







2.1.8.5、Memory addressing
以上小节介绍了spark对堆的划分,根据使用目的不同,对堆进行了区域划分,并说明了spark1.6之前和之后使用的两种不同内存模型管理以及之间的区别,那么这里继续逐步分析,说到内存管理,spark是如何通过进行内存寻址,内存块是如何封装的,通过何种方式来组织管理这些内存块?
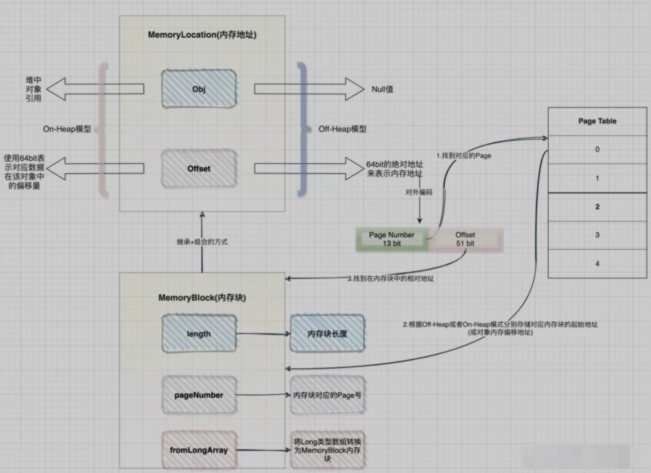
问1:如何进行内存寻址的?
答:这里需要再次回到Project Tungsten计划中,由于spark引入了Off-Heap内存模式,为了方便统一管理On-Heap和Off-Heap这两种模式,Tungsten引入了统一的地址表示形式,即通过MemoryLocation类来表示On-Heap或Off-Heap两种内存模式下的地址,该类中有两个属性obj和offset,当处于On-Heap模式下,通过使用obj(即为对象的引用)和64 bit的offset来表示内存地址,当处于Off-Heap模式下,直接使用64 bit的offset绝对地址来描述内存地址。而这个64bit 的offset在对外编码时,前13 bit用来表示Page Number,后51 bit用来表示对应的offset
问2:内存块是如何封装的?
答:在Project Tungsten内存管理中,会使用一块连续的内存空间来存储数据,通过MemoryBlock类对内存块进行封装。该类继承了MemoryLocation类,采用了组合复用方式,即指定了内存块的地址,也提供了内存块本身的内存大小
问3:如何组织管理内存块?
答:Project Tungsten采用了类似于操作系统的内存管理模式,使用Page Table方式(其实本质就是一个数组,从源码中就可以看出)来管理内存,内部以Page来管理存储内存块(通过MemoryBlock来封装),通过pageNumber找到对应的Page,Page内部会根据Off-Heap或On-Heap两种模式分别存储Page对应内存块的起始地址(或对象内偏移地址)
在spark中,数据是以分区进行处理的,而每个分区对应一个task,所以对于内存的组织和管理可以借助于TaskMemoryManager来理解,同时以上这些疑惑均可以在TaskMemoryManager类(该类对MemoryManager又做了一层封装)中找到解答。
源码实现-TaskMemoryManager

2.1.8.6、Memory Configuration

2.1.8.7、Tungsten Optimize-CPU
2.1.8.7.1 缓存感知计算Cache-aware computation
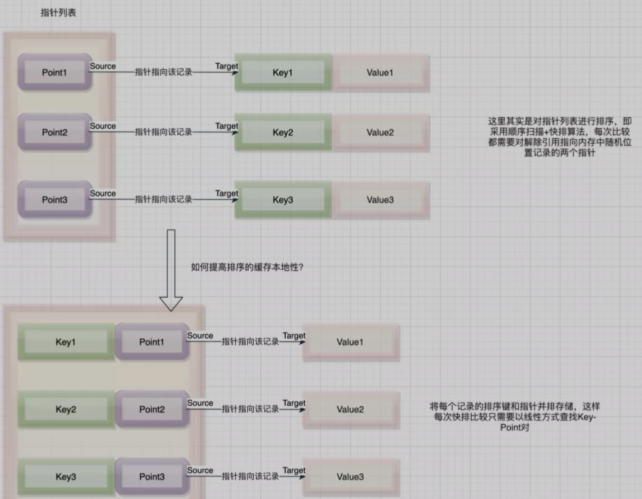
缓存感知计算通过使用L1/L2/L3 CPU缓存来提升速度,同时也可以处理超过寄存器大小的数据。Spark开发者们在做性能分析的时候发现大量的CPU时间会因为等待从内存中读取数据而浪费,所以在Tungsten项目中,通过设计了更加友好的缓存算法和数据结构,让spark花费更少的时间等待cpu从内存中读取数据,提供了更多的计算时间。
缓存感知计算的解析
网上有很多关于缓存感知的说明,都是以KV排序为例,那么笔者这里也使用同样的例子再结合自己的理解,尽量解释的通俗易通。
3.2 代码生成Code Generation
代码生成指的是在运行时,spark会动态生成字节码,而不需要通过解释器对原始数据类型进行打包,同时也避免了虚拟函数的调用。当然该技术的优势并不止于此,还包括了将中间数据从存储器移动到CPU寄存器;使用向量化技术,利用现代CPU功能加快了对复杂操作运行速度
这里以一个sql为例,可以通过explain来查看spark在哪些过程中使用了代码生成的功能。
当算子前面有一个*时,说明全阶段代码生成被启用,在下面的例子中,Exchange算子没有实现代码生成,这是因为这里会发生Shuffle,需要通过网络发送数据。
select count(1) from tmp.user where id='123'
== Physical Plan ==
*(2) HashAggregate(keys=[], functions=[count(1)])
+- Exchange SinglePartition
+- *(1) HashAggregate(keys=[], functions=[partial count(1)])
+- *(1) Project
+- *(1) Filter ((id#2882514 = 123))
+- HiveTableScan [id#23025141, HiveableRelation tmp.user.org.apachehadoop.hive.serde2.lazy.lazySimpleSerDe, [id#2802514]2.1.8.8、Demo of Memory Divison
/usr/local/spark-current/bin/spark-submit \
--master yarn \
--deploy-mode client \
--executor-memory 1G \
--queue root.default \
--class my.Application \
--conf spark.ui.port=4052 \
--conf spark.port.maxRetries=188 \
--num-executors 2 \
--jars mongo-spark-connector_2.11-2.3.1.jar \
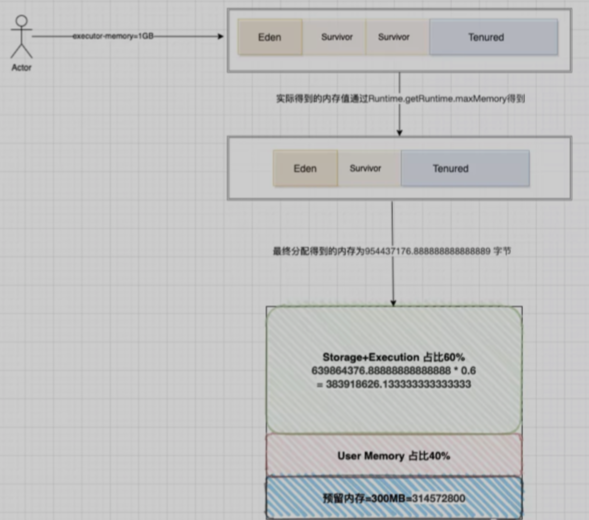
App.jar 20201118000000这里配置两个Executor,每个Executor内存给1G

如图所示,spark申请到了两个Executor,每个Executor得到的Storage Memory内存分别为384.1MB(注意:这里Storage Memory其实就是Storage+Execution的总和内存),这里有一个疑惑,我们分配的是每个Executor内存为1G,为什么只得到384MB呢?这里给出具体的计算公式:
1、我们申请为1G内存,但是真正拿到内存会比这个少,这里涉及到一个Runtime.getRuntime.maxMemory 值的计算(UnifiedMemoryManager源码分析中提到过),Runtime.getRuntime.maxMemory对应的值才是程序能够使用的最大内存,上面也提到了堆划分了Eden,Survivor,Tenured区域,所以该值计算公式为:
ExecutorMemory = Eden + 2 * Survivor + Tenured = 1GB = 1073741824 字节
systemMemory = Runtime.getRuntime.maxMemory = Eden + Survivor + Tenured = 954437176.888888888888889 字节
//org.apache.spark.memory.UnifiedMemoryManager(这里讨论的还是动态内存模型)
private def getMaxMemory(conf: SparkConf): Long = {
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val reservedMemory = conf.getLong("spark.testing.reservedMemory"
if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)
//这里即获取最大的内存值
(usableMemory * memoryFraction).toLong
}2、基于Spark的动态内存模型设计,其中有300MB的预留内存,因此剩余可用内存为总申请得到的内存-预留内存
reservedMemory = 300MB = 314572800字节
usableMemory = systemMemory - reservedMemory = 954437176.888888888888889 - 314572800 = 639864376.888888888888889字节
3、Spark Web UI界面上虽然显示的是Storage Memory,但其实是Execution+Storage内存,即该部分占用60%比例Storage + Execution = usableMemory * 0.6 = 639864376.888888888888889 * 0.6 = 383918626.133333333333333 字节
4、通过第三步骤即可看出实际的内存分配情况了,注意:web ui界面得到的结果计算是除于1000转换得到的值。
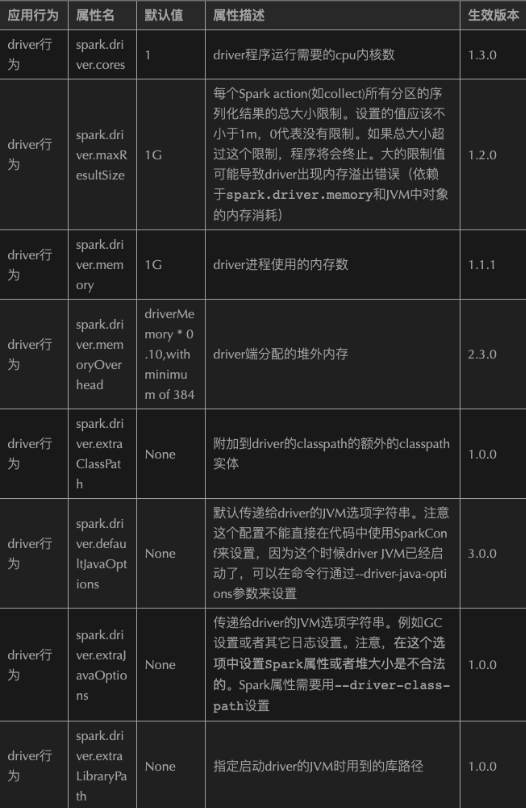
2.1.8.9、Optimize Configuration






















 1102
1102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











