







Redis事务控制
1,概念:
redis事务就是一个命令执行的队列,将一系列预定义命令包装成一个整体(一个队列)。当执行时,一次性按照添加顺序依次执行,中间不会被打断或者干扰。一个队列中,一次性、顺序性、排他性的执行一系列命令
2,事务基本操作
开启事务:
multi
作用: 设定事务的开启位置,次指令执行后,后续的所有指定都加入到当前事务中。
执行事务:
exec
作用: 设置事务的结束位置,同时执行事务,exec必须与multi成对使用。在exec和multi之间的命令只是存在了一个任务队列中,实际并没有执行,只有执行了exec命令后,队列中的命令才会顺序执行
取消事务:
discard
作用: 终止当前事务的定义,发生在multi和exec之前。如果取消了事务之后再执行exec,则会报错:(error) ERR EXEC without MULTI
Redis缓存淘汰策略
redis默认的最大内存(maxmemory)设置为0,相当于基于物理内存的最大值。
# redis maxmemory 动态设置及查看命令示例
# 动态修改 maxmemory
config set maxmemory 10GB
# 查看 maxmemory
config get maxmemory
info memory | grep maxmemory
redis-cli -h 127.0.01 -p 6379 config get maxmemory
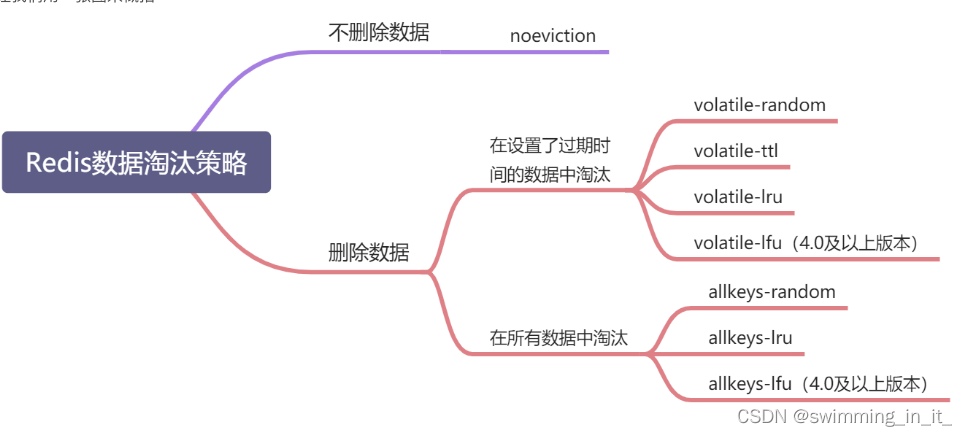
1,八大淘汰策略
| 项目 | Value |
|---|---|
| noeviction | 默认策略,不淘汰数据,大部分写命令都将返回错误(DEL除外) |
| allkeys-lru | 从所有的数据中根据LRU算法挑出数据进行淘汰 |
| volatile-lru | 从设置了过期时间的数据中根据LRU算法淘汰数据 |
| allkeys-random | 从所有的数据中随机挑选数据淘汰 |
| volatile-random | 从设置了过期时间的数据中随机淘汰数据 |
| volatile-ttl | 从设置了过期时间的数据中,挑选越早过期的数据进行删除 |
| allkeys-lfu | 从所有的数据中根据LFU算法挑选数据淘汰(4.0>=版本可用) |
| volatile-ifu | 从设置了过期时间的数据中根据LFU算法挑选数据淘汰(4.0>=版本可用) |
一张图概括:
2,主要算法
- LRU:最近最少使用的key,根据时间,最不常用的淘汰。
- LFU:最近最少使用的key,根据计数器,用的次数少的key淘汰。
- Random:随机淘汰。
- TTL:快要过期的先淘汰。
Redis持久化
一:Redis持久化的实现方式
1,Redis持久化是什么?
因为Redis是基于内存的数据库,一旦断电,所有的实例都会关机,因此所有的数据也会丢失,在运行期间,可以通过开启Redis持久化功能,将数据写入磁盘,供实例重启的时候,恢复数据。Redis持久化主要是通过AOF和RDB实现。
2,AOF是什么?
AOF持久化主要是在Redis修改相关的命令执行后,将执行命令添加到aof_buf缓存区(aof_buf是Redis中的SDS结构,可以理解为C语言中的字符串扩展)的末尾,然后在每次事件循环结束后,根据appendfsycn的配置(always是每次事件循环后都将aof_buf内的数据写入,everysec是每秒写入,no是根据操作系统来决定何时写入),判断是否将aof_buf写入到AOF文件。生产环境一般默认配置是:everysec。
struct redisServer {
/* AOF buffer, written before entering the event loop */
sds aof_buf;//aof_buf缓冲区其实就是Redis的一个简单动态字符串
}
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
事件循环可参考:https://blog.csdn.net/MOU_IT/article/details/115430555
3,RDB是什么?
概念:
RDB是在满足一定的触发条件时(在一个时间间隔内修改命令达到一定数据 | 手动执行SAVE和BGSAVE命令),Redis对数据库内的所有键值对信息生成一个压缩文件dump.rdb,如果dump.rdb已经存在,则用新的替换旧的。Redis默认情况下,RDB开启,AOF关闭。
实现原理:
实现原理是fork一个子进程,然后对键值对进行遍历,生成rdb文件,在生成过程中,父进程会继续处理客户端发送的请求,当父进程要对数据进行修改时,会对相关的内存页进行拷贝,修改的是拷贝后的数据。(也就是COPY ON WRITE,写时复制技术,就是当多个调用者同时请求同一个资源,如内存或磁盘上的数据存储,他们会共用同一个指向资源的指针,指向相同的资源,只有当一个调用者试图修改资源的内容时,系统才会真正复制一份专用副本给这个调用者,其他调用者还是使用最初的资源,在CopyOnWriteArrayList的实现中,也有用到,添加或者插入一个新元素时过程是,加锁,对原数组
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









