







一 ES初识
1.1 概述
ElasticSearch:是基于 Lucene 的 Restful 的分布式实时全文搜索引擎,每个字段都被索引并可被搜索,可以快速存储、搜索、分析海量的数据。是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana
- E:EalsticSearch 搜索和分析的功能。
- L:Logstach 搜集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统。
- K:Kibana 数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台
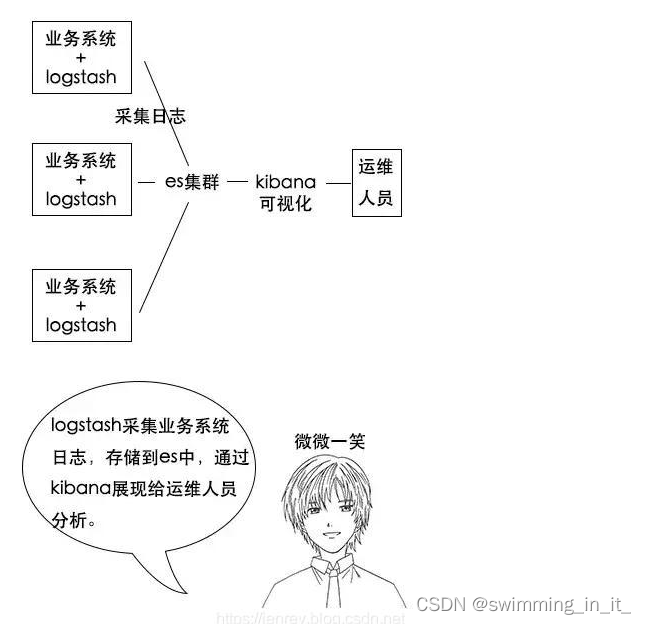
分析日志的用处:假如一个分布式系统有 1000 台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,是不是非常麻烦?
但是如果日志接入了 ELK 系统就不一样。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入 ELK 系统中,我们直接在 Kibana 就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。
这都依赖ES强大的反向索引功能,这样我们根据关键字就能查询到关键的错误日志了。
ES官网:https://www.elastic.co/cn/elasticsearch/
1.2 ES由来
在上一篇文章中搜索实现之lucene中讲述了lunece和es的关系,下面就再说说两个直接的联系吧。
Lucene有两个难以解决的问题:
- 数据越大,存不下来,那我就需要多台服务器存数据,那么我的Lucene不支持分布式的,那就需要安装多个Lucene然后通过代码来合并搜索结果。这样很不好
- 数据要考虑安全性,一台服务器挂了,那么上面的数据不就消失了。
ES就是分布式的集群,每一个节点其实就是Lucene,当用户搜索的时候,会随机挑一台,然后这台机器自己知道数据在哪,不用我们管这些底层。
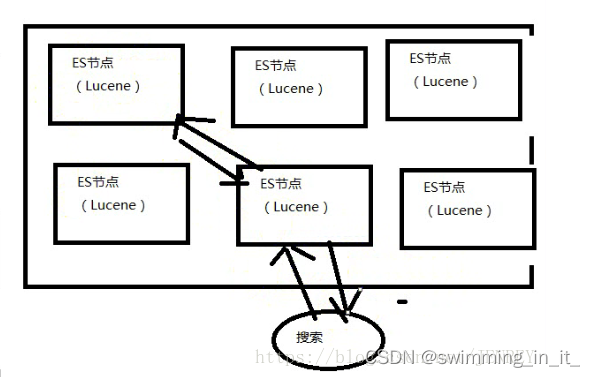
ES的优点:
- 分布式的功能
- 数据高可用,集群高可用
- API更简单和更高级。
- 支持的语言很多
- 支持PB级别的数据
- 完成搜索的功能和分析功能
- 基于Lucene,隐藏了Lucene的复杂性,提供简单的API
ES的性能比HBase高,咱们的竞价引擎最后还是要存到ES中的。
二 ES概念,安装和使用
2.1 基本概念
1,NRT(Near RealTime) 近实时。

2,Cluster集群
ES是一个分布式的系统,且ES直接解压不需要配置就可以使用,在hadoop1上解压一个ES,在hadoop2上解压了一个ES,接下来把这两个ES启动起来。他们就构成了一个集群。
在ES里面默认有一个配置,clustername 默认值就是ElasticSearch,如果这个值是一样的就属于同一个集群,不一样的值就是不一样的集群。
集群中的每一台服务器就是Node节点。
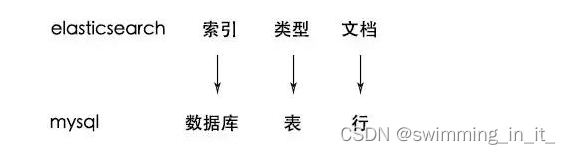
3,index 索引(索引库)
我们为什么使用ES?因为想把数据存进去,然后再查询出来。我们在使用Mysql或者Oracle的时候,为了区分数据,我们会建立不同的数据库,库下面还有表的。其实ES功能就像一个关系型数据库,在这个数据库我们可以往里面添加数据,查询数据。
ES中的索引非传统索引的含义,ES中的索引是存放数据的地方,是ES中的一个概念词汇。index类似于我们Mysql里面的一个数据库 create database user; 好比就是一个索引库
4,type类型
类型是用来定义数据结构的。在每一个index下面,可以有一个或者多个type,好比数据库里面的一张表。相当于表结构的描述,描述每个字段的类型。
5,document
文档就是最终的数据了,可以认为一个文档就是一条记录。是ES里面最小的数据单元,就好比表里面的一条数据
6,Field字段
好比关系型数据库中列的概念,一个document有一个或者多个field组成。
例如:
- 朝阳区:一个Mysql数据库
- 房子:create database chaoyaninfo
- 房间:create table people
7,shard:分片
一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面
8,replica:副本
一个分布式的集群,难免会有一台或者多台服务器宕机,如果我们没有副本这个概念。就会造成我们的shard发生故障,无法提供正常服务。我们为了保证数据的安全,我们引入了replica的概念,跟hdfs里面的概念是一个意思。可以保证我们数据的安全。
在ES集群中,我们一模一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)
当我们去查询数据的时候,我们数据是有备份的,它会同时发出命令让我们有数据的机器去查询结果,最后谁的查询结果快,我们就要谁的数据(这个不需要我们去控制,它内部就自己控制了)
9,总结
在默认情况下,我们创建一个库的时候,默认会帮我们创建5个主分片(primary shrad)和5个副分片(replica shard),所以说正常情况下是有10个分片的。
同一个节点上面,副本和主分片是一定不会在一台机器上面的,就是拥有相同数据的分片,是不会在同一个节点上面的。
所以当你有一个节点的时候,这个分片是不会把副本存在这仅有的一个节点上的,当你新加入了一台节点,ES会自动的给你在新机器上创建一个之前分片的副本。
10,举例
比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫 Poems 的索引,然后创建一个名叫 Poem 的类型,类型是通过 Mapping 来定义每个字段的类型。
比如诗题、作者、朝代都是 Keyword 类型,诗内容是 Text 类型,而字数是 Integer 类型,最后就是把数据组织成 Json 格式存放进去了。

Keyword 类型是不会分词的,直接根据字符串内容建立反向索引,Text 类型在存入 Elasticsearch 的时候,会先分词,然后根据分词后的内容建立反向索引。

2.2 安装
咱们如果想很爽的使用ES,需要安装3个东西:ES、Kibana、ElasticSearch Head。通过Kibana可以对ES进行便捷的可视化操作,通过ElasticSearch Head可以查看ES的状态及数据,可以理解为ES的图形化界面。
2.2.1 安装ES和Kibana
首先开始安装ES、Kibana,同时安装这两个加启动,一共需要3步,3行代码搞定:
1,搜索docker镜像库里可用的ES镜像:可以看到,stars排名第一的是官方的ES镜像,第二是大牛已经融合了ES7.7和Kibana7.7的镜像,那咱们就用第二个了。
docker search elasticsearch
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 607
607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









