







来源:Coggle数据科学
本文约1200字,建议阅读4分钟
本文将使用埃姆斯爱荷华州房屋数据集进行房价分析。在这个例子中,我们将比较使用不同的编码策略来处理分类特征时,HistGradientBoostingRegressor 的训练时间和预测性能。具体来说,我们将评估以下几种方法:
删除分类特征;
使用 OneHotEncoder;
使用 OrdinalEncoder,将分类特征视为有序、等距的量;
使用 OrdinalEncoder,并依赖于 HistGradientBoostingRegressor 估计器的原生类别支持。
我们将使用埃姆斯爱荷华州房屋数据集进行工作,该数据集包含数值和分类特征,其中房屋销售价格是目标变量。
步骤1:加载数据集
from sklearn.datasets import fetch_openml
X, y = fetch_openml(data_id=42165, as_frame=True, return_X_y=True)
# Select only a subset of features of X to make the example faster to run
categorical_columns_subset = [
"BldgType",
"GarageFinish",
"LotConfig",
"Functional",
"MasVnrType",
"HouseStyle",
"FireplaceQu",
"ExterCond",
"ExterQual",
"PoolQC",
]
numerical_columns_subset = [
"3SsnPorch",
"Fireplaces",
"BsmtHalfBath",
"HalfBath",
"GarageCars",
"TotRmsAbvGrd",
"BsmtFinSF1",
"BsmtFinSF2",
"GrLivArea",
"ScreenPorch",
]
X = X[categorical_columns_subset + numerical_columns_subset]
X[categorical_columns_subset] = X[categorical_columns_subset].astype("category")
categorical_columns = X.select_dtypes(include="category").columns
n_categorical_features = len(categorical_columns)
n_numerical_features = X.select_dtypes(include="number").shape[1]
print(f"Number of samples: {X.shape[0]}")
print(f"Number of features: {X.shape[1]}")
print(f"Number of categorical features: {n_categorical_features}")
print(f"Number of numerical features: {n_numerical_features}")步骤2:基准模型(删除类别变量)
from sklearn.compose import make_column_selector, make_column_transformer
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.pipeline import make_pipeline
dropper = make_column_transformer(
("drop", make_column_selector(dtype_include="category")), remainder="passthrough"
)
hist_dropped = make_pipeline(dropper, HistGradientBoostingRegressor(random_state=42))步骤3:OneHot类别变量
from sklearn.preprocessing import OneHotEncoder
one_hot_encoder = make_column_transformer(
(
OneHotEncoder(sparse_output=False, handle_unknown="ignore"),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
)
hist_one_hot = make_pipeline(
one_hot_encoder, HistGradientBoostingRegressor(random_state=42)
)步骤4:Ordinal类别变量
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = make_column_transformer(
(
OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=np.nan),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
# Use short feature names to make it easier to specify the categorical
# variables in the HistGradientBoostingRegressor in the next step
# of the pipeline.
verbose_feature_names_out=False,
)
hist_ordinal = make_pipeline(
ordinal_encoder, HistGradientBoostingRegressor(random_state=42)
)步骤5:原生类别支持
hist_native = HistGradientBoostingRegressor(
random_state=42, categorical_features="from_dtype"
)步骤6:对比模型速度和精度
from sklearn.model_selection import cross_validate
scoring = "neg_mean_absolute_percentage_error"
n_cv_folds = 3
dropped_result = cross_validate(hist_dropped, X, y, cv=n_cv_folds, scoring=scoring)
one_hot_result = cross_validate(hist_one_hot, X, y, cv=n_cv_folds, scoring=scoring)
ordinal_result = cross_validate(hist_ordinal, X, y, cv=n_cv_folds, scoring=scoring)
native_result = cross_validate(hist_native, X, y, cv=n_cv_folds, scoring=scoring)我们可以观察到,使用独热编码的模型明显最慢。这是可以预期的,因为独热编码为每个类别值(对于每个分类特征)创建了一个额外的特征,因此在拟合过程中需要考虑更多的分裂点。
理论上,我们预期原生处理分类特征的速度会略慢于将类别视为有序量('Ordinal'),因为原生处理需要对类别进行排序。
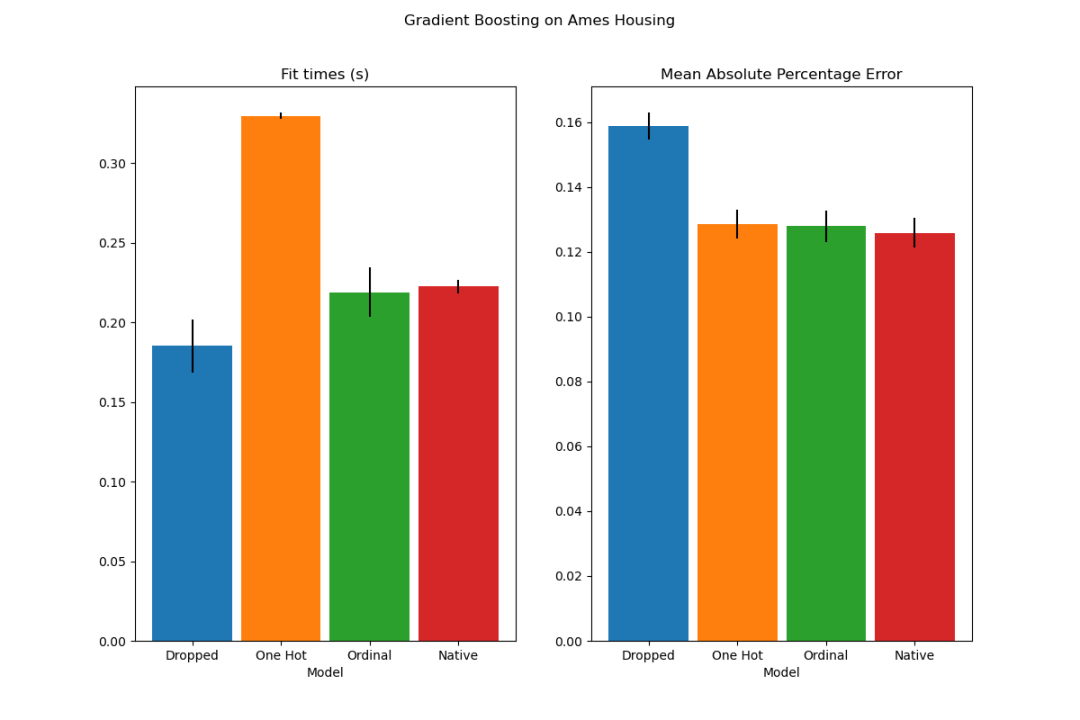
通常情况下,可以预期使用独热编码的数据会导致更差的预测结果,特别是当树的深度或节点数量受限时:使用独热编码的数据,需要更多的分裂点,即更深的树,才能恢复相当于原生处理中的一个单一分裂点所能获得的等效分裂。
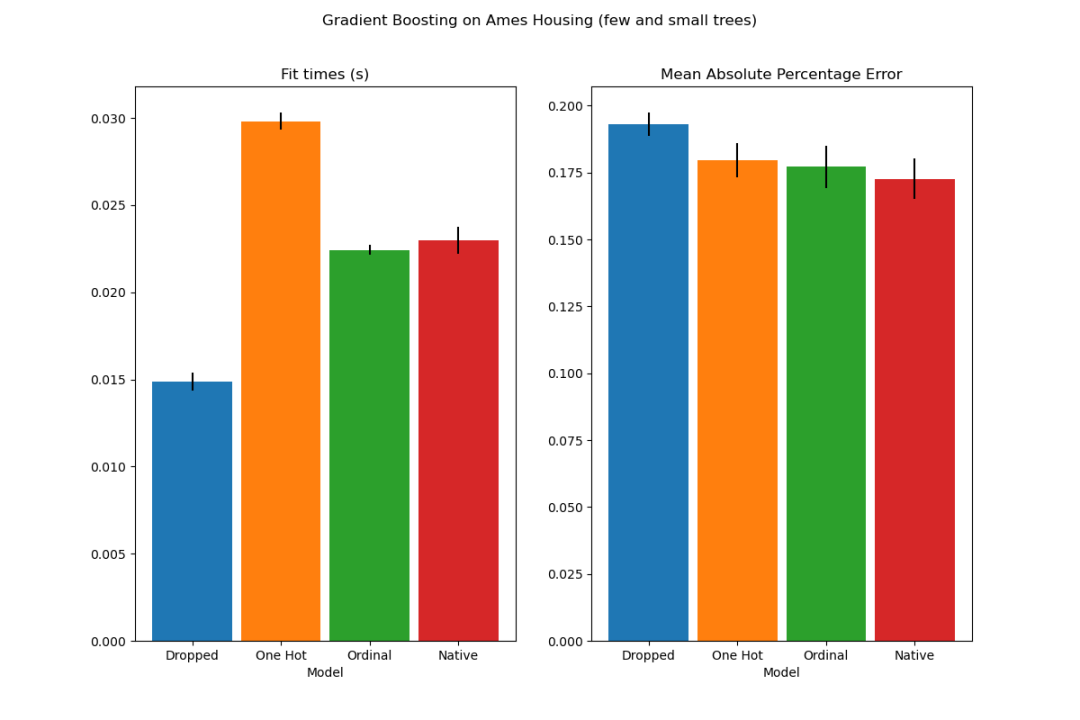
当类别被视为有序量时,这一点同样适用:如果类别为A..F,最佳分裂是ACF - BDE,则独热编码模型将需要3个分裂点(左节点中的每个类别一个),而非原生模型将需要4个分裂:1个分裂来隔离A,1个分裂来隔离F,以及2个分裂来从BCDE中隔离C。
代码链接:https://scikit-learn.org/stable/auto_examples/ensemble/plot_gradient_boosting_categorical.html
编辑:黄继彦















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









