






 CMU和MetaAI的研究者开发了RoboAgent,通过7500条轨迹数据在38个任务中展示多种技能,包括复杂操作。MT-ACT框架结合世界先验知识和高效策略表示,使RoboAgent在低数据情况下表现出色,具有高泛化能力和可扩展性。
CMU和MetaAI的研究者开发了RoboAgent,通过7500条轨迹数据在38个任务中展示多种技能,包括复杂操作。MT-ACT框架结合世界先验知识和高效策略表示,使RoboAgent在低数据情况下表现出色,具有高泛化能力和可扩展性。

来源:机器之心
本文约1800字,建议阅读5分钟创造一个能够在各种情境中展现多种技能的机器人,似乎是一个遥不可及的目标,而 RoboAgent 的出现或许将这个目标拉近了一步。仅在 7500 条轨迹数据上进行训练,能够在 38 个任务中展示 12 种多样的操作技能,不仅限于拾取 / 推动,还包括关节对象操纵和物体重新定位,并能将这些技能推广应用于数百个不同的未知情境(未知物体、未知任务,甚至完全未知的厨房环境),这样的机器人够不够酷?

几十年来,创造一个能够在不同环境中操纵任意物体的机器人一直是一个遥不可及的目标。一部分原因是,缺乏多样化的机器人数据集,无法训练这样的智能体,同时也缺乏能够生成此类数据集的通用智能体。
为了突破这一困境,来自 CMU、Meta AI 的作者历时两年开发了一个通用的 RoboAgent。他们将重点放在开发一种高效的范例上,能够在实际数据有限的情况下训练一个能够获得多种技能的通用智能体,并将这些技能推广应用于多样的未知情境。

RoboAgent 由以下模块化构成 :
RoboPen - 一个采用通用硬件构建的分布式机器人基础设施,能够长期不间断运行;
RoboHive - 一个统一的框架,用于在模拟和真实世界操作中进行机器人学习;
RoboSet - 一个高质量的数据集,代表了各种场景中使用日常物品的多种技能;
MT-ACT - 一种高效的语言条件多任务离线模仿学习框架,通过在现有机器人经验的基础上创建多样的语义增强集合,从而扩大了离线数据集,并采用了一种新颖的策略架构和高效的动作表示方法,在有限的数据预算下恢复出性能良好的策略。
RoboSet:多技能、多任务、多模态数据集
构建一个能够在许多不同情境下推广的机器人智能体,首先需要一个具有广泛覆盖范围的数据集。鉴于扩大规模的努力通常会有所帮助(例如,RT-1 展示了约 130,000 条机器人轨迹的结果),因此需要在数据集有限的情况下理解学习系统的效率和泛化原则,低数据情境往往会导致过拟合。因此,作者的主要目标是开发一种强大的范例,可以在低数据情境下学习可推广的通用策略,同时避免过拟合问题。
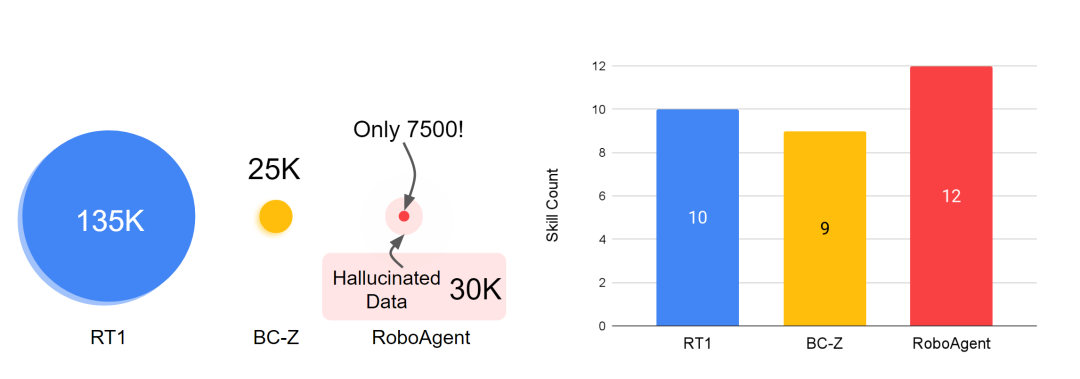
机器人学习中的技能与数据全景。
用于训练 RoboAgent 的数据集 RoboSet(MT-ACT)仅包括 7,500 条轨迹(比 RT-1 的数据少 18 倍)。该数据集提前收集并保持冻结状态。该数据集由在多个任务和场景中使用商品机器人硬件(Franka-Emika 机器人配备 Robotiq 夹具)进行人类遥操作收集的高质量轨迹组成。RoboSet(MT-ACT)在几个不同的情境下稀疏地涵盖了 12 种独特技能。数据通过将日常厨房活动(如泡茶、烘焙)分为不同的子任务来收集,每个子任务代表一个独特的技能。数据集包括常见的拾取 - 放置技能,还包括接触丰富的技能,如擦拭、盖盖子,以及涉及关节物体的技能。

MT-ACT:多任务动作分块 Transformer
RoboAgent 基于两个关键洞察在低数据情境下学习通用策略。它利用基础模型的世界先验知识以避免模式崩溃,并采用了一种新颖的高效策略表示,能够摄取高度多模态的数据。
1、语义增强:RoboAgent 通过对 RoboSet(MT-ACT)进行语义增强,将来自现有基础模型的世界先验知识注入其中。由此产生的数据集将机器人的经验与世界先验知识相结合,而无需额外的人力 / 机器人成本。使用 SAM 对目标物体进行分割,并在形状、颜色、纹理变化方面对其进行语义增强。
2、高效策略表示:由此产生的数据集是严重多模态的,包含丰富多样的技能、任务和情景。将动作分块方法适应于多任务设置,开发了 MT-ACT 一种新颖的高效策略表示,能够在低数据量情境中摄取高度多模态的数据集,同时避免过拟合问题。

实验结果
RoboAgent 比现有方法更具样本效率
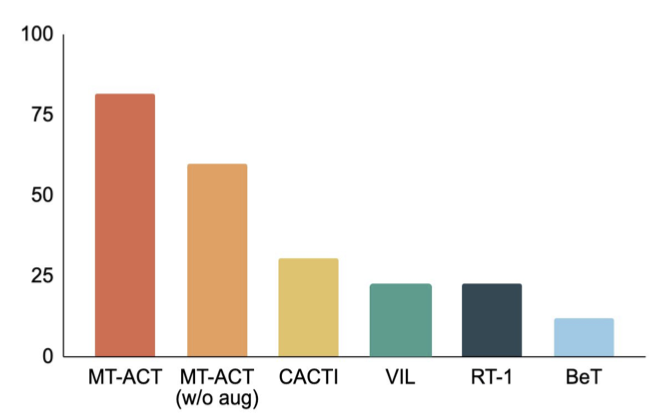
下图比较了作者提出的 MT-ACT 策略表示与几种模仿学习架构。作者仅使用了包括物体姿态变化和部分光照变化的环境变化。与之前的研究相似,作者将此归于 L1 泛化。从 RoboAgent 的结果,可以清楚地看到,使用动作分块来建模子轨迹明显优于所有基准方法,从而更证明了作者提出的策略表示在样本效率学习方面的有效性。
RoboAgent 在多个泛化层面上表现出色
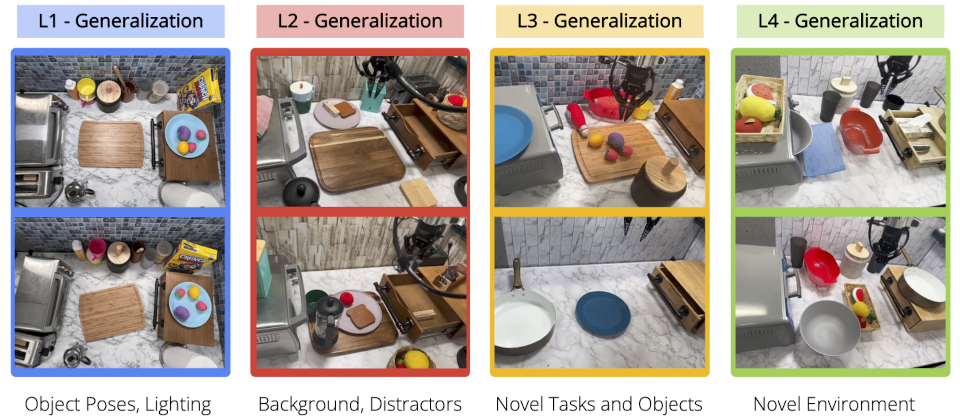
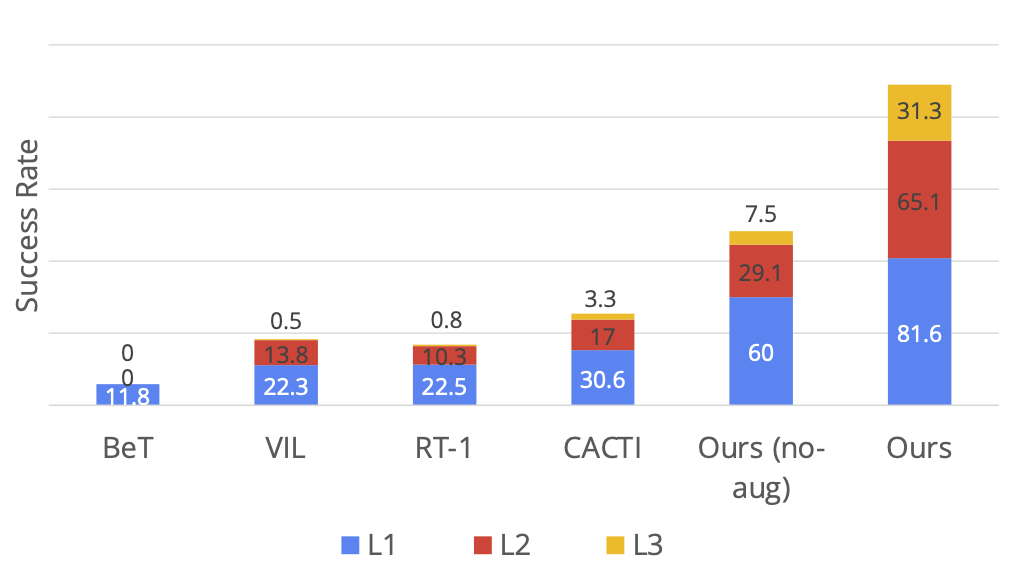
上图展示了作者在不同泛化层次上测试方法的结果。并且可视化了泛化级别,L1 表示物体姿态变化,L2 表示多样的桌面背景和干扰因素,L3 表示新颖的技能 - 物体组合。接下来,作者展示了每种方法在这些泛化层次上的表现。在严格的评估研究中,MT-ACT 比其他方法中表现显著优异,特别是在更困难的泛化层次(L3)上。
RoboAgent 具有高度的可扩展性
作者评估了在不断增加的语义增强级别下 RoboAgent 的表现。并且在一个活动(5 项技能)上进行了评估。下图显示,随着数据的增加(即每帧更多的增强),在所有泛化级别上性能显著提升。重要的是,对于更难的任务(L3 泛化)来说,性能提升要大得多。
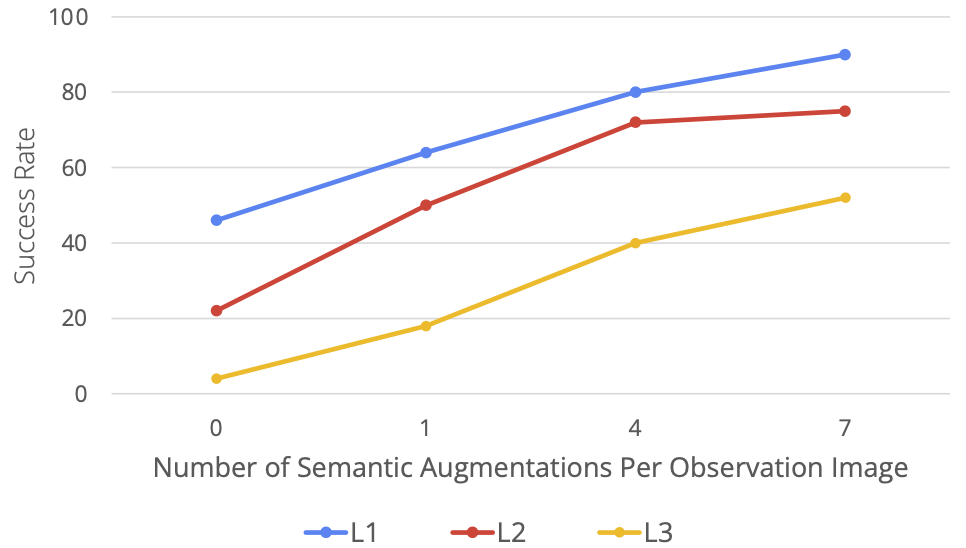
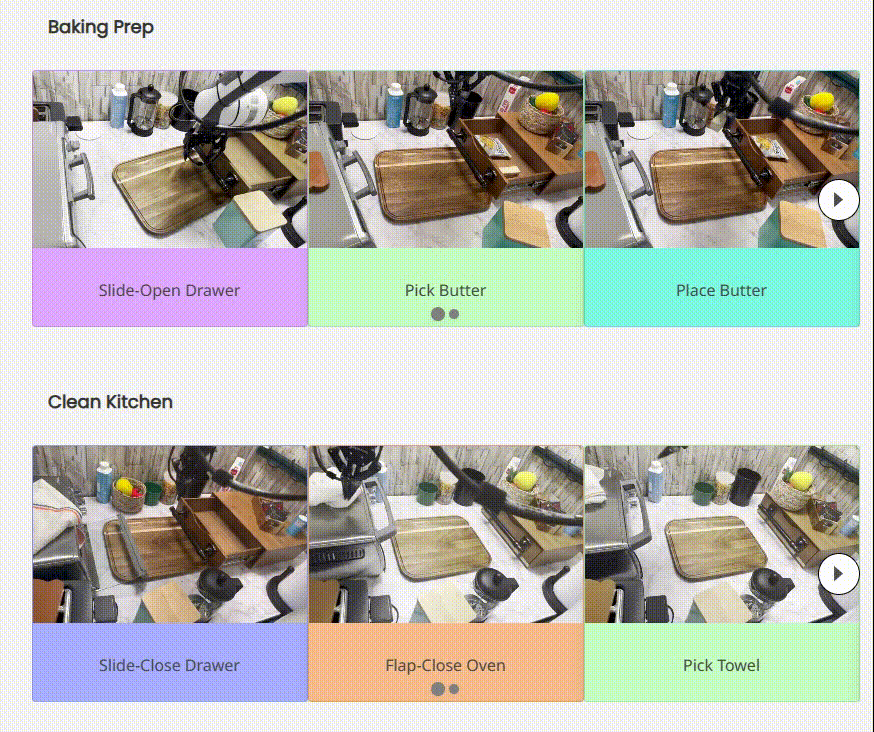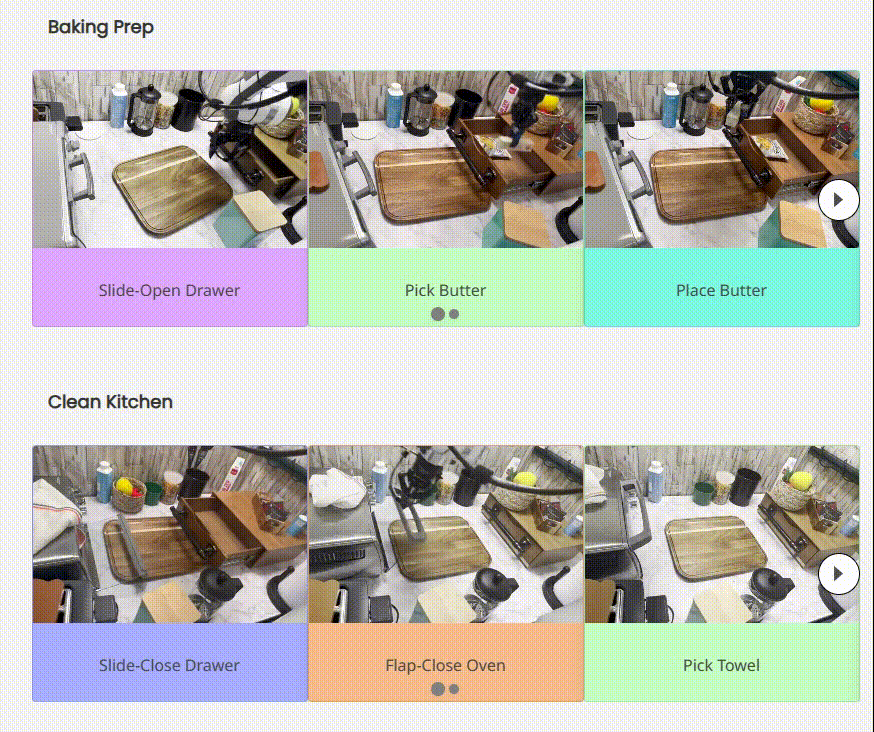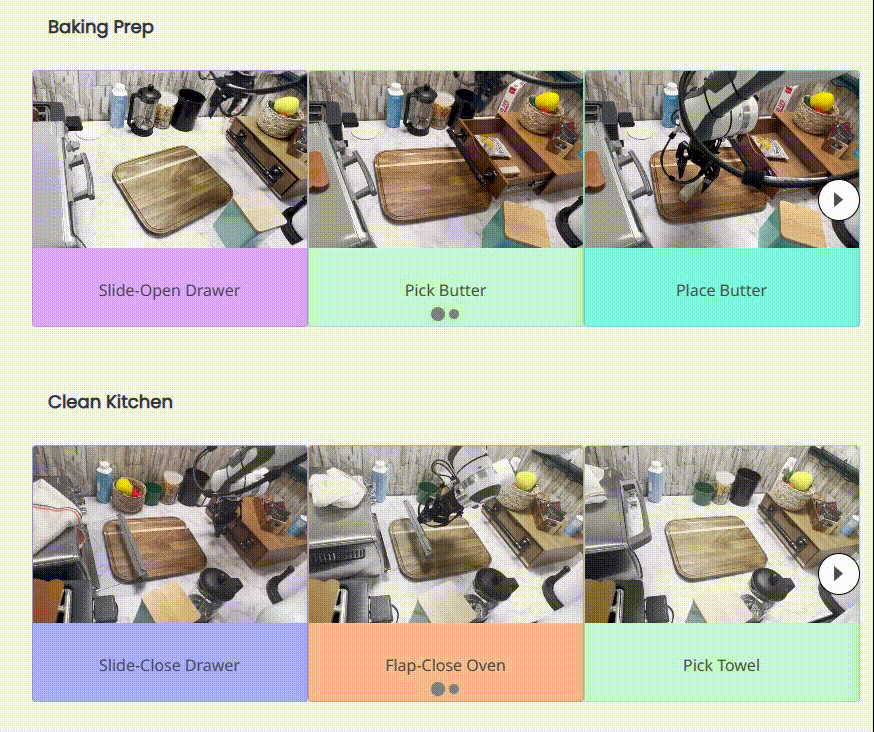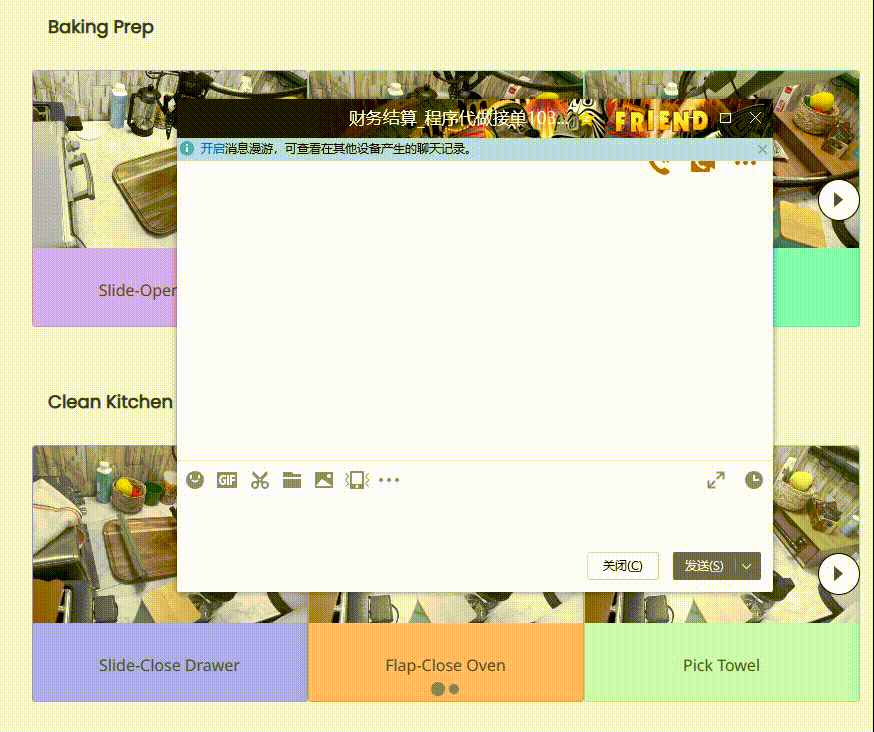
RoboAgent 能够在多样的活动中展示其技能
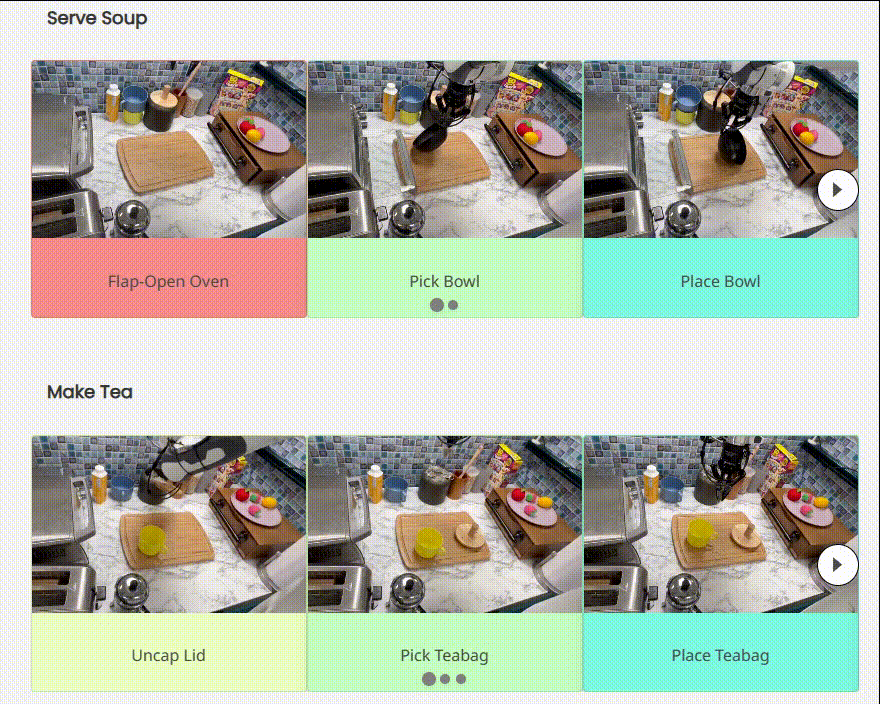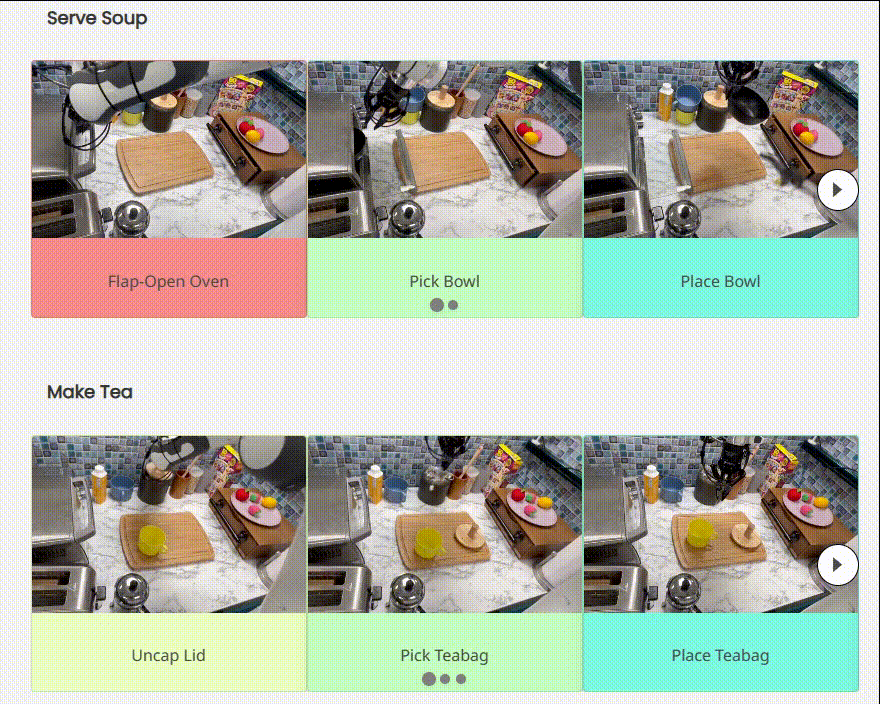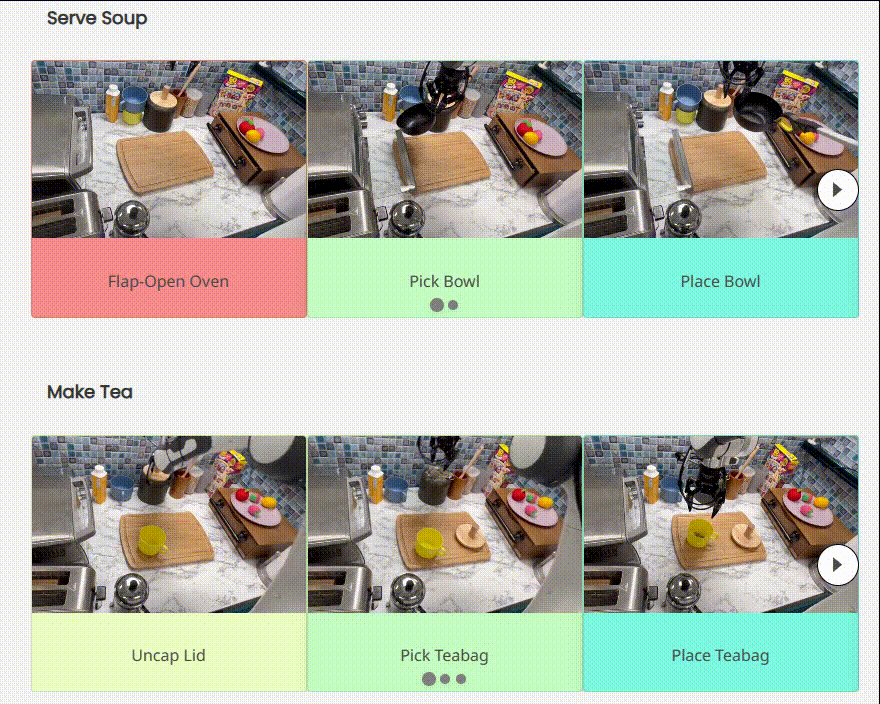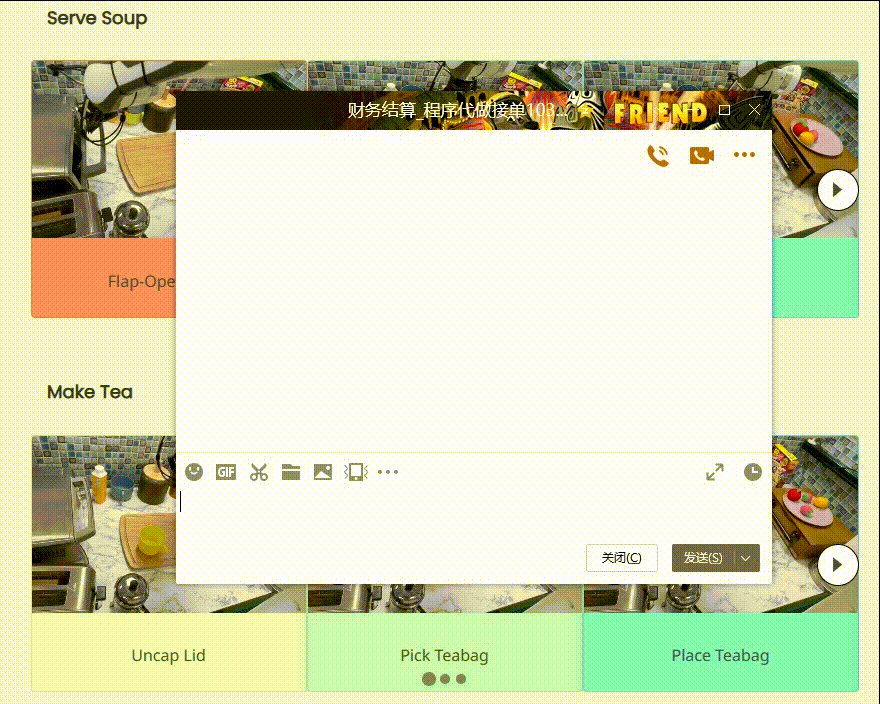

编辑:文婧



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









