






找了很多资料,很多方法都会报错,看了这个个方法,才最终解决,就应用了这个方法,并附上自己的理解。
一、下载:
到 网站搜索heritrix, 然后分别下载下来heritrix-1.14.4.zip
(注意在装载之前需要装java运行环境,我先装了jdk-8-windows-x64,然后在装载了eclipse-standard-kepler-SR2-win32-x86_64,最后才装了heritrix-1.14.4.zip)
二、配置
1. 解压 heritrix-1.14.4.zip ,假设解压到了c 盘根目录下并把解压后的文件夹命名为heritrix(进入c:/heritrix/conf 复制文件jmxremote.password.template 到c:/heritrix 下并把文件重新命名为jmxremote.password ,
然后修改其内容为下:
monitorRole @123456789@ ->monitorRole admin (@ 于@ 之间设置的是密码, 后面是-> 用户角色用户名)
controlRole @123456789@ ->controlRole shi
并设置文件jmxremote.password 的属性为只读
3. 进入c:/heritrix/conf 打开文件heritrix.properties ,修改其中的几项key-value 值
heritrix.cmdline.admin = admin:770629 ( 用户名:密码)
heritrix.cmdline.port = 8080 (heritrix 服务器默认端口号8080, 保证该端口不被占用就不用改了)
4. 打开cmd ,切换目录到c:/heritrix/bin
然后敲入命令:heritrix.cmd --admin=admin:123456789
会出现如下错误:
1 WARNING: It's currently not possible to run Heritrix in background
2 on Windows. It was just started minimized in a new Window
3 and will be shut down as soon as you log off.
4 2011 / 02 / 25 周五 23 : 49 : 27.00 Starting heritrix
5 Heritrix failed to start properly. Possible causes:
6 - Login and password have not been specified (see --admin switch )
7 - another program uses the port for the web UI ( 8080 by default )
8 (e.g. another Heritrix instance)
9 - JMX password file is missing or permissions not set correctly
10 JMX permissions file missing. A template can be found in
11 E:\framework\heritrix-1.14 . 4 \conf\jmxremote.password.template.
12 Copy it to
13 E:\framework\heritrix-1.14 . 4 \jmxremote.password
14 and edit the passwords at the end of the file. Then, make sure
15 the file is read-restricted to only the user that the Heritrix
16 Java VM will run as. For example:
5. 再设置文件的为只读,并且要设置文件的拥有者只能为当前登录系统的用户,删除文件的其他用户或角色权限。修改方法:
文件->属性->"安全"标签页->高级->"权限"标签页->更改权限按钮
->取消"包括从该对象的父项继承的权限"的勾选-,同时再删除其他多余的用户或角色权限(只留下当前登录系统的用户)
如果删除不了要全部设定他们的权限限定
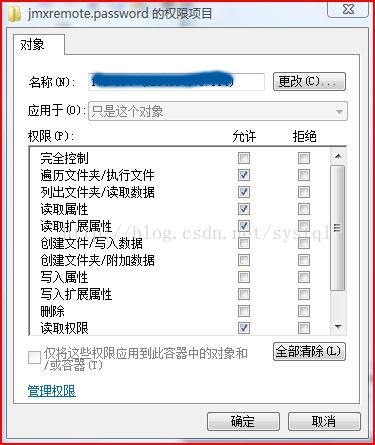
里面的用户要全部设定权限,不然会报错的要















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









