







在Web应用程序中大部分内容都与表示有关,但它的价值与竞争优势却可能体现在若干专有服务或算法方面。如果这类处理会消耗大量时间和资源,将其分离出来以异步的方式执行是比较常见的做法。要完成这样的任务,需要一个消息队列来进行管理。Gearman和Beanstalkd是比较常用的两个,这里对这两个队列进行一个对比。
Gearman:
Gearman是一个分发任务的程序框架来将你的任务分发到不同的机器或者不同的进程当中。它提供了并行工作的能力、负载均衡处理的能力,以及在不同程序语言之间沟通的能力,可以用在各种场合,与Hadoop相比,Gearman更偏向于任务分发功能。它的任务分布非常简单,简单得可以只需要用脚本即可完成。
工作原理:
使用Gearman的应用通常有三部分组成:一个client、一个worker、一个jobserver。 Client的作用是提出一个Job任务交给job server。job server会去寻找一个合适的worker 来完成这项任务。wrker执行由client发送过来的job,并且将结果通过job server 返回给client。Gearman 提供了client和worker的API,利用这些API 应用可以同Gearman job server来进行通信。Gearman内部client和worker之间的通信都是通过TCP连接来进行的。工作的流程如下图1。

图1、Gearman的工作流程图
Gearman可以将工作的负载分担到不同的机器中,job server可以开启多个实例,这样在其中一个发生故障的时候,可以failover到其他的机器上。同样,对于多核服务器可以同时创建多个worker实例进行运行,如图2所示。
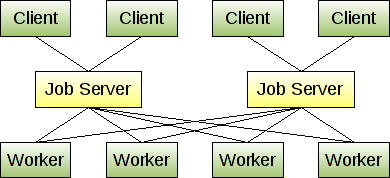
图2、Gearman集群
优点:
开源:Gearman免费并且开源而且有一个非常活跃的开源社区,如果你想来做一些贡献,请点击。
多语言支持:Gearman支持的语言种类非常丰富。让我们能够用一种语言来编写Worker程序,但是用另外一种语言编写Client程序。
灵活:不必拘泥于固定的形式。您可以采用你希望的任何形式,例如Map/Reduce。
快速:Gearman的协议非常简单,并且有一个用C语言实现的,经过优化的服务器,保证应用的负载在非常低的水平。
可植入:因为Gearman非常小巧、灵活。因此您可以将他置入到现有的任何系统中。
没有单点:Gearman不仅可以帮助扩展系统,同样可以避免系统的失败。
Beanstalkd:
Beanstalkd是一个高性能、分布式、轻量级的内存队列系统。
基本概念:
job: 需要异步处理的任务,是Beanstalkd中的基本单元,需要放在一个tube中。
tube: 任务队列,用来存储统一类型的job,是producer和consumer操作的对象。
producer: job的生产者,通过put命令来将一个job放到一个tube中。
consumer: job的消费者,通过reserve|release|bury|delete命令来获取job或改变job的状态。
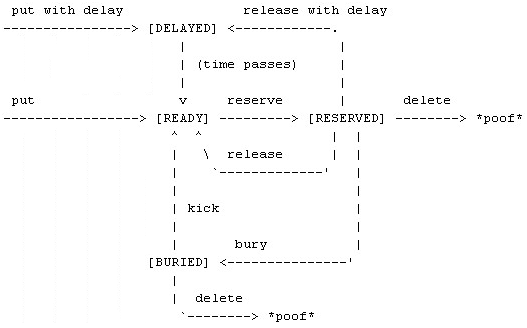
图3、Beanstalkd中任务的生命周期
同Memcached的设计类似,Beanstalkd的协议设计比较简单明了,当一个任务被添加进Beanstalkd的队列里时,它的生命周期如图3所示。可以看到job有READY,RESERVED,DELAYED,BURIED四个状态。当一个producer直接put一个job之后,该job便进入了READY状态,等待consumer来处理。如果选择延迟put,job就先到DELAYED状态,等待指定时间后才迁移到READY状态。当consumer获取到该job后,该job的状态就从READY迁移RESERVED,这样其他的consumer就不能再操作该job;当consumer完成该job后,可以选择delete,release或者bury操作;delete之后,job从系统消亡,之后不能再获取;release操作可以重新把该job状态迁移回READY(也可以延迟该状态迁移操作),使其他的consumer可以继续获取和执行该job;
Beanstalkd中有一到多个tube。每个tube都有一个ready队列和一个delay队列组成。一个job的生命周期只会存在于一个tube中。consumer要从某个tube获取job,可以向其发送watch命令;如果consumer想忽略某些tube,则可以像其发送ignore命令。consumer感兴趣的tube集合称之为wath list。显然,一个consumer获取的job肯定是来自它的watch list当中。
当一个consumer没有指定tube名称时,它有一个默认的watch list称之为default。同理,如果producer提交job时没有指定tube名称,则默认添加到default当中。
当tube被引用时,它们会根据需要自动创建。如果一个tube中是空的(即它不包含REDY,DELAYED,BURIED jobs),并且没有consumer连接到它,它就会被删除。
特性:
优先级:支持0到2**32的优先级,值越小,优先级越高,默认优先级为1024。
持久化:可以通过binlog将job及其状态记录到文件里面,在Beanstalkd下次启动时可以通过读取binlog来恢复之前的job及状态。
分布式容错:分布式设计和Memcached类似,beanstalkd各个server之间并不知道彼此的存在,都是通过client来实现分布式以及根据tube名称去特定server获取job。
任务休眠:当一个job发生错误,你可以将其bury(休眠)。这个特性方便了以后的调试和排查工作(甚至重新运行),同事将该job与其它活动的job分开。
超时控制:为了防止某个consumer长时间占用任务但不能处理的情况,Beanstalkd为reserve操作设置了timeout时间,如果该consumer不能在指定时间内完成job,job将被迁移回READY状态,供其他consumer执行。
总结
表1、Gearman和Beanstalkd总结
| Gearman | Beanstalkd | |
| Language | C | C |
| Ubuntu Package | gearman-job-server | beanstalkd |
| Python lib | gearman | beanstalkc |
| Memory | 1.4Mb | 0.7Mb |
| License | BSD | GPL |
Beanstalk速度非常快,协议简单,占用内存空间少(这点从表1中可以看出),而且支持持久化。唯一的不足是挂了之后恢复慢,3G日志数据恢复了十多分钟。
Gearman支持简单的优先级和同步与异步任务,配置一下可以实现队列信息持久化,Gearman最大的问题是自己维护队列却没有提供查看队列的接口,哪怕是命令行接口,这导致在高速写入后,很难判定所有的job是不是都完成了,如果配置了外部持久化存储,这个问题也容易解决,Gearman用的人比较多,性能比较优秀。
参考资料:
[1] http://www.cnblogs.com/cocowool/archive/2011/08/18/2145144.html
[2] http://www.ibm.com/developerworks/cn/opensource/os-php-gearman/
[4] https://github.com/kr/beanstalkd/wiki/faq
[5] http://rdc.taobao.com/blog/cs/?p=1201
[6] http://adam.heroku.com/past/2010/4/24/beanstalk_a_simple_and_fast_queueing_backend/
[7] http://www.darkcoding.net/software/choosing-a-message-queue-for-python-on-ubuntu-on-a-vps/















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









