要从零开始,五分钟做完一个基于SPARK的PM2.5分析项目,你是不是会问
1. PM2.5的数据在哪里?
2. SPARK的环境哪儿有?
3. 程序怎么编?
不用急,跟着我做,5分钟就可以从零开始完成所有的事情。
准备SPARK环境
今天,在各种公有云都可能申请到SPARK的环境。但彻底免费,启动最容易的是在超能云(SuperVessel)上面的SPARK服务,完全免费。
首先登录超能云主页 http://www.ptopenlab.com . 如果你之前没有申请过帐号,可以直接申请。新申请的帐号,会收到来自 manager@ptopenlab.com 的邮件,点击里面的链接来激活帐号。
登录之后,选择主页上面的"大数据实验室(Big data service)"。
登录大数据服务,在登录见面上再次输入你注册的用户名和密码。就可以进入大数据服务页面。
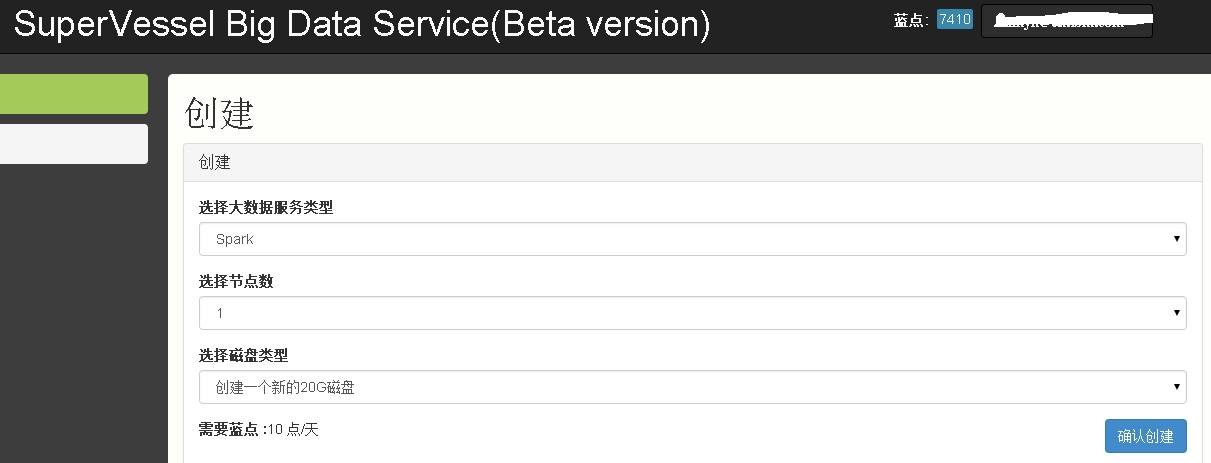
点击创建,即可进入创建大数据集群的界面。目前,超能云上提供了MapReduce和SPARK两种环境。我们选择SPARK,选择最小的单节点即可,如下图所示。
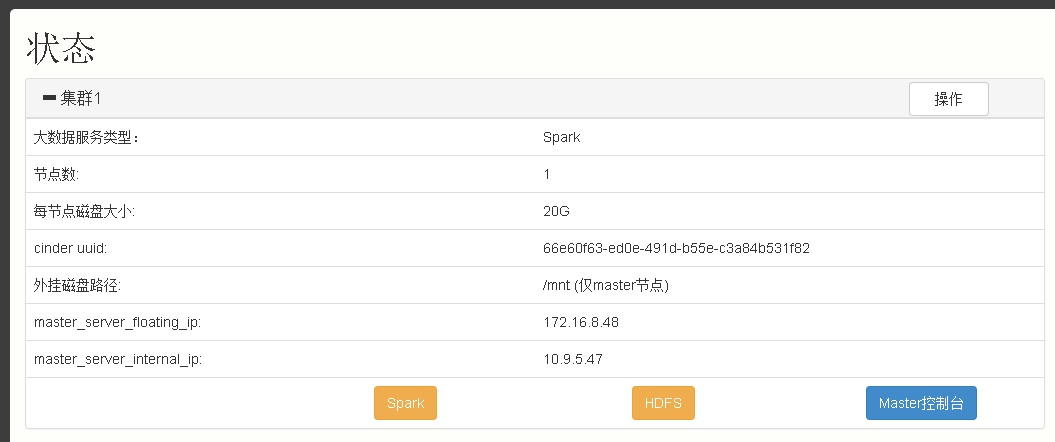
点击“确认创建”后,大概过30秒钟,单节点的SPARK环境就构建成功。可以看到如下界面。
点击“Master控制台”按钮,就会出现一个登陆到编辑控制台的新页面,如下。默认密码是“passw0rd”.
就可以进入SPARK集群master节点的命令行界面。到这一步,就完成SPARK环境的准备了。
PM2.5数据
为了方便同学们进行SPARK的学习,我们特地把过去5个月的PM2.5数据放到了超能云上面,供大家作为实验数据:)这些数据是从我们5个PM2.5监测传感器每天测量所得的第一手真实数据。它们测量的是北京上地中关村软件园地区的真实情况哦。
不要小看这五个PM2.5空气质量传感器,它们是IBM研究院的最新研究成果。先看看图吧,个子小,完全符合工业户外设计要求,自带3G数据回传,而且是太阳能供电。一句话,户外室内安装,一根线都不用拉。就这么酷!
先上个图,有图有真相。
这是一个是基于激光散射技术(米氏散射理论)的低成本传感器。相比于现行市场上的传感器技术,精度高多了,能从PM0.3一直测到PM10,关键是免维护。
言归正传,我们这次把数据都整理好,方便超能云的用户进行尝试数据分析。获取数据的方法如下:
cd /home/ opuser
wget http:
tar -xf pm25_file .tar 在生成的目录pm25_file中有三个文件。其中,pm25.txt是数据文件,例如08-Nov-2014, 84是指2014年11月8日某一时刻的测量值为84.
SPARK的实现代码
1.以脚本运行






























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









