







首先,对于MySQL层优化我一般遵从五个原则∶
- 减少数据访问:设置合理的字段类型,启用压缩,通过索引访问等减少磁盘IO;
- 返回更少的数据:只返回需要的字段和数据分页处理减少磁盘io及网络io ;
- 减少交互次数:批量DML操作,函数存储等减少数据连接次数;
- 减少服务器CPU开销:尽量减少数据库排序操作以及全表查询,减少cpu内存占用;
- 利用更多资源:使用表分区,可以增加并行操作,更大限度利用cpu资源。
总结到SQL优化中,就三点:
- 最大化利用索引
- 尽可能避免全表扫描
- 减少无效数据的查询
理解SQL优化原理,首先要搞清楚SQL执行顺序:
SELECT语句-语法顺序:
- SELECT
- DISTINCT <select_list>
- FROM<left_table>
- <join_type> JOIN <right_table>
- ON <join_condition>
- WHERE<where_condition>
- GROUP BY <group_by_list>
- HAVING<having_condition>
- ORDER BY <order_by_condition>
- LIMIT<limit_number>
SELECT语句-执行顺序:
- FROM<表名>#选取表,将多个表数据通过笛卡尔积变成一个表。
- ON<筛选条件>#对笛卡尔积的虚表进行筛选
- JOIN<join, left join, right join...>
- <join表>#指定join,用于添加数据到on之后的虚表中,例如leftjoin会将左表的剩余数据添加到虚表中
- WHERE<where条件>#对上述虚表进行筛选
- GROUP BY<分组条件>#分组
- <SUM()等聚合函数>#用于having子句进行判断,在书写上这类聚合函数是写在having判断里面的
- HAVING<分组筛选>#对分组后的结果进行聚合筛选
- SELECT<返回数据列表>#返回的单列必须在group by子句中,聚合函数除外
- DISTINCT数据除重
- ORDER BY<排序条件>#排序
- LIMIT<行数限制>
SQL优化策略
声明:以下SQL优化策略适用于数据量较大的场景下,如果数据量较小,没必要以此为准,以免 画蛇添足。
一、避免不走索引的场景
1. 尽量避免在字段开头模糊查询,会导致数据库引擎放弃索引进行全表扫描。如下∶

优化方式∶尽量在字段后面使用模糊查询。如下∶

如果需求是要在前面使用模糊查询
- 使用MySQL内置函数INSTR(str;substr)来匹配,作用类似于java中的indexOf)
- 使用FullText全文索引,用match against检索
- 数据量较大的情况,建议引用ElasticSearch、solr,亿级数据量检索速度秒级
- 当表数据量较少(几千条儿那种),别整花里胡哨的,直接用like 'Xxx%'。
2. 尽量避免使用in和notin,会导致引擎走全表扫描。如下∶

优化方式∶如果是连续数值,可以用between代替。如下∶

如果是子查询,可以用exists代替。详情见《MySql中如何用exists代替in》如下∶

3. 尽量避免使用or,会导致数据库引擎放弃索引进行全表扫描。如下∶

优化方式∶可以用union代替or。如下∶

4. 尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描。如下:

优化方式∶可以给字段添加默认值0,对O值进行判断。如下∶

5. 尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进 行全表扫描。
可以将表达式、函数操作移动到等号右侧。如下∶

6. 当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用 该条件,数据库引擎会放弃索引进行全表扫描。如下∶

优化方式∶用代码拼装sql时进行判断,没 where条件就去掉 where,有where条件就加 and。
7. 查询条件不能用<>或者!=
使用索引列作为条件进行查询时,需要避免使用<>或者!=等判断条件。如确实业务需要, 使用到不等于符号,需要在重新评估索引建立,避免在此字段上建立索引,改由查询条件中 其他索引字段代替。
8. where条件仅包含复合索引非前置列
如下∶复合(联合)索引包含key_part1,key_part2,key_part3三列,但SQL语句没有 包含索引前置列"key_part1",按照MySQL联合索引的最左匹配原则,不会走联合索引。

9. 隐式类型转换造成不使用索引
如下SQL语句由于索引对列类型为varchar,但给定的值为数值,涉及隐式类型转换, 造成不能正确走索引。

10. order by条件要与where中条件一致,否则order by不会利用索引进行排序
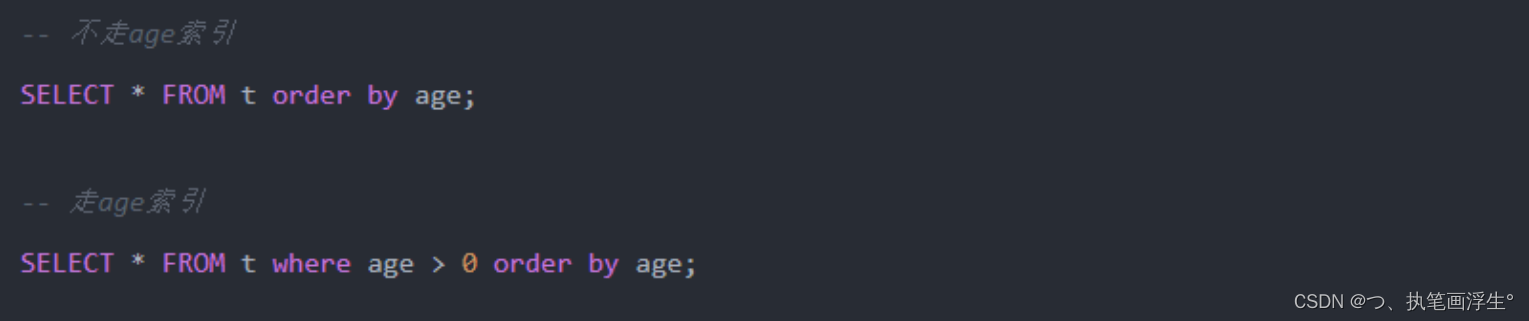
对于上面的语句,数据库的处理顺序是
- 第一步∶根据where条件和统计信息生成执行计划,得到数据。
- 第二步∶将得到的数据排序。当执行处理数据(order by)时,数据库会先查看第一步的执行计划,看order by的字段是否在执行计划中利用了索引。如果是,则可以利用索引顺序而直接取得已经排好序的数据。如果不是,则重新进行排序操作。
- 第三步返回排序后的数据。
当order by 中的字段出现在where条件中时,才会利用索引而不再二次排序,更准确的 说,order by中的字段在执行计划中利用了索引时,不用排序操作。
这个结论不仅对order by有效,对其他需要排序的操作也有效。比如group by、union、 distinct等。
11. 正确使用hint优化语句
MySQL中可以使用hint指定优化器在执行时选择或忽略特定的索引。一般而言,处于 版本变更带来的表结构索引变化,更建议避免使用hint,而是通过Analyze table多收集统计 信息。但在特定场合下,指定hint可以排除其他索引干扰而指定更优的执行计划。
- USE INDEX在你查询语句中表名的后面,添加 USE INDEX来提供希望 MySQL去参考的索引列表,就可以让MySQL不再考虑其他可用的索引。例子∶SELECT col1 FROM table USE INDEX(mod_time, name)...
- IGNOREINDEX如果只是单纯的想让MySQL忽略一个或者多个索引,可以使用IGNORE INDEX作为Hint。例子∶SELECT col1 FROM table IGNOREINDEX(priority)…
- FORCEINDEX为强制MySQL使用一个特定的索引,可在查询中使用FORCEINDEX作为Hint。例子∶SELECT col1 FROM table FORCE INDEX(mod_time)..
在查询的时候,数据库系统会自动分析查询语句,并选择一个最合适的索引。但是很多 时候,数据库系统的查询优化器并不一定总是能使用最优索引。如果我们知道如何选择索 引,可以使用FORCE INDEX强制查询使用指定的索引。
例如:

二、SELECT语句其他优化
1. 避免出现select *
首先,select*操作在任何类型数据库中都不是一个好的SQL编写习惯。
使用select*取出全部列,会让优化器无法完成索引覆盖扫描这类优化,会影响优化器对执行计划的选择,也会增加网络带宽消耗,更会带来额外的I/O,内存和CPU消耗。
建议提出业务实际需要的列数,将指定列名以取代select*
2. 避免出现不确定结果的函数
特定针对主从复制这类业务场景。由于原理上从库复制的是主库执行的语句,使用如now()、rand()、sysdate()、current_user()等不确定结果的函数很容易导致主库与从库相应的数据不一致。另外不确定值的函数,产生的SQL语句无法利用query cache。
3.多表关联查询时,小表在前,大表在后。
在MySQL中,执行 from 后的表关联查询是从左往右执行的(Oracle相反),第一张表会涉及到全表扫描,所以将小表放在前面,先扫小表,扫描快效率较高,在扫描后面的大表,或许只扫描大表的前100行就符合返回条件并return了。
例如:表1有50条数据,表2有30亿条数据;如果全表扫描表2,你品,那就先去吃个饭再说吧是吧。
4. 使用表的别名
当在SQL语句中连接多个表时,请使用表的别名并把别名前缀于每个列名上。这样就可以减少解析的时间并减少哪些友列名歧义引起的语法错误。
5. 用where字句替换HAVING字句
避免使用HAVING字句,因为HAVING只会在检索出所有记录之后才对结果集进行过滤,而where则是在聚合前刷选记录,如果能通过where字句限制记录的数目,那就能减少这方面的开销。HAVING中的条件一般用于聚合函数的过滤,除此之外,应该将条件写在where字句中。where和having的区别:where后面不能使用组函数
6. 调整Where字句中的连接顺序
MySQL采用从左往右,自上而下的顺序解析where子句。根据这个原理,应将过滤数据多的条件往前放,最快速度缩小结果集。
三、增删改 DML 语句优化
待补充。。。
四、查询条件优化
待补充。。。
五、建表优化
- 在表中建立索引,优先考虑where、order by使用到的字段。
- 尽量使用数字型字段(如性别,男:1 女:2),若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
- 查询数据量大的表 会造成查询缓慢。主要的原因是扫描行数过多。这个时候可以通过程序,分段分页进行查询,循环遍历,将结果合并处理进行展示。要查询100000到100050的数据,如下:

- 用varchar/nvarchar 代替 char/nchar
尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以 节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。不要以 为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入 值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。
全文参考链接:https://javaforall.cn/125732.html
原文链接:https://javaforall.cn















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









