







📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗
🌻 近期刚转战 CSDN,会严格把控文章质量,绝不滥竽充数,如需交流,欢迎留言评论。👍
写在前面的话
技术栈:后端 SpringCloud + 前端 Vue/Nuxt
企业开发中,若后端采用的是微服务架构,通常会搭配链路追踪进行全链路的日志记录和展示。
常用的链路追踪方案有Sleuth + Zipkin或SkyWalking,这里先不赘述两个技术的对比,后面其他文章再加以说明。
博主所在公司,经过技术选型后,决定采用Sleuth + Zipkin作为链路追踪方案,下文以此展开介绍。
技术简介
Spring Cloud Sleuth
Sleuth 是一个用于分布式系统中的分布式追踪解决方案,集成了 Spring Boot 应用,使开发者可以轻松地在分布式系统中进行请求追踪。
Sleuth 主要负责生成和传播跟踪标识,并记录每个服务内部的请求处理信息,是跟踪数据的生产者。
Sleuth 可以通过配置,将跟踪数据直接发送到运行中的 Zipkin 服务器。
Zipkin
Zipkin 是一个开源的分布式跟踪系统,用于收集、存储、搜索和可视化跨多个服务的跟踪数据。
Zipkin 主要负责收集整合所有服务生成的跟踪信息,提供全局视图和跨服务的调用链分析功能。
Zipkin 接收由 Sleuth 生成的跟踪数据,并将这些数据存储在后端存储系统中(如 Elasticsearch、MySQL 等),并提供了一个用户界面用于查询和可视化这些数据。
基础使用
Step1、添加依赖
在 Spring Boot 项目中使用 Sleuth 和 Zipkin,需要在 pom.xml 文件中添加以下依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
Step2、相关配置
这里默认读者已完成了 Zipkin 的部署工作,如果仅为了单机测试,你可以使用 Docker 启动 Zipkin 服务器: docker run -d -p 9411:9411 openzipkin/zipkin
若是单体 SpringBoot 服务,直接在 application.yml 文件中配置 Sleuth 和 Zipkin 的相关信息,若采用 Nacos 作为配置中心,可以将这些配置放置在 Nacos 的全局配置中。
spring:
zipkin:
# 配置 Zipkin 服务器的基础 URL 地址。
# Spring Cloud Sleuth 会将收集到的追踪数据发送到这个地址。
base-url: http://localhost:9411/
sender:
# 指定追踪数据发送器的类型。
# web 类型表示使用 HTTP 协议将数据发送到 Zipkin 服务器。
# 可选值: web、rabbit、kafka 等,取决于你使用的消息传递机制。
type: web
sleuth:
sampler:
# 配置 Sleuth 的采样率,用于控制有多少比例的请求会被追踪。
# 取值范围为 0 到 1.0。1.0 表示对所有请求进行追踪。
probability: 1.0
Step3、使用 Sleuth (自动场景)
Spring Cloud Sleuth 会自动为所有的 HTTP 请求和异步任务(例如使用 RestTemplate 发出的请求)生成和传播 Trace ID 和 Span ID,并在日志中显示,你可以通过这些 ID 来追踪请求的整个链路。
在 Spring Boot 应用中, 自动链路追踪的场景包含但不限于:
- 所有的 HTTP 请求。
- 所有通过 RestTemplate、Feign 等客户端发起的 HTTP 调用。
- 所有通过 @Async 执行的异步任务。
- 所有通过 MessageChannel 发送和接收的消息(例如 Spring Cloud Stream)。
Step4、使用 Sleuth (手动场景)
尽管 Sleuth 会自动处理大部分的追踪场景,但在某些复杂或特定的业务逻辑中,你可能需要手动创建 Spans。
@RestController
public class ExampleController {
@Autowired
private Tracer tracer;
@GetMapping("/sync")
public String syncMethod() {
Span newSpan = tracer.nextSpan().name("syncSpan").start();
try (Tracer.SpanInScope ws = tracer.withSpanInScope(newSpan)) {
return "OK";
} finally {
newSpan.end();
}
}
}
Step5、查看追踪结果
在浏览器中打开 Zipkin UI,通常是 http://localhost:9411,你可以在这里查看和分析链路追踪数据。
示例效果如下图:
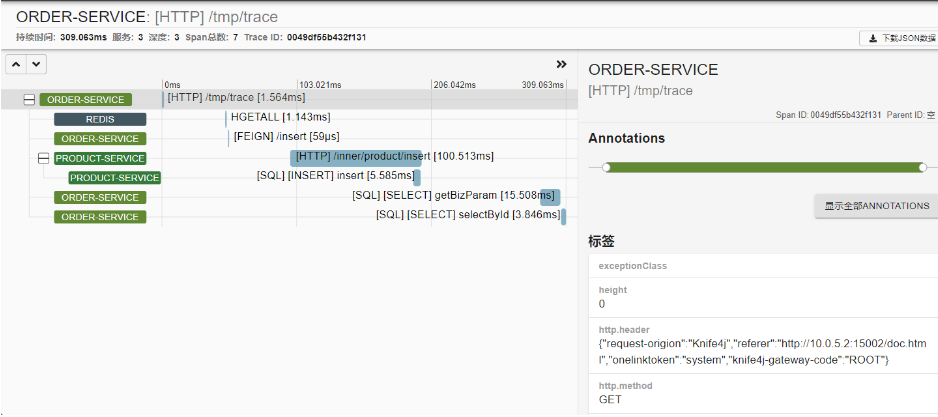
示例 · SQL请求追踪
Tips:这里分享若干手动添加链路追踪的示例,读者可参考扩展。
实现思路:
自定义 MyBatis 拦截器,在 SQL 执行前后分别埋点,计算耗时等相关信息后,再使用Sleuth记录。
部分代码:(如需完整代码可联系)
public class MybatisSqlTraceLogInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object[] args = invocation.getArgs();
// 获得SQL语句
MappedStatement mappedStatement = (MappedStatement) args[0];
String returnRows = "-1";
String sqlResult = "";
Span span = createNextTraceSpan(mappedStatement);
try {
Object proceed = invocation.proceed();
returnRows = this.getReturnRows(proceed);
sqlResult = this.getPageCountSqlResult(mappedStatement, proceed);
if (span != null) {
span.tag(TraceSpanConstant.SQL_ROWS, returnRows);
span.tag(TraceSpanConstant.SQL_RESULT, sqlResult);
}
return proceed;
} catch (Throwable ex) {
Throwable cause = ex.getCause();
if (span != null) {
if (ex instanceof InvocationTargetException && cause != null) {
span.error(cause);
} else {
span.error(ex);
}
}
throw ex;
} finally {
if (span != null) {
this.logSql(args, mappedStatement, returnRows, sqlResult, span);
span.finish();
}
SqlExecuteContextHolder.remove();
}
}
/**
* 创建下一个Zipkin链路Span
*/
private Span createNextTraceSpan(MappedStatement mappedStatement) {
String sqlId = mappedStatement.getId();
// 语法是否在白名单中
boolean isPermit = PathMatchUtil.isPermit(sqlId, this.sqlLogProperties.getIncludeMethods(),
this.loggingBlackListManagerAggregator.getBlackList(TraceSpanConstant.LogType.SQL), true, true, "SQL_TRACE");
// 黑名单语法直接忽略
if (!isPermit) {
if (log.isDebugEnabled()) {
log.debug("SQL处于日志黑名单中,已自动忽略. SQL_ID:{}", sqlId);
}
return null;
}
Span span = this.tracer.nextSpan().kind(Span.Kind.SERVER).start();
String fullSqlId = mappedStatement.getId();
String simpleSqlId = TraceLogUtil.abbreviator(fullSqlId);
String spanName = StrUtil.format("[SQL] [{}] {}", mappedStatement.getSqlCommandType().name(), simpleSqlId);
span.name(spanName);
span.tag(TraceSpanConstant.LOG_TYPE, TraceSpanConstant.LogType.SQL);
span.tag(TraceSpanConstant.SQL_ID, fullSqlId);
span.tag(TraceSpanConstant.SQL_TYPE, mappedStatement.getSqlCommandType().name());
return span;
}
}
示例 · 事务链路追踪
实现思路:
自定义实现Druid的FilterEventAdapter,在事务的相关节点进行代码埋点,计算耗时等相关信息后,使用Sleuth记录。
展示效果:
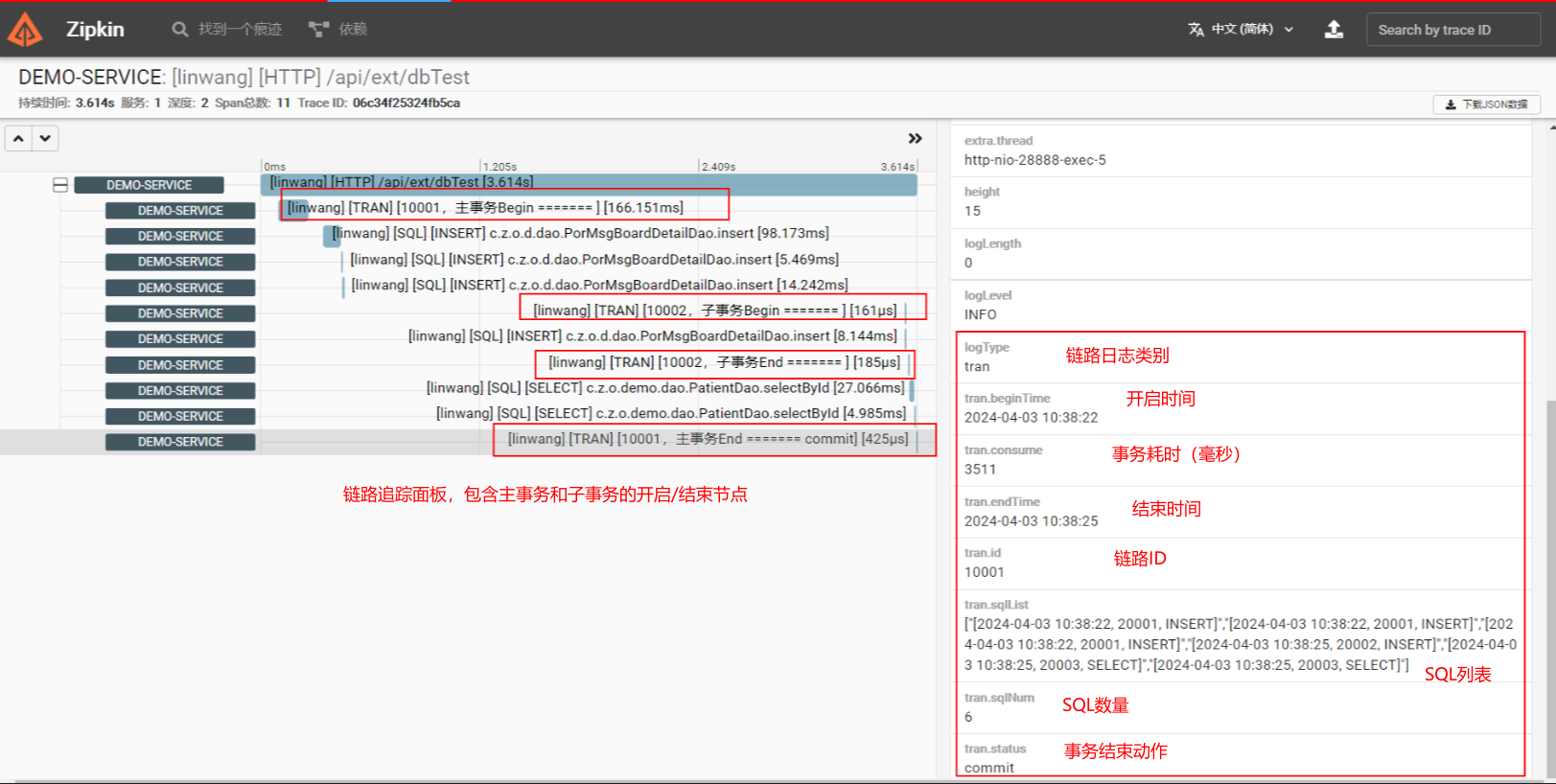

部分代码:(如需完整代码可留言联系)
public class DruidTxMonitorFilter extends FilterEventAdapter {
/**
* 创建下一个Zipkin链路Span
*/
private Span createNextTraceSpan(Long tranId, String flag, String status) {
Span span = tracer.nextSpan()
.kind(Span.Kind.SERVER)
.start();
String spanName = StrUtil.format("[TRAN] [事务ID:{},描述:{} ======= {}]", tranId, flag, status);
span.name(spanName);
span.tag(TraceSpanConstant.LOG_TYPE, TraceSpanConstant.LogType.TRAN);
span.tag(TraceSpanConstant.TRAN_ID, StrUtil.toString(tranId));
return span;
}
@Override
public void connection_setAutoCommit(FilterChain chain, ConnectionProxy connection, boolean autoCommit) throws SQLException {
super.connection_setAutoCommit(chain, connection, autoCommit);
if (!autoCommit) {
Long beforeId = TRAN_ID.get();
if (beforeId != null) {
// 子事务逻辑
Span span = this.createNextTraceSpan(connection.getId(), "子事务Begin", "");
span.tag(TraceSpanConstant.TRAN_BEGIN_TIME, DateUtil.formatDateTime(new Date()));
span.tag(TraceSpanConstant.TRAN_INFO, JSON.toJSONString(connection.getTransactionInfo()));
span.finish();
} else {
// 主事务逻辑
monitorReady(connection);
}
}
}
@Override
public void connection_commit(FilterChain chain, ConnectionProxy connection) throws SQLException {
try {
super.connection_commit(chain, connection);
//提交完成后清理本次事务的开始时间、执行的sql等线程绑定的内容
long id = connection.getId();
monitorTransactionTime(id, "commit");
} catch (Exception e) {
log.error(ExceptionUtil.stacktraceToString(e, 300));
}
}
/**
* 监控事务持续时间
*/
private void monitorTransactionTime(Long id, String status) {
Span span = null;
Long mainId = TRAN_ID.get();
if (mainId == null) {
return;
}
try {
String requestUri = OnelinkContextHolder.getString("requestUri");
if (!mainId.equals(id)) {
// 子事务逻辑
span = this.createNextTraceSpan(id, "子事务End", status);
span.tag(TraceSpanConstant.TRAN_END_TIME, DateUtil.formatDateTime(new Date()));
span.tag(TraceSpanConstant.TRAN_URL, StrUtil.emptyToDefault(requestUri, ""));
span.finish();
return;
}
if (TX_BEGIN_TIME.get() != null) {
// 计算和存储时间
long currentTime = System.currentTimeMillis();
Long beginTime = TX_BEGIN_TIME.get();
long timeCost = currentTime - beginTime;
// 创建结束事务的链路
Long tranId = TRAN_ID.get();
span = this.createNextTraceSpan(tranId, StrUtil.format("主事务End,耗时:{}", timeCost), status);
span.tag(TraceSpanConstant.TRAN_CONSUME_MS, StrUtil.toString(timeCost));
span.tag(TraceSpanConstant.TRAN_BEGIN_TIME, DateUtil.formatDateTime(DateUtil.date(beginTime)));
span.tag(TraceSpanConstant.TRAN_END_TIME, DateUtil.formatDateTime(DateUtil.date(currentTime)));
span.tag(TraceSpanConstant.TRAN_URL, StrUtil.emptyToDefault(requestUri, ""));
// 存储SQL
if (sqlLogProperties.isTxMonitorSqlEnabled()) {
List<String> sqlList = TX_SQL_LIST.get();
span.tag(TraceSpanConstant.TRAN_SQL_NUM, StrUtil.toString(sqlList.size()));
span.tag(TraceSpanConstant.TRAN_SQL_LIST, JSON.toJSONString(sqlList));
}
// 事务状态
span.tag(TraceSpanConstant.TRAN_STATUS, status);
}
} catch (Throwable e) {
log.error(ExceptionUtil.stacktraceToString(e, 300));
} finally {
if (mainId.equals(id)) {
TRAN_ID.remove();
TX_BEGIN_TIME.remove();
TX_SQL_LIST.remove();
OnelinkContextHolder.remove("requestUri");
if (span != null) {
span.finish();
}
}
}
}
}
扩展延申
上文介绍了Sleuth + Zipkin的基础使用,并且附带了两个手动记录Span的场景,实际开发中,能记录的链路信息远不止这些,架构封装人员可依照实际情况全面考虑。
实际开发中,通常还会将 Zipkin数据存储在 Elasticsearch中,后续还可以通过Kibana或自研日志页面,进行更全面详细的信息查询,这里篇幅受限,不一一展开了。
💗 后续会逐步分享企业实际开发中的实战经验,有需要交流的可以联系博主。
















 1065
1065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











