







这里写目录标题
第一部分
-
k8s与docker的区别
Docker是容器化技术,k8s是一套自动化部署工具,可全生命周期管理Docker容器。(Kubernetes的简称是K8s)
K8S是一个完备的分布式系统支撑平台,具备完善的集群管理能力,多扩多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和发现机制、内建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制以及多粒度的资源配额管理能力。
Docker是一个开源的应用容器引擎,让开发者可以打包它们的应用以及依赖包到-一个可移植的镜像中,然后发布到任何流行的Linux或Windows机器上,也可以实现虚拟化。
Docker使用客户端-服务器架构模式,使用远程API来管理和创建Docker容器。
Docker容 器通过Docker镜像来创建,容器与镜像的关系类似于面向对象编程中的对象与类。 -
类的加载过程
加载-验证-准备-解析-初始化
字长16位的计算机表示数以16位二进制数表示
-
volatile关键字的作用
保证内存可见性和禁止指令重排徐 -
transient关键字,修饰不允许序列化的变量
-
mysql的explain关键字,查看某条sql语句的使用索引情况
-
InputStreamreader的使用
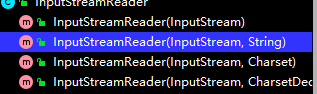
-
try-with-resources语句
try-with-resources语句能够帮你自动调用资源的close()函数关闭资源不用到finally块(为什么使用这个语句块:因为这个语句块可以避免finally语句块抛出的异常导致try语句块的异常被忽略)。
static String readFirstLineFromFile(String path) throws IOException {
try (BufferedReader br = new BufferedReader(new FileReader(path))) {
return br.readLine();
}
}
这是try-with-resources语句的结构,在try关键字后面的( )里new一些需要自动关闭的资源。
- SpringCloud五大组件
1、服务发现Netflix Eureka;
2、客服端负载均衡Netflix Ribbon;
3、断路器Netflix Hystrix;
4、服务网关Netflix Zuul;
5、分布式配置。
https://blog.csdn.net/sinat_24798023/article/details/80239637
springCloud体系中Apollo可以当配置中心
https://www.html.cn/qa/other/21703.html
- 不稳定的排序算法
堆排序、选择排序、希尔排序、快速排序
手写快排?手写堆排序?
- String st = “eijfw”;
st += 1;
System.out.println(st);
会发生强制类型转换,结果是:eijfw1
第二部分
- Spring事务管理方式?
实现方式共有两种:编码方式;声明式事务管理方式。
声明式事务管理又有两种方式:基于XML配置文件的方式;另一个是在业务方法上进行@Transactional注解,将事务规则应用到业务逻辑中。
- 在哪个目录下可以找到Linux常用命令
/bin:bin 就是二进制(binary)英文缩写。在一般的系统当中,都可以在这个目录下找到linux常用的命令。系统所需要的那些命令位于此目录。
https://blog.csdn.net/qq_40369872/article/details/89786771
- //++ --在后先输出值在自增或自减
- //抽象类的子类必须实现抽象类中的所有抽象方法
- LinkedHashSet?
优点是按照插入顺序排列,速度略慢
缺点是非线程安全的 - 在软件术语中,被继承的类一般称为“超类”,也有叫做父类。
- 在 Java 8 中,Integer 缓存池的大小默认为 -128~127
- Object中有哪些方法见我的上一个博客
- 使用slf4j打印异常日志的方法
logger.error(“错误消息:{}”,e.getMessage(),e);
异常信息Exception e 的相关方法:
e.toString():获得异常类型和错误信息描述
e.getMessage():获得错误信息描述
e.printStackTrace():在控制台打印出异常堆栈(异常类型、错误信息描述和出错位置等)。
- CAS操作的忧缺点
优点:效率高,速度快
缺点:消耗CPU太高,只能保证单一变量的原子性不能保证代码块的原子性,ABA问题(版本号解决)
- Map mp; //没有继承Collection接口!
- 在子类构造方法中使用super()显示调用父类的构造方法,super()必须在子类构造方法的第一行,否则编译报错
- 输出结果:3
public static void main(String[] args) {
System.out.println(fun());
}
public static int fun(){
try{
return 1;
}catch(Exception e){
return 2;
}finally {
return 3;
}
}
- 输出结果:2
public class Demo10TestQuotes {
public Demo10TestQuotes() {
}
static void print(ArrayList a1){
a1.add(2);
a1 = new ArrayList();
a1.add(3);
a1.add(4);
}
public static void main(String[] args) {
Demo10TestQuotes demo10TestQuotes = new Demo10TestQuotes();
ArrayList a1 = new ArrayList();
a1.add(1);
print(a1);
System.out.println(a1.get(1));
}
}
- 结果: String对象的特性
You are fired!
You are hired!
String s = " You are hired!";
System.out.println(s.replace('h','f'));
System.out.println(s);
- 局部变量没有默认值。一旦创建了局部变量,我们必须在使用它之前对其进行初始化。
- web应用程序当前用户上下文信息保存在哪个对象
JSP 四大作用域:page(作用范围最小)、request、session、application(作用范围最大)。存储在application对象中的属性可以被同一个WEB应用程序中的所有Servlet和JSP页面访问。(属性作用范围最大)
存储在session对象中的属性可以被属于同一个会话(浏览器打开直到关闭称为一次会话,且在此期间会话不失效)的所有Servlet和JSP页面访问。
存储在request对象中的属性可以被属于同一个请求的所有Servlet和JSP页面访问(在有转发的情况下可以跨页面获取属性值),例如使用PageContext.forward和PageContext.include方法连接起来的多个Servlet和JSP页面。
存储在pageContext对象中的属性仅可以被当前JSP页面的当前响应过程中调用的各个组件访问,例如,正在响应当前请求的JSP页面和它调用的各个自定义标签类。
Boolean b = null; //此时的b是被包装的对象
float f = 3.14f; //末尾必须加f
char c = 'c'; //单引号是char ,双引号是String
- ArrayList可以扩容,但不能说大小容量是动态变化的
https://blog.csdn.net/neweastsun/article/details/115287833
short a = 128; // 0000 0000 1000 0000
byte b = (byte)a; // 1000 0000 此时是负数
System.out.println(a); //128
System.out.println(b); //-128
- Java中NIO中类的使用
FileChannel:用于读取,写入,映射和操作文件的通道。
它只能通过调用getChannel()方式创建FileChannel对象,不能直接new FileChannel()。
优点:
1、对大文件操作支持比较好,文件访问和传输速度快。
2、支持多线程。
3、数据不易丢失。
SocketChannel:Java NIO中的SocketChannel是一个连接到TCP网络套接字的通道,是一种面向流连接只sockets套接字的可选择通道
特点如下: SocketChannel是用来连接Socket套接字 SocketChannel主要用途用来处理网络I/O的通道
SocketChannel是基于TCP连接传输 SocketChannel实现了可选择通道,可以被多路复用的
ServerSocketChannel:ServerSocketChannel 是一个可以监听新进来的TCP连接的通道, 就像标准IO中的ServerSocket一样。
DatagramChannel:使用UDP进行网络传输,UDP是无连接,面向数据包的协议,对传输的数据不保证安全与完整;
第三部分
- java基本类型表示的范围
整型:
byte:-2^7 ~ 2^7-1,即-128 ~ 127。1字节。Byte。末尾加B
short:-2^15 ~ 2^15-1,即-32768 ~ 32767。2字节。Short。末尾加S
有符号int:-2^31 ~ 2^31-1,即-2147483648 ~ 2147483647。4字节。Integer。
无符号int:0~2^32-1。
long:-2^63 ~ 2^63-1,即-9223372036854774808 ~ 9223372036854774807。8字节。Long。末尾加L。(也可以不加L)
浮点型:
float:4字节。Float。末尾加F。(也可以不加F)
double:8字节。Double。
字符型:
char:2字节。Character。
布尔型:
boolean:true false ;Boolean。
- java接口中的变量定义
在interface里面的变量都是public static final 的。
3.字符和整数相加,字符会转为对应的assic码,结果是整数
输出结果是:55
System.out.println('4'+3);
- 有364个结点的完全三叉树的深度?
(1-3^(n-1))/(1-3) = 364
n = 6 - URL url = new URL(“WWW.XXX.com”);如果该域名不纯在,返回结果?
返回结果依然是:WWW.XXX.com
https://www.cnblogs.com/justtofun/p/5628448.html
- 堆排序中,如何调整堆,大根堆是升序还是降序?
大根堆是升序,小跟堆是降序 - 在shell中中断及退出控制指令shift作用?
用于迁移变量的位置
https://www.cnblogs.com/image-eye/archive/2011/08/20/2147153.html
- 如果B类IP地址为10.12.3.0,无需再划分子网,则该IP地址的子网掩码?
应该为:255.255.255.255
- 时间复杂度为O(n)的排序?
桶排序、计数排序、基数排序
https://www.cnblogs.com/zpchya/p/10801324.html
- 时间复杂度为O(log(n))的排序算法
堆排序、归并排序和快速排序
https://www.cnblogs.com/zpchya/p/10775866.html
-
mybatis缓存?
一级缓存是SQLSession级别的缓存,mybatis默认开启一级缓存的
二级缓存是mapper级别的缓存,多个SQLSession去操作同一个mapper的SQL语句,多个SQLSession可以共享二级缓存,二级缓存 是跨SQLSession的
二级缓存作用于是mapper的同一个namespace,不同的SQLSession两次执行相同的namespace下的相同的SQL语句,第一次执行的完毕就会将数据写入缓存,第二次会从缓存中获取数据,mybatis默认没有开启二级缓存,二级缓存的开启需要在setting全局参数中开启二级缓存 -
数据库和缓存数据一致性保证?
淘汰缓存与更新缓存:淘汰缓存操作简单,并且带来的副作用只是增加了一次cache miss,建议作为通用的处理方式。
数据和缓存的操作时序:先淘汰缓存,再写数据库,再更新缓存。
https://blog.csdn.net/striveb/article/details/95110502
UDP和TCP的区别
-
对比
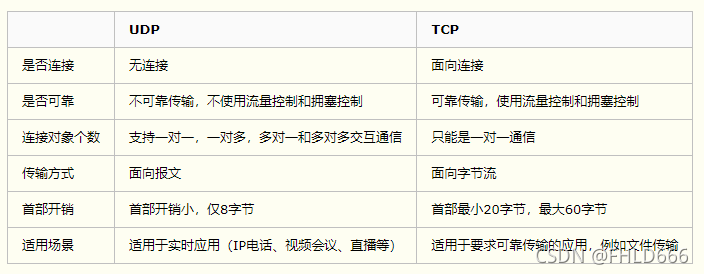
-
总结
1、TCP向上层提供面向连接的可靠服务 ,UDP向上层提供无连接不可靠服务。
2、虽然 UDP 并没有 TCP 传输来的准确,但是也能在很多实时性要求高的地方有所作为
3、对数据准确性要求高,速度可以相对较慢的,可以选用TCP
第四部分
- Linux下软连接和硬链接的区别?
软连接相当于快捷方式,文件的路径
硬链接相当于指针,也是个文件,是个指向真实文件的指针文件
ln fileName newFileName //创建硬链接
ln -s filenames newFileName //创建软连接
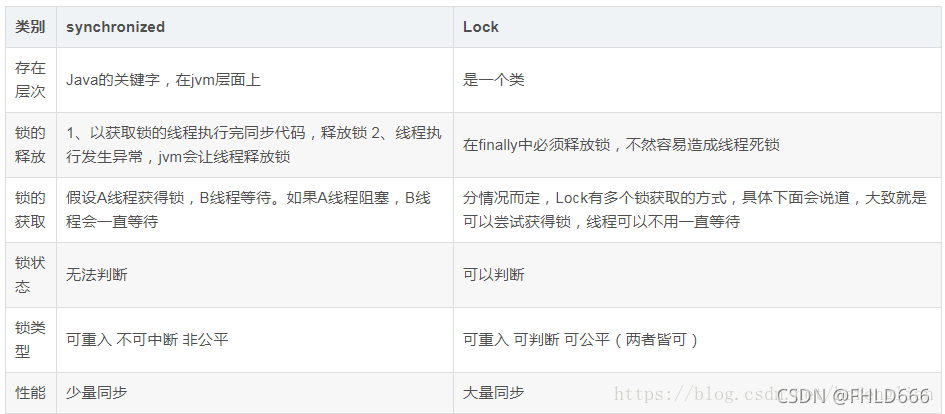
- synchronized和lock的区别














 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









