







1、原理简单说明
MVCC其实就是使用快照版本来实现的
MySQL底层还有几个隐藏字段,比如类似创建事务id、删除事务id
| id | name | balance | 创建事务id | 删除事务id |
| 1 | zhangsan | 450 | 10 | 13 |
| 2 | wangwu | 600 | 11 | 空 |
| 2 | wangwu888 | 600 | 13 | 空 |
ps-注意:这个时候创建了查询快照,记录执行sql这一刻最大的已提交事务id(快照点已提交最大事务id)
比如现在开启事务,事务id为13,
①、先删除id=1的记录
②、然后更新id=2的记录,
③、再提交对于删除操作。
mysql底层会记录好被删除的数据行的删除事务id,
对于更新操作 mysql底层会新增一行相同数据并记录好对应的创建事务id
在id为12的事务里执行查询操作mysql底层会带上过滤条件,创建事务id <= max(当前事务id(12),快照点已提交最大事务id),删除事务id> max(当前事务id(12),快照点已提交最大事务id)
通俗的讲:对于上表中的数据是这么来的。
①开始事务,插入了name为zhangsan的数据,事务id为10,此时就会记录创建事务id为10,提交事务
②开始事务,插入了name为wangwu的数据,事务id为11,此时就会记录创建事务id为11,提交事务
③开始事务,更新wangwu这条记录为wangwu888。MySQL底层实际上并不是直接修改了最终数据,而是会生成一条新的记录(PS:这里生成新的记录并不是指真的在我们的数据表里面插入一条记录,而是mysql自己维护的,每更新一次就会有一条新数据)。新数据的id和原来数据的id是一样的,也会有一个创建事务的id,此时事务的id为13,所以记录的为13。
接着在该事物中删除name为zhangsan的数据,这个时候就记录删除事务id为13
注意:begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个操作InnoDB 表的语句,事务才真正启动,才会向mysql申请事务id,
mysql内部是严格按照事务的启动顺序来分配事务id的
2、实例执行
MVCC其实主要理解两句话
①、对于删除操作,mysql底层会记录好被删除的数据行的删除事务id,对于更新操作 mysql底层会新增一行相同数据并记录好对应的创建事务id
②、创建事务id <= max(当前事务id(12),快照点已提交最大事务id),删除事务id> max(当前事 务id(12),快照点已提交最大事务id)
比如,现在数据如下:
| id | name | balance | 创建事务id | 删除事务id |
| 1 | zhangsan | 450 | 10 | 空 |
| 2 | wangwu | 600 | 11 | 空 |

mysql底层不会立马更新这条数据,而是会生成一笔新的记录(PS:这里生成新的记录并不是指真的在我们的数据表里面插入一条记录,而是mysql自己维护的,每更新一次就会有一条新数据)。具体数据如下,新纪录会记录当前事务的id为创建事务id
假设当前session申请的事务id为12
| id | name | balance | 创建事务id | 删除事务id |
| 1 | zhangsan | 450 | 10 | 空 |
| 2 | wangwu | 600 | 11 | 空 |
| 2 | wangwu666 | 600 | 12 | 空 |
(2)还是当前事务,继续删除id为1的数据

mysql底层此时并不真正删除数据,而是记录当前数据的删除事务id为当前事务的id,具体数据为下:
| id | name | balance | 创建事务id | 删除事务id |
| 1 | zhangsan | 450 | 10 | 12 |
| 2 | wangwu | 600 | 11 | 空 |
| 2 | wangwu666 | 600 | 12 | 空 |
在同一个事务中,反复select,即便数据库中的值已经改变了,为什么询结果没有改变呢?其实底层是读取的是快照,所以每次结果都一样。
MVCC其实就是使用快照版本来实现的。对于某一条记录,可能会被不同的session修改无数遍,只要有修改,就会在快照中增加一条记录,只是每条记录的创建事务id不同。
(3)回滚之前的操作,重新开启一个事务。
执行查询语句查询数据

上面有提到过begin的时候事务还未真正启动,在执行了查询语句之后变回真正开始事务,mysql会分配一个事务id(假设当前分配的事务id为12)
(4)打开另一个session界面,开启事务,查询数据

(5)手动在数据库中修改数据,然后在session1刚才事务中再次begin,再次进行查询
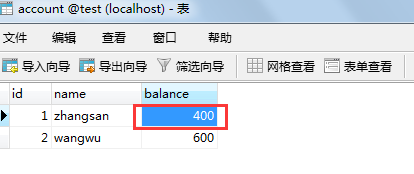

session1中第一个事务查询出来第一条数据的的balance字段为350,修改数据库值后,再次begin,查询出的数据变成了400。
这里可以来理解下第二句话:创建事务id <= max(当前事务id(12),快照点已提交最大事务id),删除事务id> max(当前事 务id(12),快照点已提交最大事务id)
上面假设session1中第一个事务id是12
快照点已提交的最大事务id怎么理解呢?快照点就是begin之后的第一条语句执行的时候,因为这个时候是获取事务id的时候。既然目前session1中对应的事务id为12,session2中的事务id为13,13的事务并没有提交,那么就意味着这个数据库已提交的最大事务id为11(也是假设值,只要是比当前事务id小的值都可以,因为MySQL分配事务id也是有顺序的),所以,max(当前事务id(12),快照点已提交最大事务id)取到的值是12
由于mysql底层在执行查询语句的时候,默认会带两个条件:
select * from account where create_shiwu_id <= 12(当前session的事务id) and del_shiwu_id > 12(当前session的事务id)(伪SQL)
(6)、在session2中删除第一条数据,然后提交事务,最后在session1中查询,查看结果

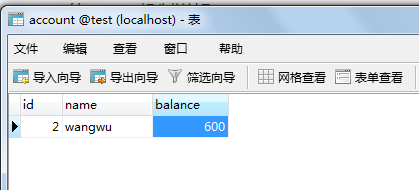
查看数据库,发现数据确实是被删除的,但是在session1中仍然可以被查出来,这个时候事务id就起了很大的作用,
由于mysql底层在执行查询语句的时候,默认会带两个条件:
select * from account where create_shiwu_id <= 12(当前session的事务id) and del_shiwu_id > 12(当前session的事务id)(伪SQL)
session2的事务id是假设是13,根据这条SQL是查询不到数据被删除,所以仍然是可以找到已经删除的数据。
(7)结束session1和session2的事务,然后将数据库的数据还原到最初始的情况
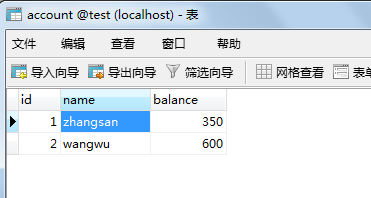

session1中只begin,暂时不查询语句,代表当时并未分配事务id
session2中begin之后,删除数据,然后提交,已经分配好事务id,并且确定了当前数据库已提交的最大事务id为session2的id(假设为13)
那么此时,在session1中再次查询,会有id为1的数据吗??

执行语句之后发现没有数据,查询到的结果也是删除了的。
再来理解下第二句话:
创建事务id <= max(当前事务id(12),快照点已提交最大事务id),删除事务id> max(当前事 务id(12),快照点已提交最大事务id)
上面假设session1中第一个事务id是12
快照点已提交的最大事务id怎么理解呢?快照点就是begin之后的第一条语句执行的时候,因为这个时候是获取事务id的时候。既然目前session1中对应的事务id为12,session2中的事务id为13,13的事务已经提交,那么当在session1中执行查询语句的这个快照点,找到的已提交的最大事务id为13,所以,max(当前事务id(12),快照点已提交最大事务id)取到的值是13
当前事务的id为12,快照点已提交最大事务id为13,那么max(当前事务id(12),快照点已提交最大事务id)取到的值是13,那么最后拼接的条件为:
select * from account where create_shiwu_id <= 13(当前session的事务id) and del_shiwu_id > 13(当前session的事务id)(伪SQL)
所以是拿到了session中提交的事务的,所以查到数据是删除了的。














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









