






目录
一、线性回归
1.1线性回归实例
快速入门视频:【五分钟机器学习】机器学习的起点:线性回归Linear Regression_哔哩哔哩_bilibili
【五分钟机器学习】机器学习的起点:线性回归Linear Regression
连锁便利店的店面面积都不大,没有大量储存货品的能力,针对连锁店来说,如果能精确计算出每天的补货量,特别是对一些季节性强的货品进行统一配送,将在节约能源和提高店面使用率上起到很好的作用。“AI 美邻”连锁店打算对夏季冷饮类货品进行精确配送,这个需求需要较好地预测第二天每个连锁店的销售量,而这个预测,当然要依据以往的销售情况,对于冷饮这类季节性强的货品销售量与气温、当地常住人口、店面交通便捷程度等因素都有较大关系。为方便说明和理解,只考虑气温、当地常住人口和店面交通情况因素,通过以往销售数据的记录,整理的到表1-1。
| 序号 | 500m以内 公交站点数 | 气温/ 摄氏度 | 常住人口/ 万 | 销售量/ 件 |
| 1 | 3 | 40 | 6 | 50 |
| 2 | 5 | 34 | 5 | 45 |
| 3 | 3 | 21 | 7 | 36 |
| 4 | 3 | 26 | 6 | 38 |
| 5 | 5 | 7 | 6 | 25 |
| 6 | 6 | 29 | 9 | 49 |
| 7 | 5 | 12 | 6 | 29 |
| 8 | 4 | 39 | 10 | 57 |
| 9 | 4 | 25 | 6 | 39 |
| 10 | 2 | 22 | 7 | 36 |
| 11 | 2 | 19 | 9 | 38 |
| .... | ... | ... | ... | ... |
| 327 | 4 | 35 | 7 | 36 |
| 328 | 4 | 30 | 8 | 44 |
| 329 | 5 | 33 | 10 | 53 |
| 330 | 4 | 20 | 8 | 38 |
| 331 | 2 | 11 | 5 | 24 |
| 332 | 3 | 33 | 8 | 48 |
| 333 | 3 | 27 | 10 | 47 |
| 334 | 5 | 35 | 9 | 53 |
图1-1
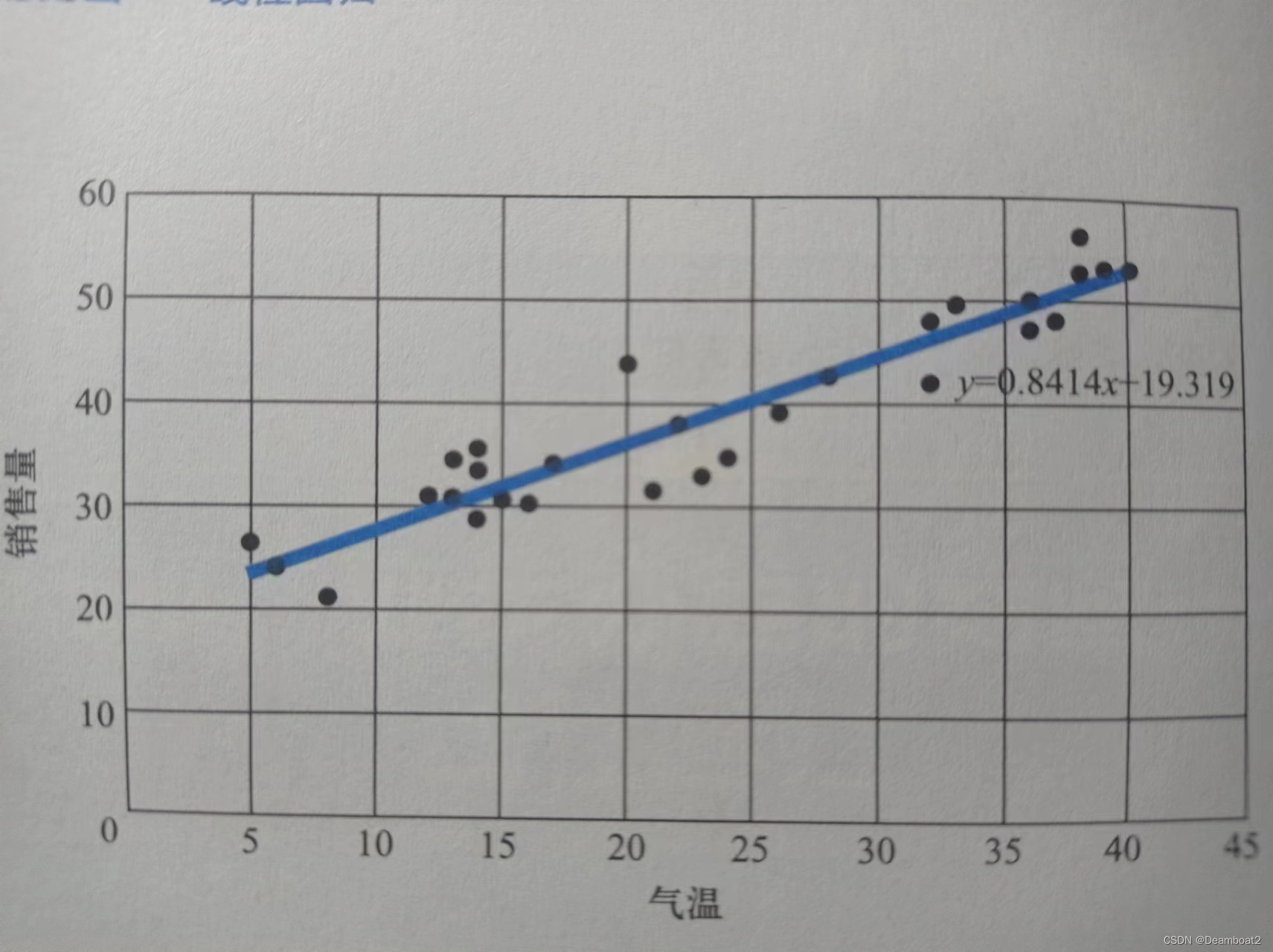
对这些数据,可以先画出图像观察数据的分布,由于以上数据有3个特征和1个结果,不容易在常规的二维或三维图像中观察。为简单起见,先只观察气温和销售量的关系,使用电子表格软件针对表1-1的部分数据制作散点图,并添加趋势线后,如图1-1所示。
可以发现,数据有规律性趋势:随着气温的升高,销售量逐步增大。在电子表格中很容易对“趋势线”添加方程,如在图1-1中,趋势线的方程是y=0.8414x+19.319。很明显,这是一个我们所熟悉的线性方程,表达了气温和销售量的关系其中x是气温,y是销售数量。但是,在实际问题中,数据还有公交站数量和常住人口两个特征,很显然,这些特征也会影响销售量。考虑已有的线性方程,可以将车站数量和人口的影响也用乘系数的形式添加到已有方程中,那么方程将是以形式:
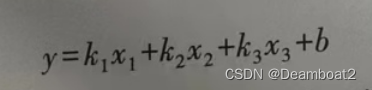
1.2求解模型
首先,需要准备“数据”,由于数据量增大,本案例采用更有效率的方法处理数据。
一般应用中,为便于程序读取,可以利用电子表格软件将训练集和测试集分别保存为不同的文件。在本例中,训练集和测试集文件将都使用CSV格式保存。
代码如下:
#-*-coding:utf-8-*-
import numpy as np
from sklearn import linear_model as lnrmd
table = np.loadtxt( "ddcre.csv",delimiter=",")
x=table[:,0:3]
y=table[:,3]
regr = lnrmd.LinearRegression()
regr.fit(x,y)
#查看模型
print ( "w: ",regr.coef_)
print ("b: ",regr.intercept_)
table = np. loadtxt ("ddtest, csv",delimiter ="," )
T_x=table[:,0:3]
T_y= table[:,3]
print(regr.score(Test_x,Test_y))输出:
w:[0.90120 0.7998 1.8962]
b: 3.5408w和b就是求得的模型的关键参数。
为了测试模型是否正确,需要进行模型测试,观察预测销售量模型在测试集数据上的表现。代码如下:
table=np.loadtxt("ddtest.csv", delimiter= ",")
T_x=table[:,0:3]
T_y=table[:,3]
print(regr.score(Test_x,Test_y))这时程序输出0.98,在回归类预测中该数据越接近1,表示预测的优度越好,它被称为区R2(R…),也称为决定系数。求出的模型的决定系数越高,说明。应遗好、若在测试集上求出的决定系数较低,则就是“欠拟合”(训练过程不充分)。
这时可区将新的公交站点情况、气温、常住人口等数据输人模型,即可得的销量,代码只有如下1行:
print(regr.predict([[5,22,8]])) 得出的结论类似:[40.81164493],即在气温为22℃、附近有5个公交站点、常住人口为8万的时候,销售量大约是41件。
利用这样的模型,连锁店就可以决定第二天的送货量了。
1.3表达拟合结果和趋势
选择算法前,希望看到数据的分布,完成回归后,更希望直观地看到预测的趋这些都需要绘图解决。除了第4章所提到的基本绘图方法,读者还需要开发图像的表“能力”。
一般平面图像,通常标以x轴和y轴,只能表达两个量之间的关系,如图1-1示,这种平面图称为“二维图像”,通常只能表达一个特征与结果间的关系。可以着扩展一下表示效果,例如绘制散点图时,用x轴表达气温特征,用y轴表达人口征,然后用点的颜色灰度表达销售量,甚至再用点的大小和形状表达公交站的数量。如,下面程序:
import numpy as np
import matplotlib.pyplot as plt
table = np.loadbxt ( "fig31.csv" ,delimiter = "," )
cm= plt.cm.get_emap('Greys')
plt.seatler( rable[:,1],table[:,2],c=table[:,3],
s=table[:,0]*10,cmap=cm)
plt.show()程序运行结果如图1-2所示:
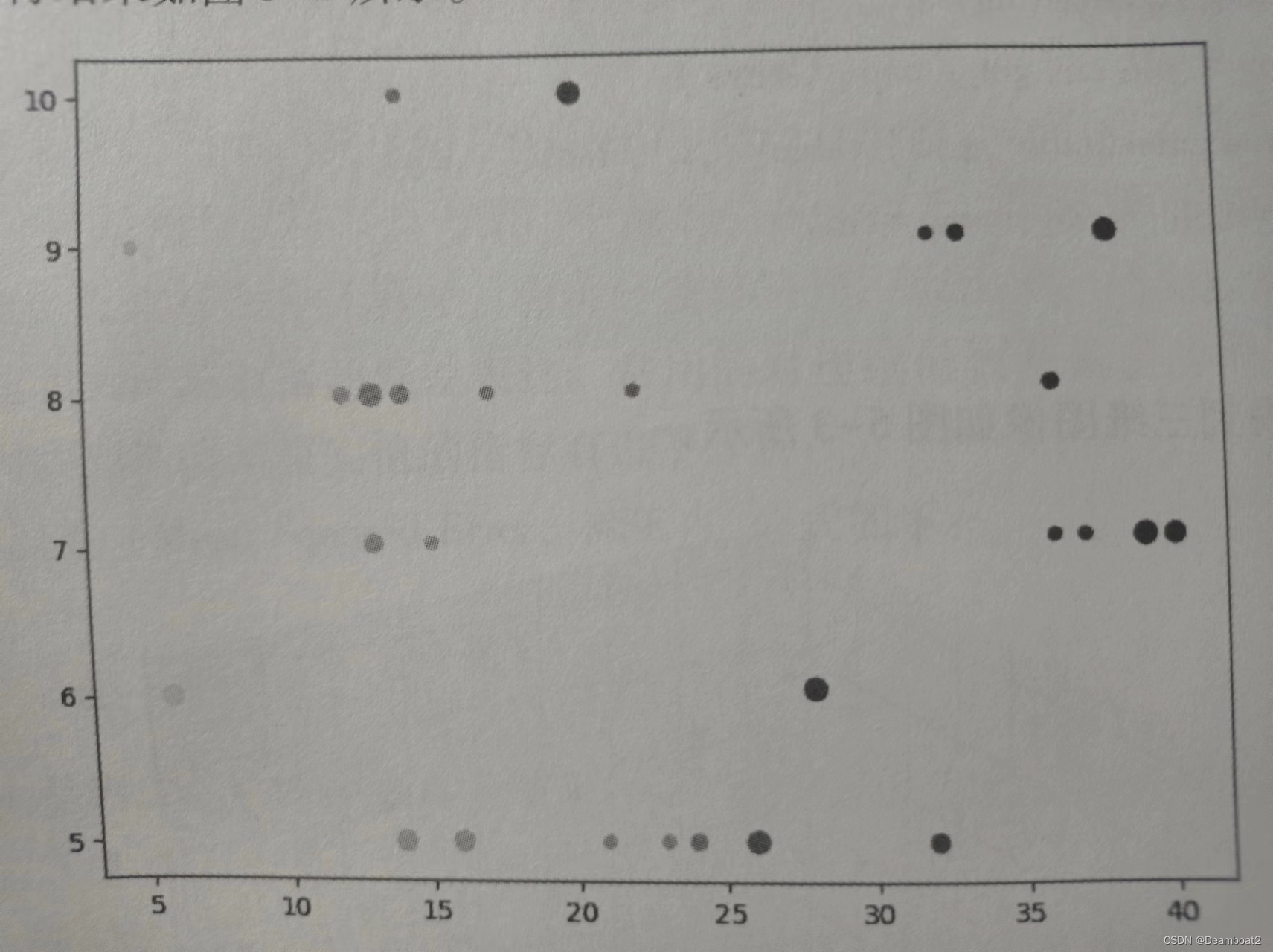
图 1-2 气温、人口、销售量与公交站的趋势图
程序第3行用 numpy 的loadtxt 函数获取数据后,第4行先用cm=plt.cm. get_cmap(Greys')产生灰度表,然后用语句 plt. scatter(table[:,1],table[:,2],c= table[:,3]s=table[:,0]*10,cmap=cm)直接绘图。
本程序在使用scatter函数时,将数据集的第1列和第2列数据(气温和人口)分别映射到了x轴和y轴,c参数可以单独使用,也可以和cmap联合运用,如果cmap先定一种颜色系,则c列表内的数字代表是该颜色系内的颜色,c=table[:,3]就是救数据集的数量与灰度对应。s参数是指定点标记的绘制直径,本程序利用s=table:,0]将车站数目映射其中,由于数值较小不易观察,所以这里将直径放大10倍显示。
通过上面程序,读者已经彻底挖掘了二维图像的表达能力,但即使这样,在多个表达方面,图像表达的效果确实不能达到图1-1那种“一目了然”的程度。
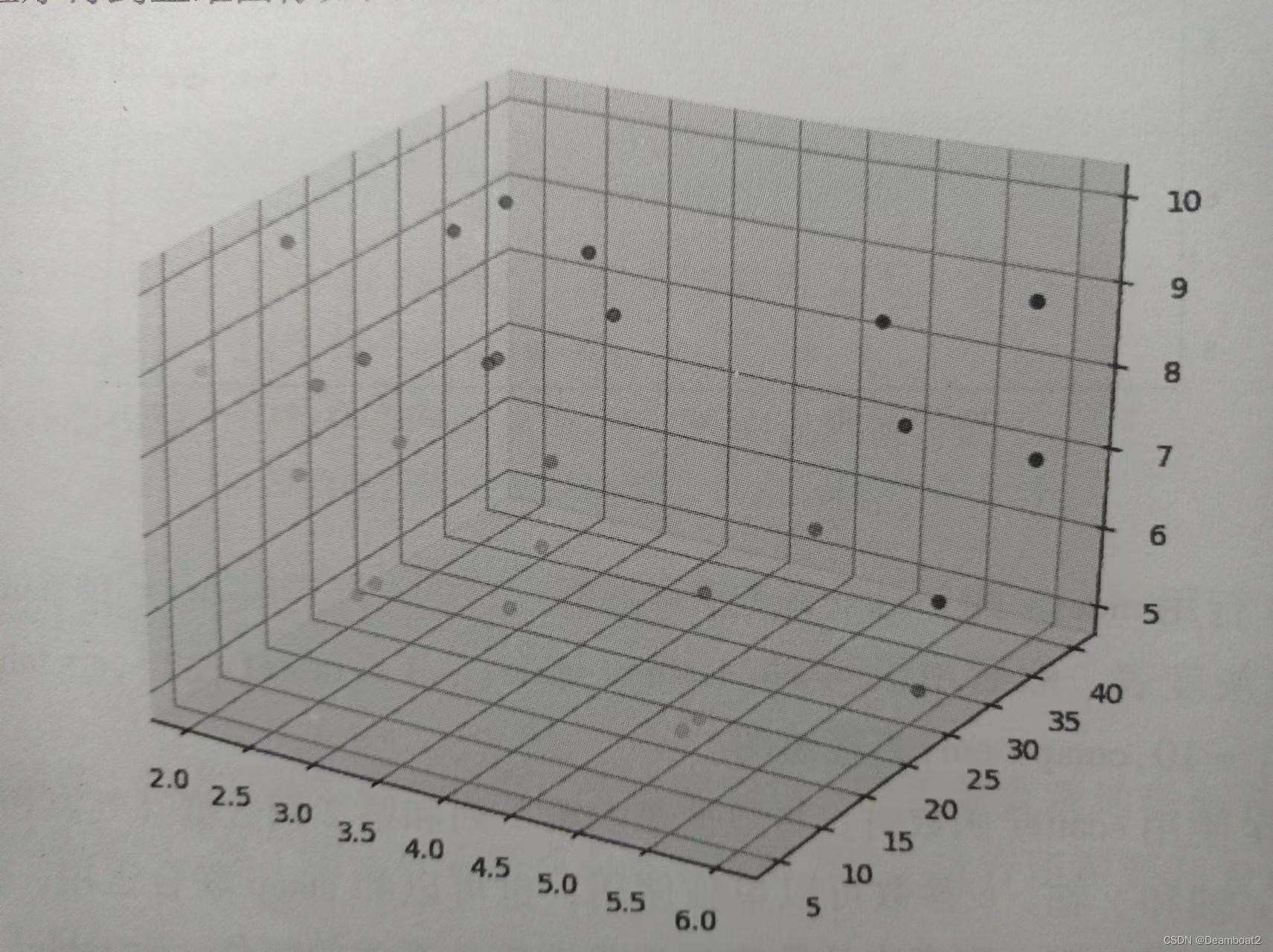
下面还可以尝试用一个三维坐标表达表1-1中的车站数量、气温和人口3个特征,照的颜色灰度表达销售量。程序如下:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
able =np.loadoxt ("fg3l.csv",delimiter= ",")
Ãg=plt.igure( )
ax=Axes3D(fig)
cm = pll.cm.get_cmap( 'Greys')ax.scatter(table[:,0 ,table[:,1],table[:,2 ],
c=table[:,3],cmap=cm)
plt.show( )该程序得到三维图像如图1-3所示:
 1.4模型的可用性度量
1.4模型的可用性度量
在回归类预测中该系数越接近1,表示预测的优度越好,原能本章之前的算法皆为分类算法,评价分类算法使用准确率,而对回归算法,优良酸由预测值和测试集数据的偏差表达。常用的对连续值预测偏差的测量方法共有4其中只考察预测值与真实值的指标有以下3种:
①均方误差(Mean Squared Error,MSE)
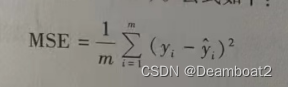
其中, 是测试集上的预留真实结果,
是测试集上的预留真实结果, 是模型的预测值。可以看到均方误差与方差一致。
是模型的预测值。可以看到均方误差与方差一致。
②均方根误差(Root Mean Squard Error,RMSE)。公式如下:
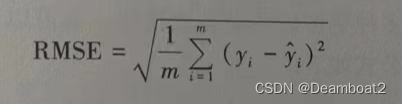
可以看出,RMSE如其英文原意一样,是MSE的算术平方根,而且它与标准差一致。
③平均绝对误差(Mean Absolute Error,MAE)。公式如下:
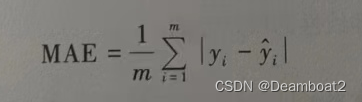
整体误差程度的测量不能出现因误差的“正负”值相互抵消而减少误差数值“总和”的情况,所以前面MSE、RMSE两个指标利用平方运算去掉正负号,那么很自然MAE直接使用绝对值运算去除正负号。从这点考虑,前3个指标都只考虑测试集的预镇实结果,和模型的预测值之之间的差,显而易见,这3个指标越大误差越大,但她于这3个指标不足以说明总体误差趋势,于是又引人了R-Squared 和 Adjusted R-quared 衡量指标。
R-Squared 公式如下:
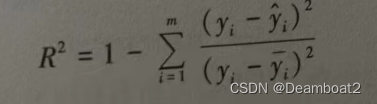
可以看出,R的取值范围是[0,1],一般来说,R-Squared 越大,表示模型拟合媒越好。F反映的是大概有多准。因为,随着样本数量的增加,必然增加,无法真正定量说明准确程度,只能大概定量。于是,可以对R再加工一下,升级成为Adjusted R-Square 公式:

其中,n是样本数量,p是特征数量。AdjustedR-Square抵消样本数量对R-Square 的影响,取值范围还是[0,1],且越大越好。
1.3直接调用的r2_score(y_test,y_predict)是R-Squared,如果需要更精确的衡量可使用以下代码:
Ar=1-((n-1)*(1-r2_score(y_test,y_predict)))/(n-p-1)
其中,y_test是测试样本集,y_predict算法的预测结果集。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









