







 提出一种新的视觉问答(VQA)方法,能从图像中选择与问题相关的区域,通过映射文本和视觉特征到共享空间来确定相关性。适用于需精确定位答案的问题。
提出一种新的视觉问答(VQA)方法,能从图像中选择与问题相关的区域,通过映射文本和视觉特征到共享空间来确定相关性。适用于需精确定位答案的问题。
1、abstract
我们提出了一种通过选择与基于文本的查询相关的图像区域来学习回答视觉问题的方法,我们的方法将来自不同区域的文本查询和视觉特征映射到共享空间与模态内部的相关性进行比较。在视觉问答中,比如“什么颜色”,这需要计算一个具体的局部位置,比如“什么样的房间”,需要选择性的识别图像区域信息。我们的方法在这些方面取得了重要的进展。我们的模型还在VAQ数据集上进行了测试。
2、Introduction
视觉问答(VQA)是回答关于图像的自然语言问题的任务。VQA包括语言表达和语言基础、语言识别、常识推理、计数和阅读等专业任务。在这篇论文中,我们主要关注VQA和其他视觉推理任务的一个关键问题:知道往哪里看。如图1所示。很容易回答“步行灯是什么颜色的?”如果灯泡是局部的,在回答是否下雨时,可以通过识别雨伞、水坑或多云的天空来处理。我们想要学习在哪里寻找回答问题监督只有图像和问题/回答对。例如,如果我们有几个训练的例子,“现在是什么时间?”或类似的问题,系统应该了解什么样的答案是期望的,它应该在图像的哪里作出回应。
从问题-图像对中学习从哪里看有很多挑战。诸如“这是什么运动?”使用完整的图像可能是最好的回答。其他的问题还有“沙发上是什么?”或“这个女人的衬衫是什么颜色的?”要求重点关注特定区域。还有一些是“这个标志说什么?”需要专业知识或推理,我们不期望达到。系统需要学习识别物体,推断空间关系,确定相关性,找到自然语言和视觉特征之间的对应关系。我们的关键思想是学习语言和视觉区域特征的非线性映射到一个共同的潜在空间,以确定相关性。然后,相关区域被用来为一个特定的配对问题打分。潜在嵌入和评分函数联合学习使用基于边际的损失单独监督问答对。
主要贡献如下:
(1)他们提出来一个图像区域选选择机制,学习识别与问题相关的图像区域。
(2)我们提出了一个学习框架来解决基于边际的多选视觉QA的损失。
(3)做出细致的比较,凸显模型的性能。
3.相关工作 略
模型结构图
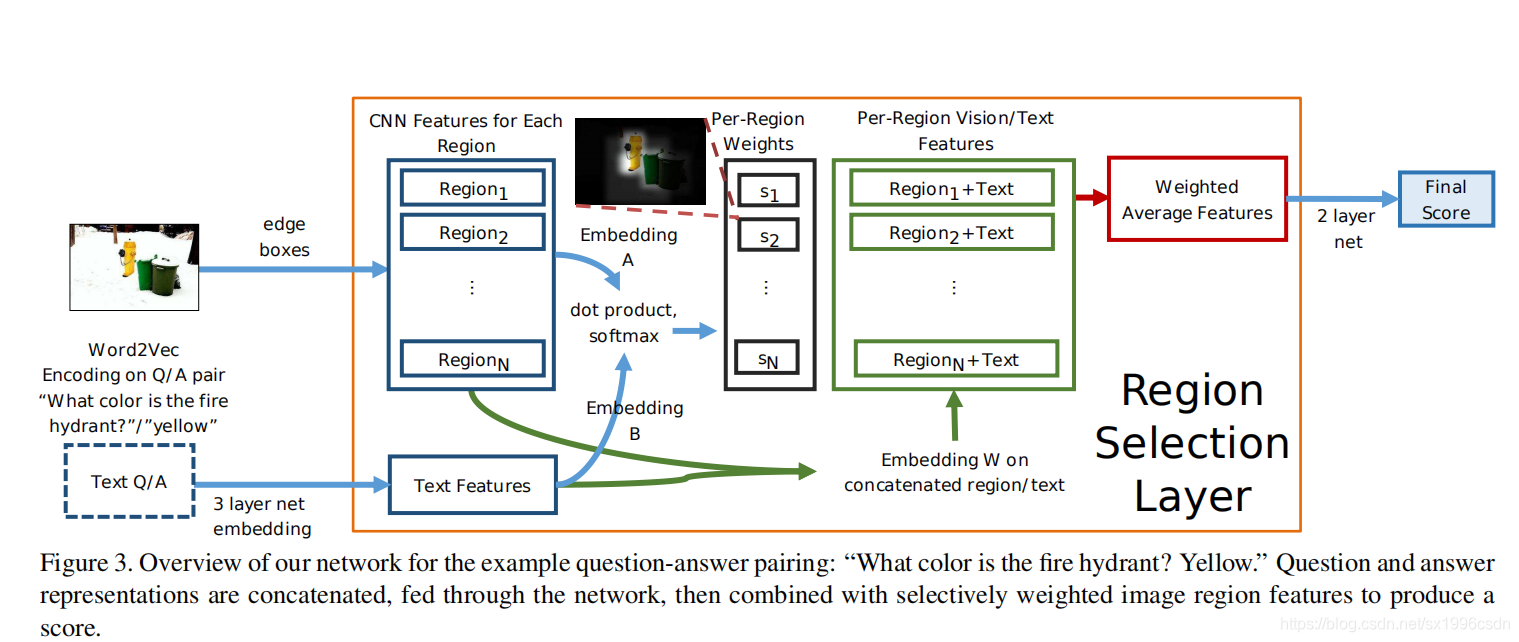
4.Approach
我们的方法学习嵌入文本问题和一组视觉图像区域到一个潜在的空间,内积产生一个相关性加权的每个区域。图3给出了概述。输入的是一个问题,潜在的答案,以及一组自动选择的候选区域的图像特征。我们使用word2vec和一个三层网络对解析后的问题和答案进行编码。每个区域的视觉特征使用训练过的CNN的顶部两层(包括输出层)进行编码ImageNet。然后,语言和视觉特征被嵌入,并与点积进行比较,点积是软最大值,以产生每个区域的相关性加权,使用这些权重,一个连接视觉的加权平均值,语言特征是一个两层网络的输入,输出答题者的可信度。
1.Image features:通过edge boxes(边缘检测)预训练网络得到top99 region,然后全图算第100个region 注意:其中联合重叠阈值设定决定了区域的大小 本task region稍微小点好 作者猜测增加region number可能能够提升性能 用的VGG 取的最后一个隐藏层4096d和前一个softmax层1000d并置共5096d 因为1000那个包含物体类别信息
2.Language representation:首先将每个word通过Google News dataset进行预训练的w2v得到单词representation(相同词有相近的向量特征是open-ended前提)之后通过4个Bin得到四种question sentence representation(而不是LSTM)
Bin1:问题前两个词特征的平均,比如:“多少”往往需要数字来回答,“有吗”需要一个有或者没有来回答
Bin2:主语名词特征
Bin3:其他所有名词特征的平均
Bin4:去掉限定词和冠词之后的剩余词特征的平均
Bin1+Bin2+Bin3+Bin4+answer representation = 1500维 这就是整个的representation
问题特征和图像特征点乘,权重归一化
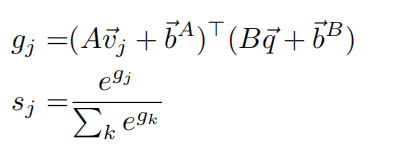
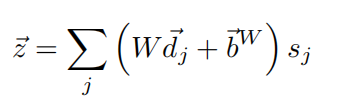
最后的向量z过一个两层的fc后输出一个score 然后利用Hingeloss返回梯度
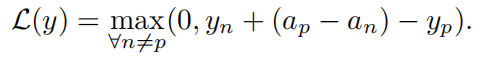
思考:
1. 该方法因为输入要有QA pair 所以只能选择mc类型问题 因为open-ended类型问题没有answer
2. Hinge loss:基于margin的loss 简单来说就是两个结果之间的距离最少要大于一个值margin(此处为正确答案的得分和得分最高的错误答案之间的得分差) loss为这个值与训练时得到的margin值的差
3. 它的灵感来源于caption中的attention 因此之后的灵感发觉可多从其他类似任务考虑
4. 该方法提出了一种新的表征QA的方式:bin5 即从4个方面对Q进行300维的表征 最后接个answer的300维特征 然后concatenation(具体见方法)
5. Edge Boxes方法可获得image region 其中的联合重叠阈值可决定region的大小
6. 相似词有相似的representation是open-ended VQA 的前提 但是对于本文类型的打分网络不需要(因为没有多个词的比较)
7. 点积的前提是两向量维度相等
8. 点积加权啊求和的形式优于取最值salient
9. Vgg最后一个隐藏层是4096维 之前的一个softmax是1000维 含有直接表达类别的信息
10. 取region和不取region的区别在于所有region并不能代表全图;
11. 需要精准定位的问题类型该方法优势较大;需要技术或全局关系的使用全图最好(包含于论文方法中);需要更多先验知识的基于文本更好


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









