



 腾讯AILab绝艺团队提出对手建模算法框架,可在游戏场景中针对当前对手动态智能切换策略,实现“见招拆招”。该方法在理论上和实际针对不同对手的实验中都能取得更高的收益。
腾讯AILab绝艺团队提出对手建模算法框架,可在游戏场景中针对当前对手动态智能切换策略,实现“见招拆招”。该方法在理论上和实际针对不同对手的实验中都能取得更高的收益。

来源:机器之心
本文约1200字,建议阅读5分钟腾讯 AI Lab「绝艺」团队提出了一套「对手建模」算法框架,在游戏场景中可针对当前对手动态智能切换策略。当前业内知名的竞技游戏 AI,在与人对抗过程中往往采取固定的策略,这可能会带来两方面的性能损耗:[1] 如果这个 “固定” 策略有漏洞并且一旦被人发现,那么这个漏洞就可以被一直复现。换句话说,采取固定策略的 AI 容易被人“套路”。[2] 采取固定策略的 AI 不能针对不同对手采取不同策略来获取更高的收益。例如,在二人石头 - 剪刀 - 布游戏中,如 AI 能针对有出剪刀倾向的对手多出石头,针对有出石头倾向的对手多出布,那么理论上 AI 能有更高的性能上限。
对此,腾讯 AI Lab「绝艺」团队提出了一套 “对手建模” 算法框架,在游戏场景中可针对当前对手动态智能切换策略,实现“见招拆招”。该方法在理论上和实际针对不同对手的实验中都能取得更高的收益,相关工作已被机器学习顶会 ICML 2022 收录。

论文链接:
https://proceedings.mlr.press/v162/fu22b.html
这项工作的核心在于如何在多智能体系统中对其他智能体不可观察的隐变量(例如策略,喜好,目标,等)进行建模,推测,并在此基础上调整自己的决策。因此,该项工作对其他相关领域也有一定的借鉴意义,如人机协作,智能交通,金融分析等。尤其在人机协作环境中,如果 AI 能高效地推测人的习惯、喜好和目标,将大幅提升协作效率。
该项目团队主要从事棋牌类 AI「绝艺」相关研究。「绝艺」自 2016 年面世后,已四次夺得世界顶级围棋赛事冠军,包括 UEC 杯、AI 龙星战、腾讯世界人工智能围棋大赛、世界智能围棋公开赛等,并自 2018 年起无偿担任中国国家围棋队训练专用 AI。之前,团队在 1v1 麻将场景提出全新策略优化算法 ACH,已被 ICLR 2022 接收。
方法简介
结合 Bandit 思想,本文作者提出一种新的对手建模框架:Greedy when Sure and Conservative when Uncertain(GSCU)。GSCU 总体构思在于:当针对对手能获得更高收益时,那么 AI 就采用一个实时计算的 “激进” 策略(Greedy Policy)来针对对手;反之,AI 采用一个离线计算好的,最坏情况最好的,“保守”策略(Conservative Policy)。如下图所示,GSCU 包含两个离线训练模块,和一个在线测试模块。
离线训练模块一:对手策略 embedding 学习。该模块尝试学习一个 variational embedding 空间来表征任何一个可能的对手策略。该方法具体采用 Conditional Variational Autoencoder (CVAE)的架构:
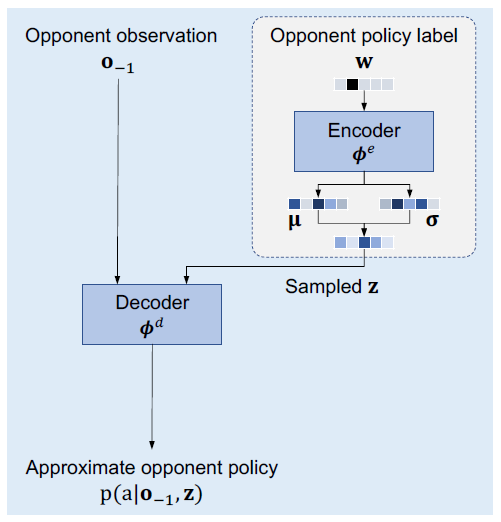
就像经典词向量方法 Word2Vec 可以提升后续各种 NLP 任务的效率, 我们的策略 embedding 学习方法 Policy2Emb 也有望提升所有需要对 policy 做表征的相关任务。
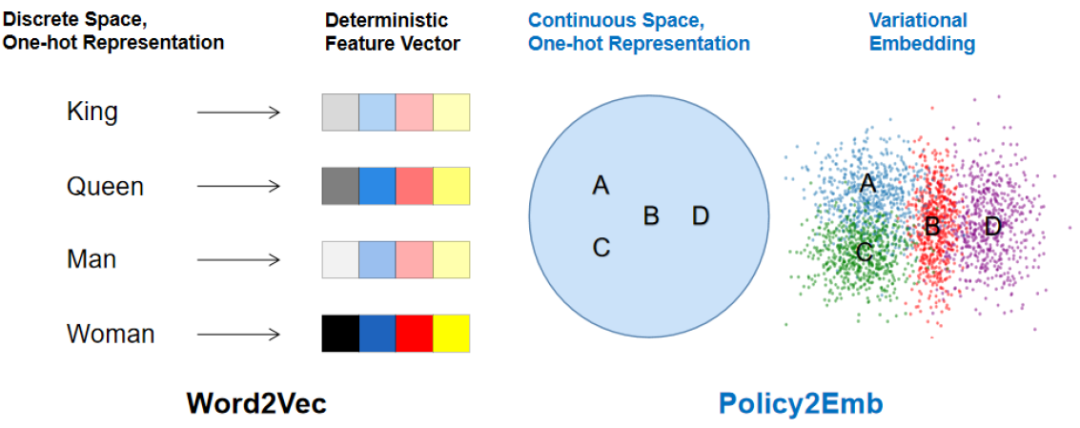
本文策略 embedding 学习方法 Policy2Emb 与经典词向量方法 Word2Vec 的一个对照
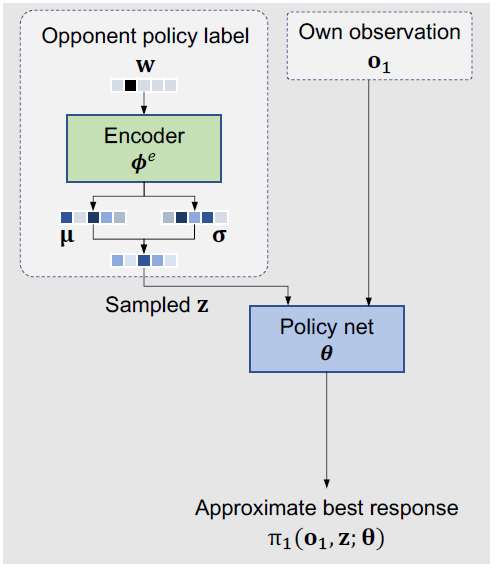
离线训练模块二:Conditional Reinforcement Learning (RL)。该模块尝试学习一个 conditional 策略,对于给定的一个对手策略的 embedding z,可以得到一个针对该对手的策略:
在线测试模块:在线对手策略 embedding 估计,保守 & 激进策略切换。该模块一方面尝试在线估计当前对手的策略 embedding,另一方面基于 bandit 算法 EXP3 在固定的 “保守” 策略和实时计算的 “激进” 策略两者之间动态切换:
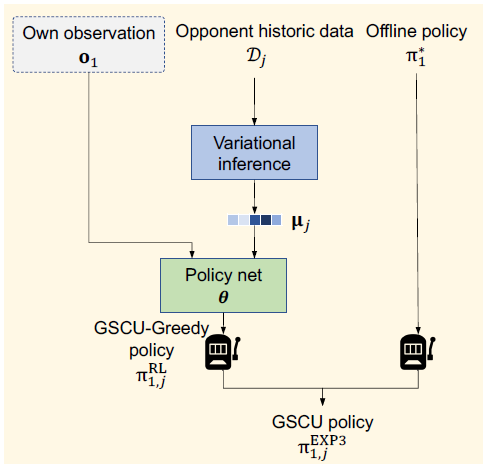
同时,我们可以证明:[1] “激进”策略的对战效果有下限保证; [2] 相比不做对手建模(也就是采用一个 “固定” 策略),我们的对手建模方法 GSCU 不带来负作用,并有很大可能带来正收益。
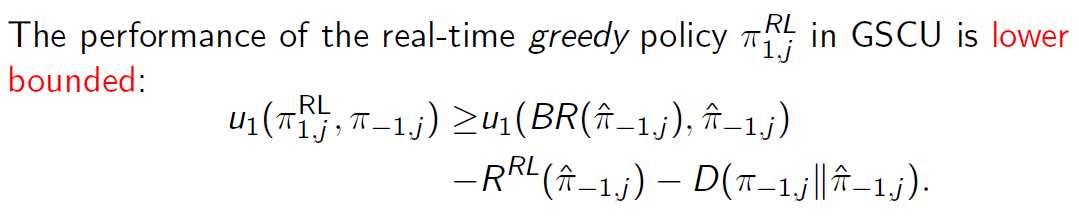

实验结果
在对比主流方法的基础上,GSCU 在经典扑克游戏 Kuhn poker 和 particle 环境 Predator Prey 上验证了其优越性:
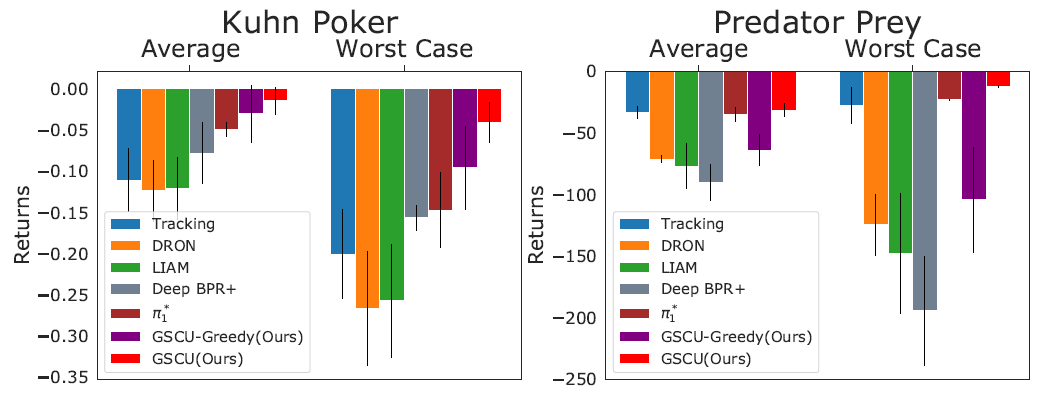
不同方法应对不同未知对手的平均性能和最差性能对比
策略 embedding 学习算法 Policy2Emb 的实验结果:
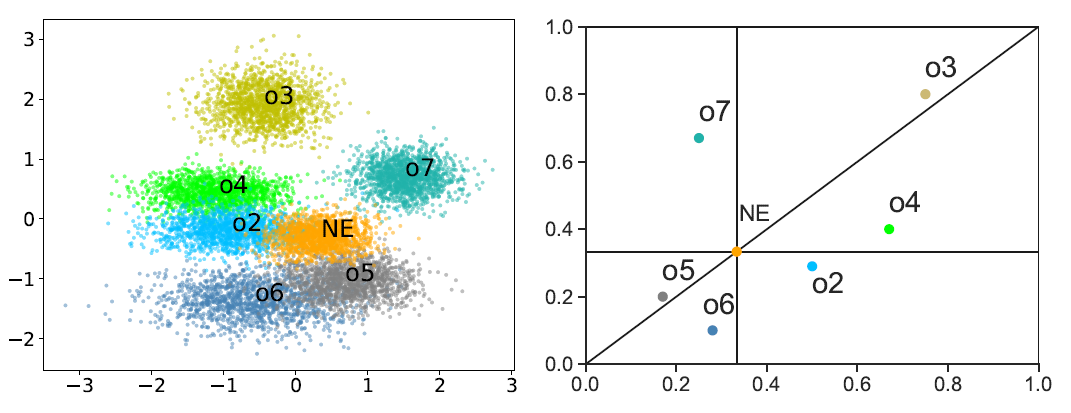
Policy2Emb 得到的策略 embedding 空间(左)和 Kuhn poker 真实的策略参数空间(右)
GSCU 中 conditional RL 的学习效果:
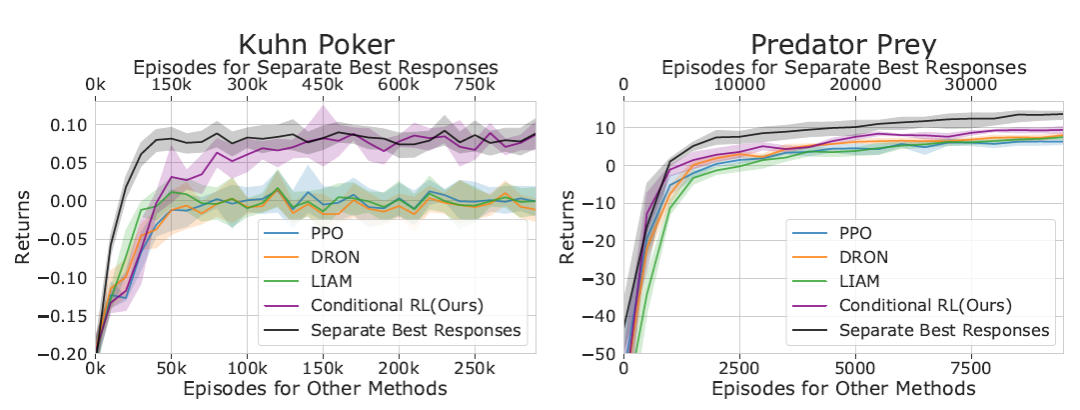
基于 Policy2Emb 学习到的对手策略 embedding,conditional RL 学习到的针对性策略可以高效应对不同的对手
GSCU 的在线对手策略 embedding 估计效果:
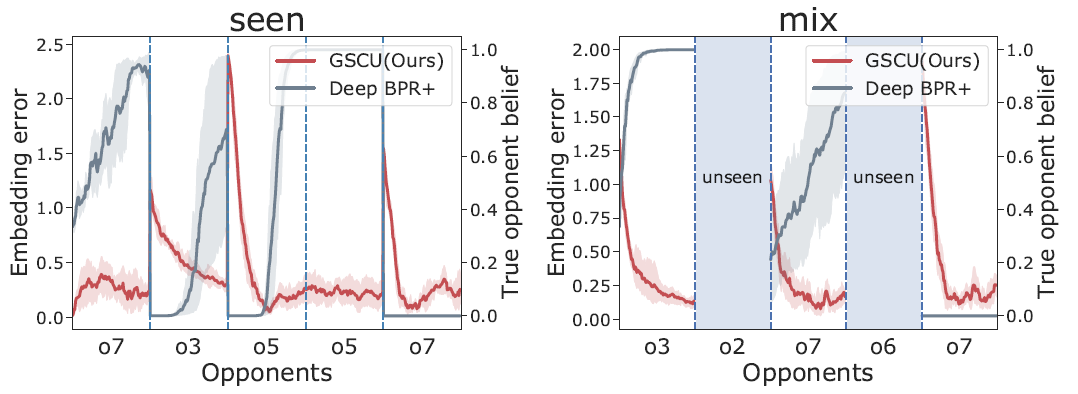
基于 Policy2Emb 学习到的 probabilistic decoder,GSCU 在策略 embedding 空间做 Bayesian inference 可以更好地估计对手策略。
编辑:于腾凯




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









