







 这篇博客探讨了如何使用JavaFX的WebView组件进行可视化信息抽取,详细讲解了如何获取网页元素信息、绑定DOM树、高亮元素、处理滚动条、响应窗口变化等问题,并提供了JavaScript交互和XPath操作的解决方案。内容涵盖了JavaFX与JavaScript交互、DOM监听、DOM结构变化的MutationObserver对象等技术。
这篇博客探讨了如何使用JavaFX的WebView组件进行可视化信息抽取,详细讲解了如何获取网页元素信息、绑定DOM树、高亮元素、处理滚动条、响应窗口变化等问题,并提供了JavaScript交互和XPath操作的解决方案。内容涵盖了JavaFX与JavaScript交互、DOM监听、DOM结构变化的MutationObserver对象等技术。
1、阅读说明
本篇博客是非介绍类的,即,不含有关于JavaFX的基础介绍。博客主要描述实现可视化信息抽取时,如何利用JavaFX的WebView组件。仅介绍涉及到的JavaFX的内容,至于可视化信息抽取的算法是哪个,博客不进行介绍,提供的源码中有一个可视化信息抽取的演示Demo,Demo不涉及到核心算法,是基于定制规则进行抽取的。
博客内容是我毕业设计(基于反馈学习的半结构化信息抽取研究及应用)可能涉及到的基础技术的准备和总结,技术准备的时间较短,同时心里着急找工作(真心着急。。。),里面可能有不正确的,如有发现,请指正,同时提醒,本博客内容只是作为技术实现的可行tips,千万不要作为标准样板,关于某些问题,如果您有发现新的解决方案,请您一定要告诉我一下,非常感谢!
2、主要解决的问题
- 如何获取WebView渲染后网页中元素的基本信息,比如x,y坐标、字体大小、字体颜色、背景色等等;
- 如果用TreeView绑定DOM树,同时实现右键TreeView时,查看元素的基本信息或者高亮指定元素;
- 如果直接通过右键浏览器界面来高亮点击的元素;
- 如何获取WebView的滚动条对象、滚动条的宽度和判断滚动条的方向;
- 如何在拖拽窗体、最大化窗体等改变窗口大小时,获取WebView中的元素坐标位置;
- 对于已生成的Document文档对象,如何在Java中监听网页中对应DOM树的结构的变化;
- 如何对JavaFX生成的DOM对象,进行XPath操作;
- Java如何执行WebView渲染网页中的按钮自动点击操作,比如“下一页”自动点击下一页,“百度一下”自动进行搜索。
3、尚未完全解决的问题
- 网页随着滚动条滚动加载时,如何快速让网页滚动至网页底部,使其加载完全(因为滚动条不止滚动一次,即到底部以后,有可能还需要继续滚动)
- WebView对象怎么具体识别水平滚动条和垂直滚动条(因为编程过程中,发现WebView有多个ScrollBar对象,有时候多达10多个,如何区分哪两个是有效的,暂时不会)
- WebView.onScrollProperty().addListener((ChangeListener<? super EventHandler<? super ScrollEvent>>),这个addListener函数如何添加参数,因为<? super EventHandler<? super ScrollEvent>>是嵌套类型的,实现时,总是提示错误,当时解决了,撤销以后,隔天又忘了。
本文涉及到的JavaFX对应的JDK版本是JDK1.7
4、关于JavaFX的基本概念
关于JavaFX的基本概念,比如,JavaFX UI组件的使用、布局相关、Web组件相关等等,可参考JAVAFX中文资料。这个网页相当于Oracle官方文档的翻译,里面有基础知识介绍,以及相关实现代码,非常推荐。对应英文版入口JavaFX: Getting Started with JavaFX 和 Java Platform, Standard Edition (Java SE) 8相关资料(含JavaFX),JavaFX 2.0的API文档。
JavaFX是和DOM模型以及CSS紧密相结合的。尤其是WebView,获取渲染后的网页内容,一般都是通过执行JavaScript获取的。所以,学习或者利用JavaFX解决相关问题时,一定不要局限于窗体程序思维,一定要记住JavaFX和JavaScript的交互性。我刚开始接触JavaFX,就因为这个,想很多问题时就太死板,浪费很多时间。
JavaFX事件模型是DOM2事件模型,DOM2事件模型有一个典型的特性,就是事件从“顶层开始捕获,直至目标元素,然后事件相应处理从目标元素冒泡到顶层”(推荐文档:JAVAFX-事件),如下图:
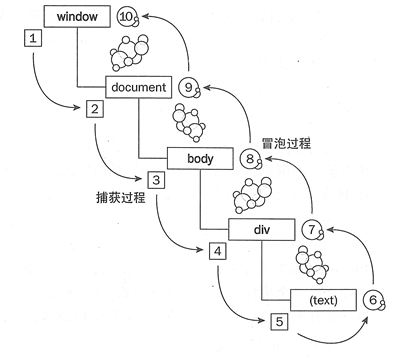
图片引用来自:http://www.csdn123.com/html/topnews201408/5/11405.htm
之所以要强调DOM2模型,是因为这个特性对于绑定有层次关系的元素结点时,不需要每个结点都进行绑定,只需要绑定根结点就可以了。比如,TreeView是一个典型的层次树形结构,给这个TreeView中的每个TreeItem绑定触发收起事件(collapsed event)时的特殊处理操作时,不需要每一个TreeItem都需要调用addEventHandler函数,而只需要对TreeView的root的TreeItem进行绑定就可以了,在事件里面通过(TreeItem)event.getTarget()来获取被点击的TreeItem或者通过event.getTreeItem()直接获取。参考代码片段如下,完整代码,请看最下面附件。
treeItemParent.addEventHandler(TreeItem.<DOMBox> branchCollapsedEvent(),
new EventHandler<TreeItem.TreeModificationEvent<DOMBox>>() {
@Override
public void handle(TreeItem.TreeModificationEvent<DOMBox> event) {
TreeItem<DOMBox> tCurrent = event.getTreeItem();
DOMBox domBox = (DOMBox) tCurrent.getValue();
if (!ElementTools.isSelfClose(domBox.getTagName())) {
String strHtml = domBox.getSelfHtml() + "...</" + domBox.getTagName() + ">";
domBox.setSelfHtml(strHtml);
TreeItem<DOMBox> tNext = tCurrent.nextSibling();
tNext.getParent().getChildren().remove(tNext);
}
}
});上述代码片段是实现html树结点展开后的收起功能,如下图:
treeItemParent就是TreeView的根TreeItem。DOMBox是TreeItem关联的数据类型,可以String等任意类型,TreeView在显示TreeItem时,是调用TreeItem关联的数据的toString()函数,本样例就是DOMBox的toString()函数,所以你可以对toString()进行重载来显示自己需要展示的东西。
强调JavaFX和CSS的交互性,是因为可以通过样式表查找元素,或者通过修改样式表来改变原始文档的展示效果。下述代码片段是通过CSS来查找ScrollBar的:
/**
* Returns the vertical scrollbar of the webview.
*
* @param webView webview
* @return vertical scrollbar of the webview or {@code null} if no vertical
* scrollbar exists
*/
private ScrollBar getVScrollBar(WebView webView) {
Set<Node> scrolls = webView.lookupAll(".scroll-bar");
for (Node scrollNode : scrolls) {
if (ScrollBar.class.isInstance(scrollNode)) {
ScrollBar scroll = (ScrollBar) scrollNode;
if (scroll.getOrientation() == Orientation.VERTICAL) {
return scroll;
}
}
}
return null;
} 通过WebView的lookup或者lookupAll函数来进行查找相关元素。
以下是遍历元素结点样式表的代码片段,以ScrollBar为例。
List<CssMetaData<? extends Styleable, ?>> css = scroll.getCssMetaData();
for (int i = 0; i < css.size(); i++) {
CssMetaData<? extends Styleable, ?> oneAttr = css.get(i);
System.out.print(oneAttr.getProperty() + ":" + ((CssMetaData<ScrollBar, ScrollBar>) oneAttr).getStyleableProperty(scroll).getValue() + "\t");
}
System.out.println(); scroll是ScrollBar对象,其他具有getCssMetaData函数的对象均可如上述进行结点遍历,比如WebView对象。关于JavaFX控件的样式表,可以参考官方文档 JavaFX CSS Reference Guide
关于JavaFX的布局元素的介绍,除了JAVAFX中文资料中的介绍,再推荐一篇文章,个人感觉很有帮助:JavaFX 2.0 Resizing of UI Controls。
5、问题具体解决方案
强烈推荐Stack OverFlow,我的解决方案好像都是在其中看的代码片段知道的。
5.1 如何获取WebView渲染后网页中元素的基本信息,比如x,y坐标、字体大小、字体颜色、背景色等等
因为毕业设计的信息抽取是基于可视化模块后,进行抽取的,主要是采用VIPS算法进行Page Segment,就是对网页进行分块。VIPS算法进行分块时,需要用到元素的字体大小、背景色、坐标位置等等信息,VIPS的Github上有Java版具体实现vips_java,不过这个版本基于CSSBox实现的,CSSBox不能解析JavaScript,只能渲染纯Html+CSS的网页,所以有限制,所以才采用JavaFX对网页进行渲染解析,同时不得不使用JavaFX获取元素的这些基本信息。
最初的想法是以为JavaFX会有单独存储CSS DOM的结构,不过最终查阅了一些文档,发现很有有说通过底层API访问CSS DOM的(最初都快疯了,以为需要阅读JavaFX的源码,然后改源码呢。。。),在查找的过程中,有人提及通过执行JavaScript代码来获取相应的属性,这才给了一个思路,而且以后的很多问题解决方案,也自然而然的往这方面考虑了。在将具体怎么获取元素的基本信息之前,先说一下在查找中发现的一个有趣的事情,是关于CSS的style的。就是样式表的种类:
- 浏览器默认样式,就是浏览器自身所带的样式表,因为添加样式时,你不可能将所有样式都添加进去,比如h1默认展示的样式,就是浏览器自身的。这个概念之前还真没有注意。
- .css文件中的样式
- 网页中style结点中定义的样式
- 标签内嵌的样式,就是元素中style属性中定义的样式
JavaFX一般提供的接口获取的是第四种,即“标签内嵌的样式”,这个功能是满足不了我的需求的,所以需要借助JavaScript来获取渲染后的所有样式。
通过JavaScript获取字体颜色等信息,可以使用document.defaultView.getComputedStyle来获取具体元素的信息,关于getComputedStyle的具体使用,可以百度,有很多相关介绍。以下是部分代码片段:
// 计算对应元素的属性
public DOMBox getDOMBoxByNode(WebEngine wEngine, Element e){
JSObject obj_defaultView = (JSObject)webEngine.executeScript("document.defaultView");
JSObject obj_ComputedStyle = (JSObject)obj_defaultView.call("getComputedStyle", e,null);
JSObject obj = (JSObject)e;
String tag_name = e.getTagName().toLowerCase();
String strTemp = obj_Com 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2529
2529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









