







来源:PaperWeekly
本文约3200字,建议阅读6分钟本文提出一种时间可逆计算范式,并基于此开发了 T-RevSNN 模型。脉冲神经网络(Spike Neural Network,SNN)因其受大脑启发的神经元动态和基于脉冲的计算模式,被认为是一种低功耗的人工神经网络(Artifical Neural Network,ANN)替代方案。然而受限于 SNN 中的神经元的时空动态特性,SNN 的训练显存开销与运算时间均远远大于 ANN [1,2,3,4]。
为解决此问题,本文提出一种时间可逆计算范式,并基于此开发了 T-RevSNN 模型。与现有的 Spike-driven Transformer [5] 相比,T-RevSNN 的内存效率、训练时间加速和推理能效分别具有 8.6 倍、2 倍和 1.6 倍的显著提高。

论文标题:
High-Performance Temporal Reversible Spiking Neural Networks with O(L) Training Memory and O(1) Inference Cost
论文地址:
https://openreview.net/forum?id=s4h6nyjM9H
代码地址:
https://github.com/BICLab/T-RevSNN
1、背景
当前 SNN 模型的任务性能已在 ImageNet 上达到 80% 准确率 [6],已能够满足绝大多数实际任务场景,但是其训练难度仍然远高于同架构下的 ANN。如何降低 SNN 的训练难度是目前 SNN 领域的重点难题。SNN 的训练困难来源于其使用的 BPTT 训练算法。在训练时需存储每一层、每一时间步的神经元的激活值,即在训练时显存复杂度为 O(LT),其中 L 是层数,T 是时间步。例如,训练 10 时间步的脉冲 ResNet-19 比 ANN-ResNet-19 多需约 20 倍显存 [1]。
为解决这个问题,目前主流方法是解耦 SNN 训练过程与时间步。然而,它们中没有一个能够同时实现低廉的训练内存和低推理能耗,因为它们往往只在一个方向上进行优化。同时最近的研究显示,SNN 的时间反向传播对最终梯度影响小。既然如此,我们是否可以仅在关键位置保留时间前向,而关闭其他神经元的时间动态呢?
基于此,我们考虑仅在关键位置保留时间前向,关闭其他神经元的时间动态。我们设计了时间可逆的 SNN (T-RevSNN)。首先,为减少训练内存,仅在每个阶段的输出脉冲层激活时间动态,并实现时间传递的可逆性,避免存储所有神经元的膜电位和激活。
其次,关闭的脉冲神经元不进行时间动态,简化为不重用时间维度的参数,同时通过一次编码输入,将特征和网络分为 T 组,避免增加参数和能耗。第三,为提升性能,采用多级信息传递,重新设计 SNN 块,并调整残差连接以确保有效性。
2、本文贡献
我们的贡献包括:
1. 我们重新设计了 SNN 的前向传播,简单直观地同时实现了低训练内存、低功耗和高性能。
2. 我们在三个方面进行了系统设计,以实现提出的想法,包括关键脉冲神经元的多级时间可逆前向信息传递、输入编码和网络架构的分组设计,以及SNN块和残差连接的改进。
3. 在 ImageNet-1k 上,我们的模型在基于 CNN 的 SNN 上实现了最先进的准确性,同时具有最小的内存和推理成本,并且训练速度最快。与当前基于 Transformer 的 SNN 相比,即基于脉冲驱动的 Transformer,我们的模型在准确性上接近,而内存效率、训练时间加速和推理能效可以显著提高分别为 8.6×、2.0× 和 1.6×。
3、动机:尽可能少的梯度反传
我们设置了以下实验来分析哪些脉冲神经元的关键哪些不关键。同时由于遍历工作量太大,一般认为个典型的神经网络被分为四个阶段,每个阶段的特征层次各不相同。所以我们假设 SNN 中两个阶段交界处的时间信息传递很重要。为此我们设计了如下实验,首先在 CIFAR-10 上训练 Spiking Resnet,并将其设为基线,为了确定哪些神经元的时间梯度会对模型的训练过程产生显著影响,我们移除了可疑神经元的时间梯度,分为如下两种情况:
1. 案例1:我们保留每个阶段最后一层的时间梯度,并去除其他神经元的时间梯度;
2. 案例2:我们采取相反的方法,去除每个阶段的最终脉冲神经元的时间梯度,但保留其他神经元。
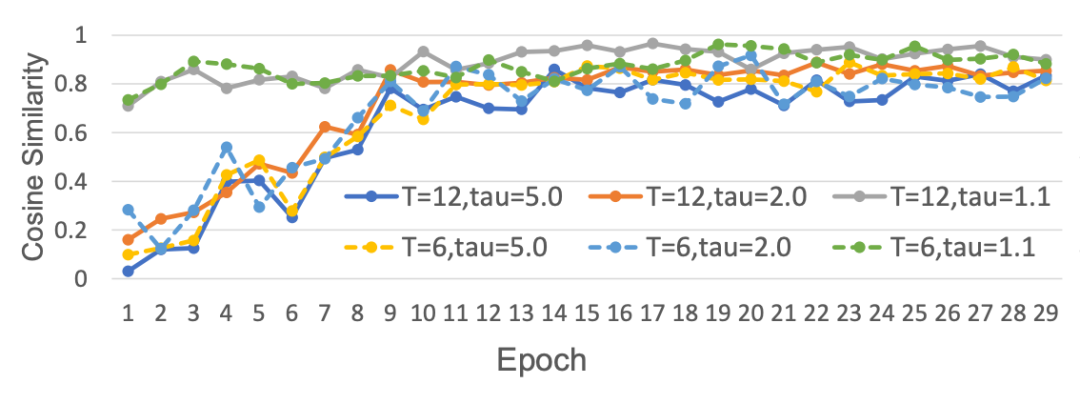
▲ 图1. 基线与案例1的余弦相似度随训练过程变化图
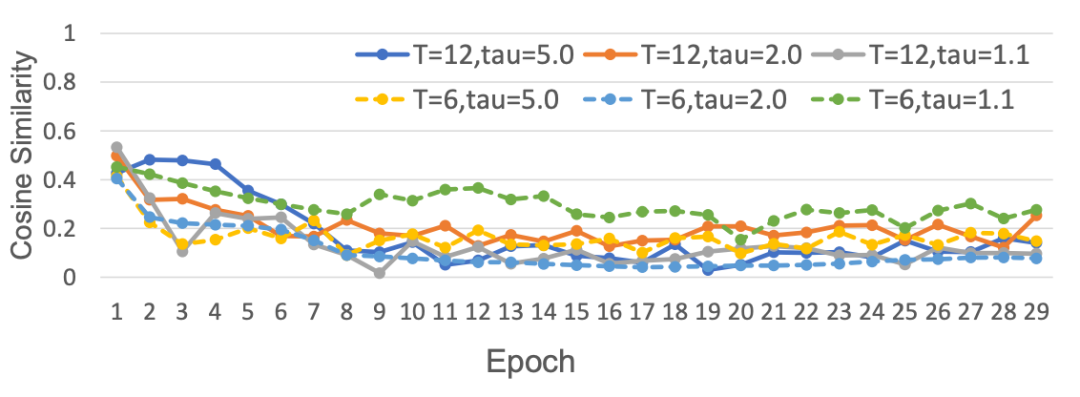
▲ 图2. 基线与案例2的余弦相似度随训练过程变化图
之后我们计算随着 epoch 增加基线和案例 1,2 之间的余弦相似度变化。相似度高表明该条件下的神经元的时间动态重要,相似度低则反之。最终结果如图1和图2所示。随着训练周期的增加,图 1(基线与案例 1 的比较)的相似度始终保持在高水平。相比之下,图 2(基线与案例 2 的比较)的相似度始终较小。这说明每个阶段最后一层的时间梯度比前面阶段的脉冲神经元更重要,我们称这些脉冲神经元为"关键神经元"。
4、方法
基于动机中的发现,我们设计了 Turn off / on 两种脉冲神经元,分别对应于在动机中找到的不关键或关键的神经元。
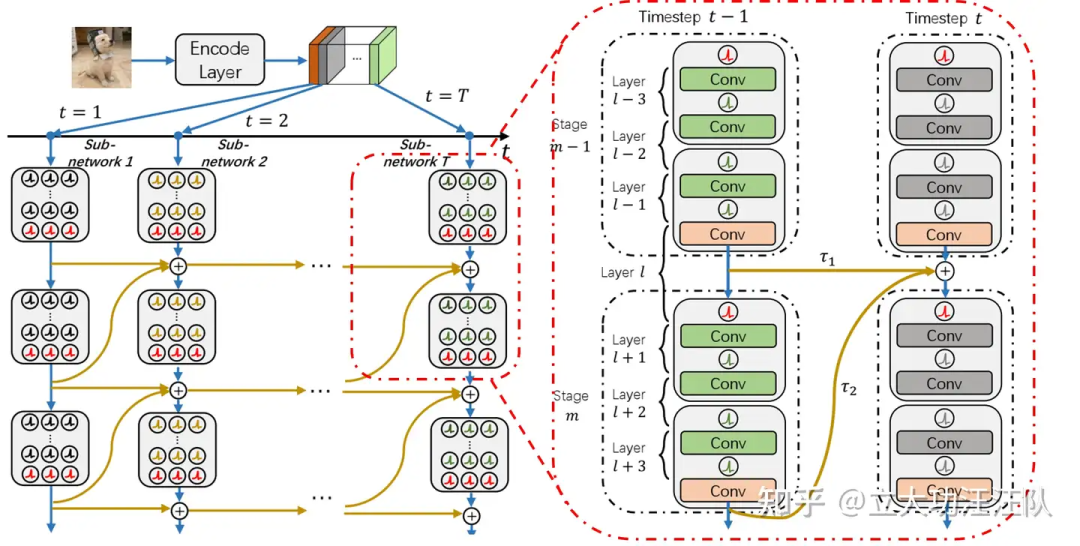
▲ 图3. 所提出的T-RevSNN的时间前向传播的示意图和网络结构细节
4.1 时间可逆脉冲神经元
T-RevSNN 中的脉冲神经元分为两种关键和不关键神经元。对于不关键神经元,即上图中的绿色部分神经元,我们将其时间维度的连接进行关闭。我们称这种关闭后的神经元为 Turn off 神经元。Turn off 神经元与一般的脉冲神经元唯一的区别是丧失了时间维度上膜电势的信息传递。其中 Turn off 脉冲神经元的前向传播可描述如下:
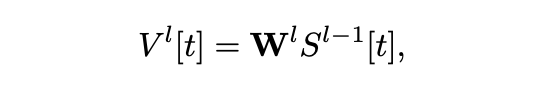
可以看到 Turn off 脉冲神经元的权重更新依赖于空间和时间梯度。对于 Turn on 脉冲神经元,其权重更新依赖于空间和时间梯度。受可逆性概念的启发,我们观察到其是自然可逆的。因此其前向传播可描述如下:
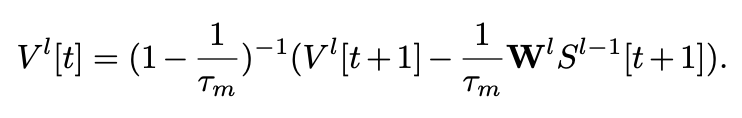
随后,可以在 和 之间建立可逆变换。这意味着在计算第一个时间步的梯度时,无需存储所有时间步的膜电位和激活值。我们只需要存储 。这减少了 SNNs 多时间步训练所需的内存。Turn on 神经元的时间复杂度与传统的 SNN 训练一致为 O(T)。
4.2 高性能的SNN训练框架
为了提升 SNN 的性能, 研究者们提出了许多方法,然而,上述方法不足以实现高精度的 SNN,为此我们首先引入了多层次连接训练框架 首先我们在相邻时间步的 SNNs 之间建立了更强的多层次连接(如图 3 所示)。我们将前一时间步的更深层次的高级特征纳入到当前时间步的信息融合中。通常,我们可以按照以下方式构建前向信息传递:
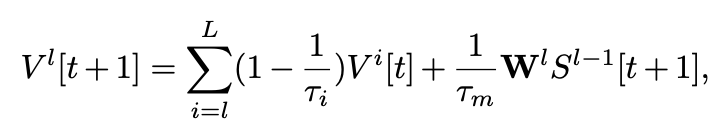
其次我们重写设计的基本的 SNN 模块。它由两个深度可分离卷积(DWConv/PWConv)和一个残差连接组成。我们去掉了所有批量归一化(BN)模块,转而去使用将网络中所有层的权重都进行了归一化的方法来稳定训练。之后我们使用了 ReZero 技术来增强网络在初始化后满足动态等距的能力和促进高效的网络训练。为了保证在推理中只发生加法运算,我们使用重参数化,将 ReZero 的缩放比例(即图 4 中的 α)合并到上一层的权重中。
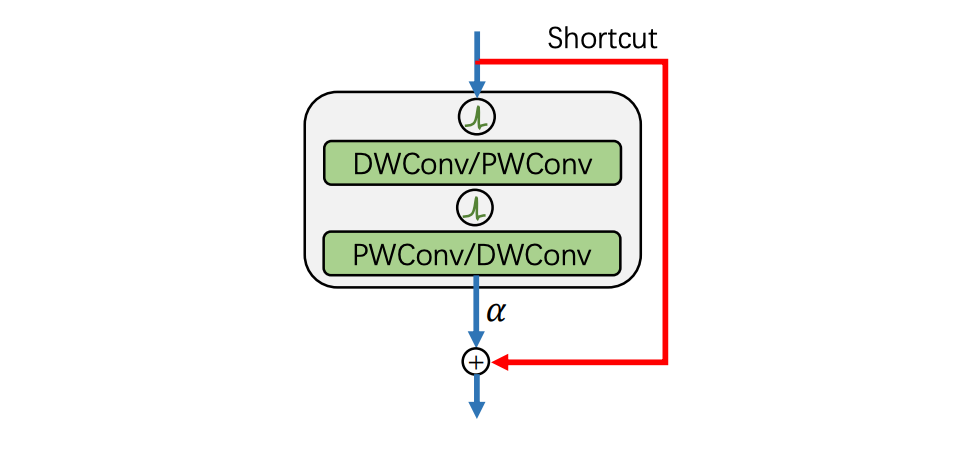
▲ 图4. 遵循ConvNext范式的基本的SNN模块
5、结果
5.1 不同训练方法复杂度分析
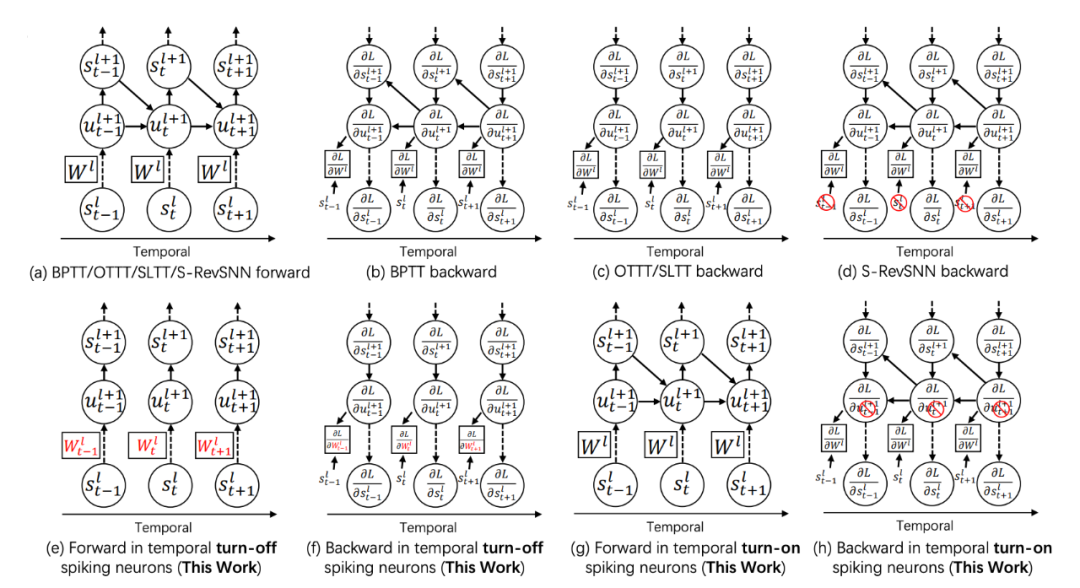
▲ 图5. T-RevSNN和其他SNN训练优化方法的前传和反传示意图
传统的 SNN 训练算法(STBP)在计算从最后一层的最后一个时间步的输出到第一层的第一个时间步的输入的梯度时所需的记忆和计算构成了训练 SNNs(脉冲神经网络)的记忆和时间复杂度。我们在表 1 和图 5 中分析了所提出的 T-RevSNN 和其他 SNN 训练优化方法 [2,3,4] 的训练内存和时间复杂度。
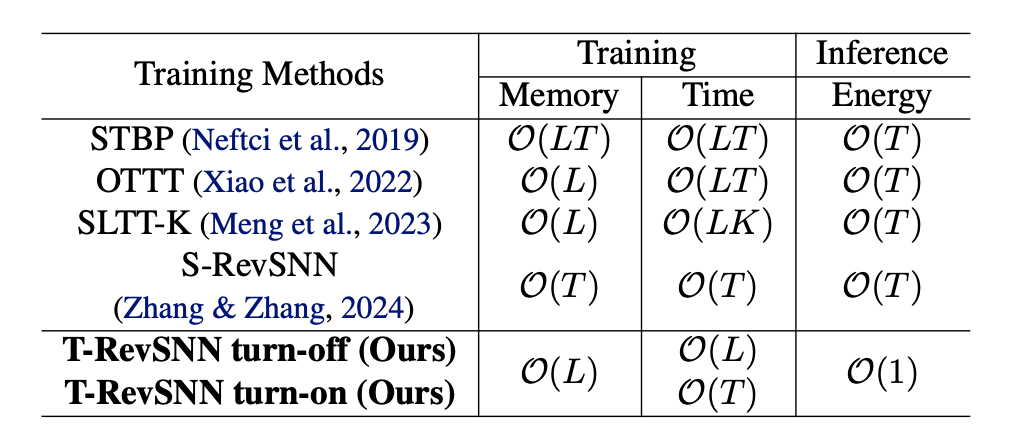
▲ 表1. 不同算法训练和推理的计算复杂度
5.2 消融实验
我们对 T-RevSNN 的不同时间步长和是否使用缩放残差连接进行了消融实验。
时间步长:在我们的设计中,我们将整个网络的参数分为T组子网络。在下表中,我们分析了不同的时间步长 T 对准确度、训练速度和内存的影响。由于我们固定了总参数数量,增加T意味着每个时间步的子网络变得更小。相应地,训练所需的内存会减少,但训练时间会相应增加。此外,可以看到准确性与时间步之间的关系并不是线性的。
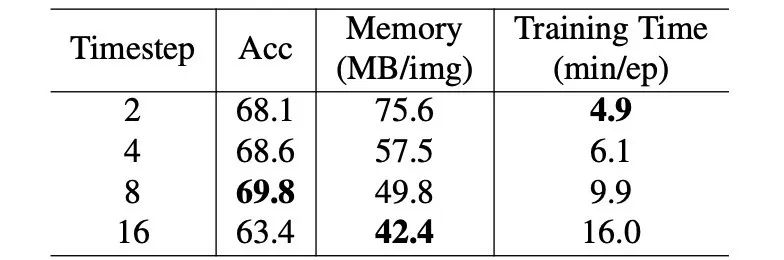
▲ 表2. 关于时间步长的消融实验
缩放残差连接:可以看到使用该技术有助于提高模型的收敛速度和最终准确度,如下表所示。
 ▲ 表3. 关于残差连接的消融实验
▲ 表3. 关于残差连接的消融实验
5.3 主要实验结果
T-RevSNN 在 ImageNet 上的结果如下所示。本文取得了 SNN 域中最快的训练速度和最低的内存消耗。
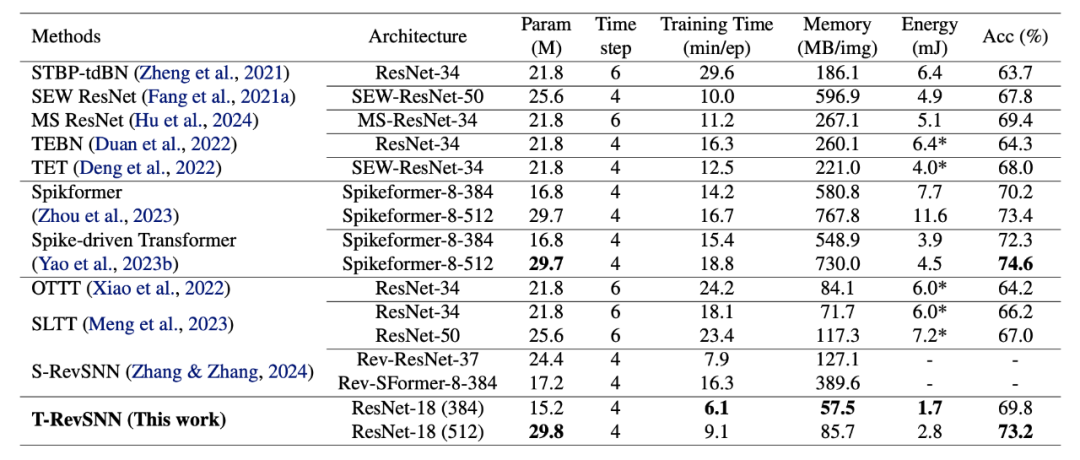
▲ 表4. 在大型ImageNet数据集上的实验
如上表所示,本文所提出的 T-RevSNN 以 85.7 MB/图片的内存消耗,和 9.1 分钟/周期的训练时间远低于脉冲 Transformer 和脉冲卷积模型。体现了 T-RevSNN 在训练速度、内存需求和推理功耗方面的显著优势,同时在性能上也具有竞争力。尽管准确率低于 Spike-driven Transformer,但我们认为这是由架构引起的差距,并且未来可以解决。全文到此结束,更多细节建议查看原文。
参考文献
[1] Fang W, Chen Y, Ding J, et al. Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence[J]. Science Advances, 2023, 9(40): eadi1480.
[2] Zhang H, Zhang Y. Memory-efficient reversible spiking neural networks[C]. Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 38(15): 16759-16767.
[3] Meng Q, Xiao M, Yan S, et al. Towards memory-and time-efficient backpropagation for training spiking neural networks[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 6166-6176.
[4] Xiao M, Meng Q, Zhang Z, et al. Online training through time for spiking neural networks[J]. Advances in neural information processing systems, 2022, 35: 20717-20730.
[5] Yao M, Hu J, Zhou Z, et al. Spike-driven transformer[J]. Advances in neural information processing systems, 2024, 36:64043--64058.
[6] Yao M, Hu J K, Hu T, et al. Spike-driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring the Design of Next-generation Neuromorphic Chips[C]. The Twelfth International Conference on Learning Representations.
编辑:于腾凯
校对:林亦霖
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









