而不是5。也就是说,在匹配过程中已经得出P[1]是不可能等于S[5]的,所以,就算为了达到P[2]与S[6]匹配的效果,让模式串P右移5位,但在P[1]处与S[5]处还是会导致匹配失败。所以,必定会匹配失败的事,我们又何必多次一举呢?
那么,我们到底该怎么做呢?如果我现在直接给出代码的话,可能比较难懂,为了进一步说明,以下图解是将BM算法的好后缀表数组shift(不匹配时直接跳转长度数组)的求解过程。其中第一行为src数组,第二行为patn数组,第三行为匹配失败时下一次匹配时的patn数组(粉色框的元素实际不存在)。
1、i = 5时不匹配的情况
ok,现在咱们定位于P[5]处,当i = 5时src[5] != patn[5],p_now指向patn[5],而p_prev指向patn[1],即情况二。由于此时*p_prev == *p_now,则继续往前找最好后缀子串。循环直到p_prev指向patn[0]的前一个位置(实际不存在,为了好理解加上去的)。此时p_prev指向patn[0]的前方,即情况一。此时条件p_prev < pattern && *(p_temp+1) != end_val满足,所以跳出循环。计算shift[5]= plen - i + p_next - p_prev =8(实际上是第三行的长度)。
2、i = 4时不匹配的情况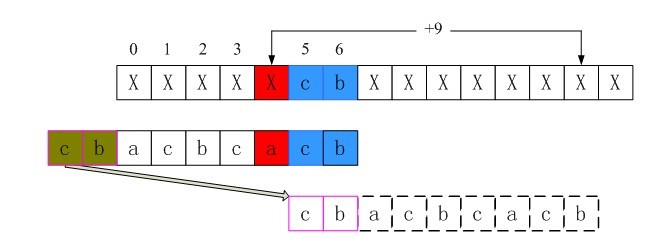
i= 4时,src[4] != patn[4],此时p_prev指向patn[0],p_now指向patn[4],即情况二。由于此时*p_prev == *p_now,则继续往前找最好后缀子串。循环直到p_prev指向patn[0]的前一个位置。此时p_prev指向patn[0]的前方,即情况一。此时条件p_prev < pattern && *(p_temp+1) != end_val满足,所以跳出循环。计算shift[4]= plen - i + p_next - p_prev =9(实际上是第三行的长度)。
3、i = 3时不匹配的情况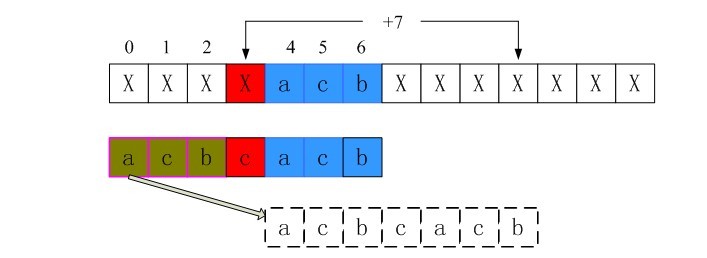
同样的过程可以得到,i = 3时shift[3]也为第三行的长度7。
4、i = 2时不匹配的情况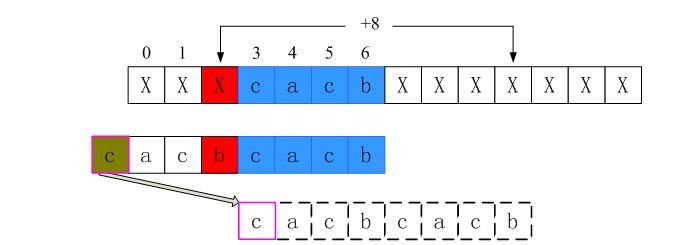
同样的过程可以得到,i = 2时shift[2]也为第三行的长度8。
5、i = 1时不匹配的情况
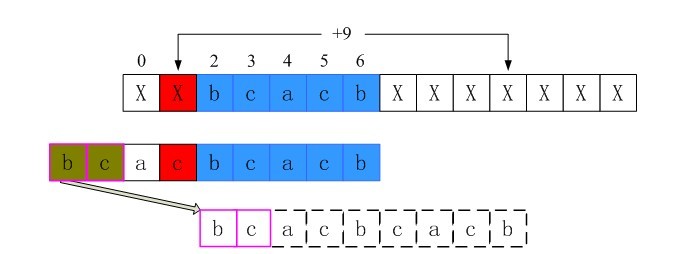
同样的过程可以得到,i = 1时shift[1]也为第三行的长度9。
6、i = 0时不匹配的情况
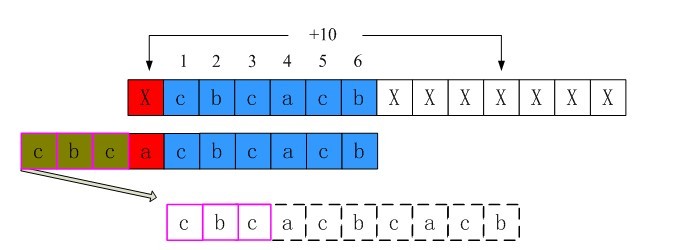
同样的过程可以得到,i = 0时shift[0]也为第三行的长度10。
计算好后缀表数组后,这种情况下的字模式匹配算法为:
- /*! int search_goodsuffix(char const*, int, char const*, int)
- */bref 查找出模式串patn在主串src中第一次出现的位置
- */return patn在src中出现的位置,当src中并没有patn时,返回-1
- */
- int search_goodsuffix(char const* src, int slen, char const* patn, int plen, int* shift)
- {
- int s_idx = plen, p_idx;
- int skip_stride;
- if (plen == 0)
- return -1;
- while (s_idx <= slen)//计算字符串是否匹配到了尽头
- {
- p_idx = plen;
- while (src[--s_idx] == patn[--p_idx])//开始匹配
- {
- //if (s_idx < 0)
- //return -1;
- if (p_idx == 0)
- {
- return s_idx;
- }
- }
- skip_stride = shift[p_idx];
- s_idx += skip_stride +1;
- }
- return -1;
- }
有了前面的三个步骤的算法的基础,BM算法就比较容易理解了,其实BM算法就是将坏字符规则与最好后缀规则的综合具体代码如下,相信一看就会明白。
- /*
- 函数:int* BMSearch(char *, int , char *, int, int *, int *)
- 目的:判断文本串T中是否包含模式串P
- 参数:
- src => 文本串T
- slen => 文本串T长度
- ptrn => 模式串P
- pLen => 模式串P长度
- bad_shift => 坏字符表
- good_shift => 最好后缀表
- 返回:
- int - 1表示匹配失败,否则反回
- */
- int BMSearch(char const*src, int slen, char const*ptrn, int plen, int const*bad_shift, int const*good_shift)
- {
- int s_idx = plen;
- if (plen == 0)
- return 1;
- while (s_idx <= slen)//计算字符串是否匹配到了尽头
- {
- int p_idx = plen, bad_stride, good_stride;
- while (src[--s_idx] == ptrn[--p_idx])//开始匹配
- {
- //if (s_idx < 0)
- //return -1;
- if (p_idx == 0)
- {
- return s_idx;
- }
- }
- // 当匹配失败的时候,向前滑动
- bad_stride = bad_shift[(unsigned char)src[s_idx]]; //根据坏字符规则计算跳跃的距离
- good_stride = good_shift[p_idx]; //根据好后缀规则计算跳跃的距离
- s_idx += ((good_stride > bad_stride) ? good_stride : bad_stride )+1;//取大者
- }
- return -1;
- }















 1962
1962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









