







来源:PaperWeekly
本文约3000字,建议阅读5分钟
本文介绍了多模态大模型能揭示图像背后的深意。
论文题目:
Can Large Multimodel Models Uncover Deep Semantics Behind Images?
论文链接:
https://arxiv.org/abs/2402.11281v2
Github链接:
https://github.com/AnnaYang2020/DeepEval
Blogpost链接:
https://sites.google.com/view/DeepEval/%E9%A6%96%E9%A0%81
01 研究简介
图像的深意(Deep Semantics of Images)是指超越表面意义的深层内涵,传达更丰富和更深刻的信息,探究图像的本质。理解图像的深层语义是人类高水平智能的表现之一,也是人类从感知智能向认知智能探索的重要途径。然而,过去图片视觉理解的研究主要聚焦于图像的表面信息,如计数、物体属性、关系推理等。此前对深度语义的工作范围有限,往往局限于幽默、讽刺等方面,且缺乏全面深入的探索。
为了填补当前研究的空白,我们构建了 DeepEval,一个用于评估大型多模态模型(Large Multi-model Models,LMMs)视觉深意理解能力的综合基准。DeepEval 基准由一个数据集与三个递进的子任务构成。DeepEval 数据集是通过严谨的标注步骤人工标注而成,包含超过 1,000 个样本,每个样本包含一张漫画图片,以及人工标注的图像描述文本、图像标题文本和图像深意文本。
DeepEval 三个子任务层层递进,逐渐增强了对图像理解的要求,以全面评估模型在理解深层语义方面的能力,这三个任务分别是:细粒度描述选择任务、深度标题匹配任务和深意理解任务。图 1 展现了 DeepEval 数据集的示例包括人工标注的图像描述、人工标注的图像标题以及来自深度语义理解任务中对应的选择题。

一个来自 DeepEval 数据集的例子
DeepEval 基准是首个系统性地探索模型图像深意理解能力的评测指标,其数据集中包含多个图片类别。通过 DeepEval 基准,我们评估了 9 个前沿开源的多模态大模型和闭源的多模态大模型 GPT-4V(ison)。我们的评估显示,现有多模态大模型在图像深意理解能力方面与人类存在显著差距。例如,尽管 GPT-4V 在图像描述方面达到了与人类相当的表现,但在理解图像深意方面仍落后于人类 30%。
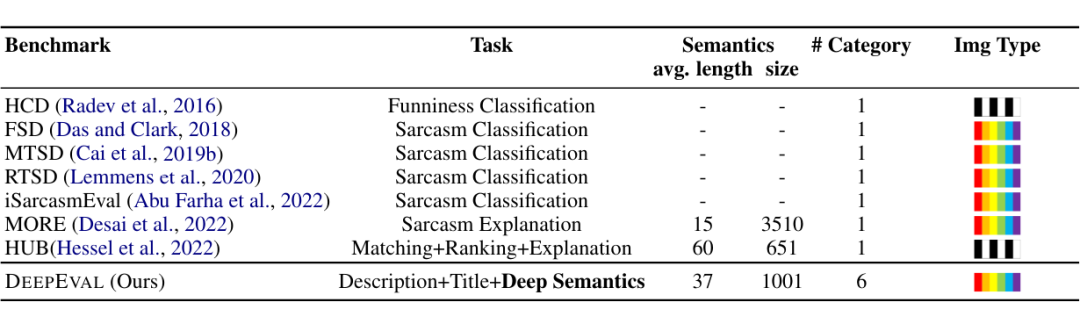
DeepEval 和先前相关数据集的特征和统计信息
02 数据集构建
2.1 图片收集
DeepEval 数据集中的图像数据是通过网络爬取从 Pinterest、Cartoon Movement 和 Google 搜索等多个网站获取的,共收集 1,001 张图像。这些图像涵盖了多种多样的类型,包时事讽刺、哲学表达、幽默和娱乐内容等。收集完成后,我们对图像进行了手动筛选步骤,从而去除重复和不清晰的图像。
2.2 数据标注
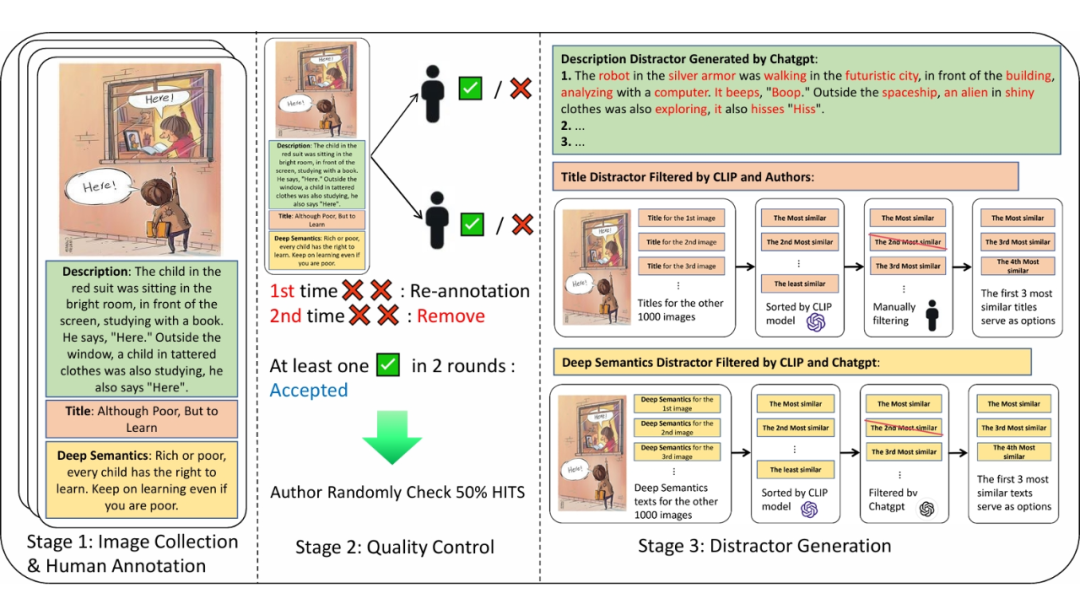
DeepEval 数据集构建过程示意图
2.2.1 注释者招募和指导
我们在网上论坛发布招募,邀请 50 多名具有学士学位及以上的申请者参加在线预标注培训和资格测试。根据他们的偏好,我们将他们分为标注员和检查员两组。在完成预标注培训后,我们进行资格测试以进行质量控制。最终,我们选出了 26 名标注员和 18 名检查员。
2.2.2 交叉核对注释(Cross-check Annotation)
标注过程主要分为三个阶段。在第一阶段,标注员从数据集中随机选择漫画图像,对其进行图像描述、标题和深意的标注。其中,描述和深意部分的字数应超过 80 个字符,而拟定的标题应超过 3 个字符,否则无法提交。完成此阶段后,每个图像将转化为一个四元组(图像、描述、标题、深层语义),标志着初始数据集的构建完成。
在第二阶段,检查员将审核已标注的图像。他们可以拒绝质量低下的标注。每个图像的标注由两名检查员审核。如果两名检查员都拒绝了该标注,我们会删除该标注并将图像重新放回数据集进行第二次标注。如果一张漫画图像在两轮标注中均被拒绝,说明该图像传达的深意不清晰,我们将删除该图像。在此阶段,我们还使用 Cohen's kappa 系数量化标注员之间的一致性,所有任务的平均得分为 0.701,表明存在较高的一致性。
在第三阶段,作者将进一步检查第二阶段的所有结果,以确保标注内容符合我们的标准。最终,我们获得了 1,001 个高质量的数据条目,每个条目都表示为一个四元组(图像、描述、标题、深层语义)。
2.3 选项生成
在获得图像标注后,我们将标注文本作为正确选项,并构建三个干扰选项。考虑到全部使用人工标注来构建干扰选项的高成本,我们在此部分利用了 CLIP 模型和 ChatGPT 模型的强大功能。
对于图像描述,我们使用 ChatGPT 模型生成保留原句结构但修改名词、动词、副词或形容词的句子,从而生成了更具干扰性的选项。对于图像标题和图像深意,我们使用 CLIP 模型计算图像与其他标题或深意文本之间的相似度,选取相似度较高的文本作为干扰项,以创建更具挑战性的选项。此外,作者会手动检查所有选项,删除引混淆的选项,以确保选择题在保持一定难度的同时有唯一正确答案。
2.4 子任务组成
为了探索多模态大模型在理解图像深意方面的能力,我们构建了一个包含三个递进的子任务的综合评估:
细粒度描述选择任务:评估模型准确识别图像表层细节的能力。
深度标题匹配任务:评估模型理解图像整体深意的能力。
深意理解任务:评估模型理解图像详细深意的能力。
可以看出,这三项任务逐步增强了对图像的理解,每个任务都建立在前一个任务的基础上,以加深理解的层次。在这三个任务中,每个问题都包含一幅图像和一个包含四个选项的选择题。然后,模型需要从四个选项中选择它认为最能传达描述、标题或深意的选项。
03 实验
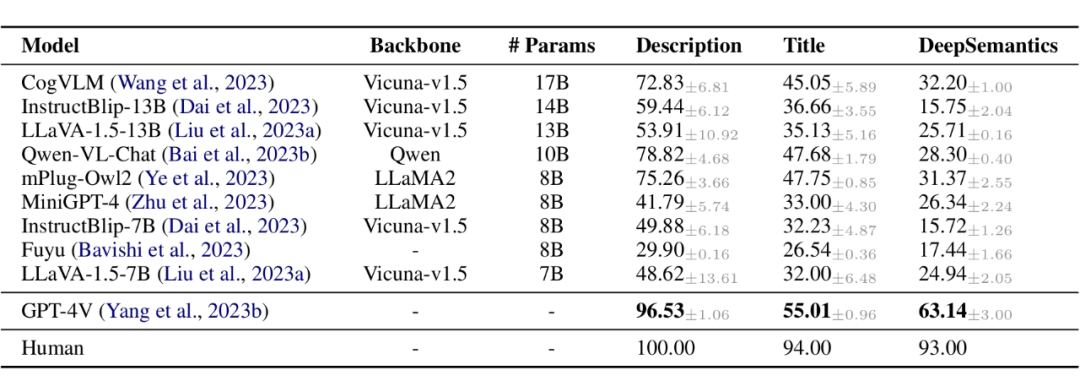
基线测试包括 DeepEval 的三种提示的平均准确度(以百分比(%)表示)和方差
表 2 展示了 DeepEval 对多模态大模型及人类能力的评测结果。其中包括 LLaVA-1.5,MiniGPT-4,mPLUG-Owl2,CogVLM,Qwen-VL,InstructBlip2,Fuyu开源多模态大模型和 GPT-4V(ison)闭源多模态大模型。
从以上评测结果中,我们发现,所有评估的模型在深意理解方面的准确率显著低于它们在图像描述方面的表现,且几乎所有模型在深意理解方面的准确率也低于在深度标题匹配任务中的表现。这表明理解图像的深意对这些模型来说是一个重大挑战,而关注深意的细节则进一步增加了复杂性。此外,我们注意到,这些模型的能力明显弱于人类的表现,在深意理解方面最为明显,可见模型在图片深意方面还有很大的提升空间。
04 分析
(1)通过分析模型在不同类别图像中的理解能力,我们可以明确模型在特定图像类别中的优缺点。不同模型在各图像类别中的表现如图 3 所示,三张雷达图展示了模型在理解图像描述、标题和深意方面的能力。可以发现,模型在各类别中对图像描述的理解较为均匀,对图像深意的理解则各有不同。
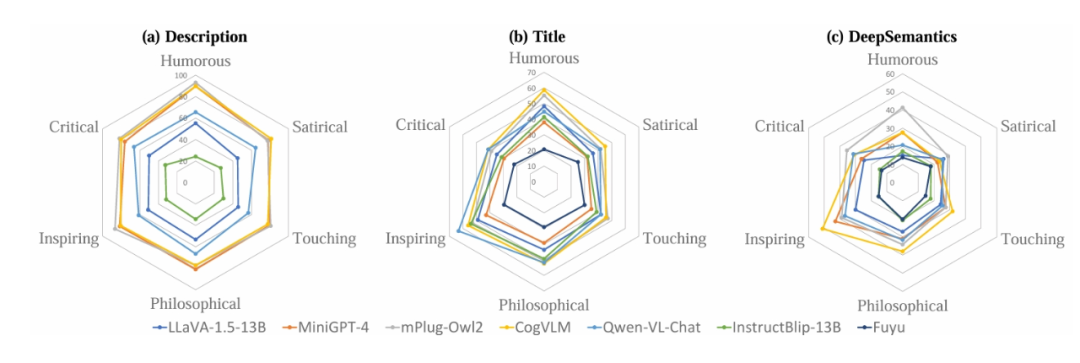
雷达图代表了我们三个任务中几种典型模型在理解不同类别图像方面的表现
(2)我们还探索图片表层描述对模型图片深意理解能力的影响。结果如表 3 所示,通过在推理阶段加入由模型生成或标注而成的图像表层描述来启发模型,确实能够激发并增强其对深层语义的理解能力。
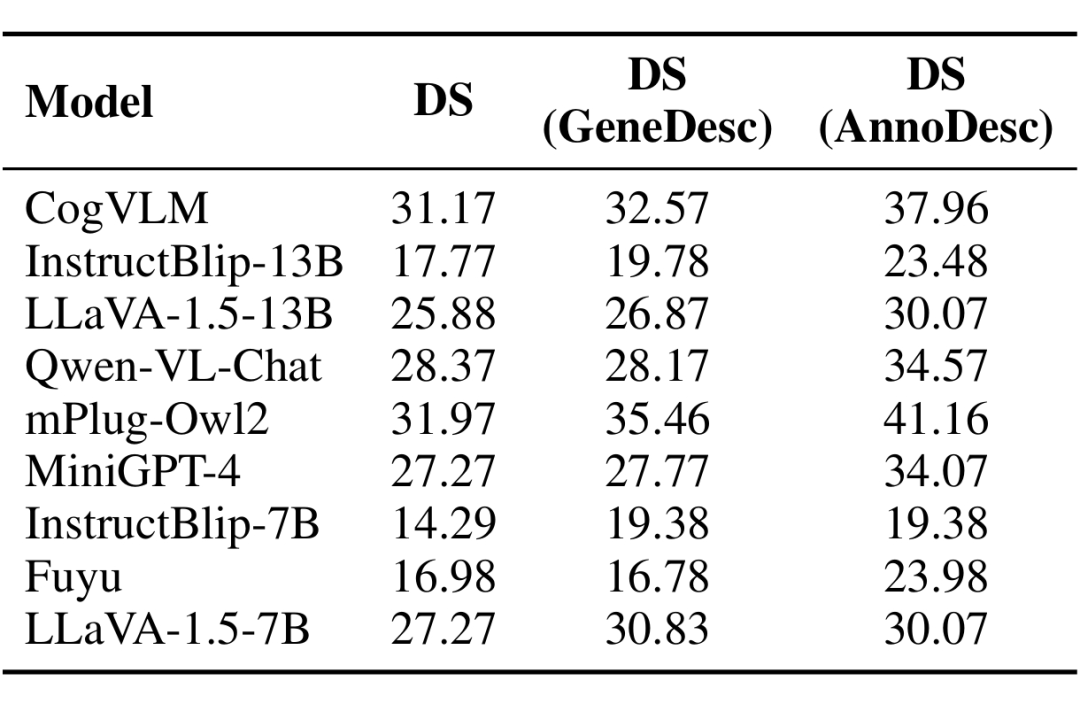
该模型在融合各种图像描述的同时理解图像深意的能力。“DS”代表“深意”,“GeneDesc”表示模型生成的图像描述。“AnnoDesc”表示标注的图像描述
(3)参数数量的增加对模型的图像深意理解能力有积极的影响,参数多的模型通常表现有更好的性能,且表现的性能也更加稳定,结果由图 4 所示。
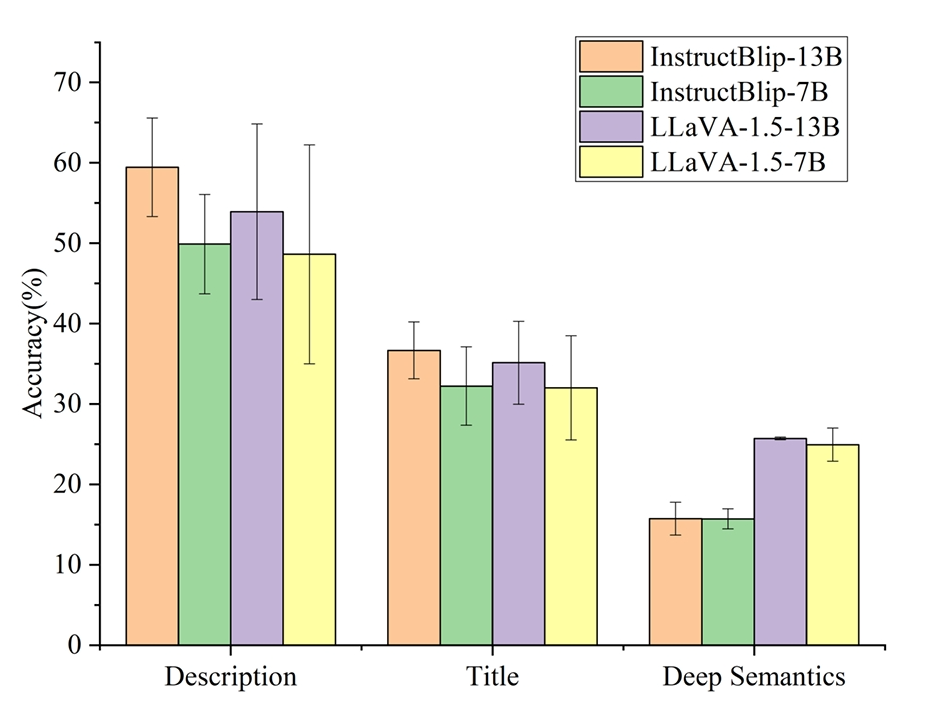
Instructlip-13b 与 Instructlip-13b 和 LLaVA-1.5-13B 与 LLaVA-1.5-7B 的平均准确度和方差结果的比较
05 总结
我们提出了 DeepEval,它是一个用于评估多模态大模型视觉深层语义理解能力的基准。DeepEval 包括一个严谨标注的数据集和三个递进的子任务:细粒度描述选择任务、深度标题匹配任务和深意理解任务。
我们对多个多模态大模型进行了评估,揭示了 AI 与人类在理解图像深意方面的显著差距。进一步分析表明,多模态大模型对图像的深意理解能力会受图像类别、模型参数量、图像表层描述多个方面的影响。现有模型在视觉深意理解方面与人类相比仍有很长的路要走。我们希望所提出的数据集和任务能够为 AI 实现对图像深意的更深理解铺平道路。
编辑:王菁
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









