







作者:Adva Nakash Peleg
翻译:付雯欣
校对:赵茹萱
本文约3100字,建议阅读10分钟
本文将从实际项目需求出发,手把手带你了解LLM。使您的LLM引擎无状态和无服务器化
在编写LLM引擎时,您可能会遇到“会话”或“对话”的概念。在这种情况下,我们需要将这些会话/对话的状态提取到可以在需要时加载的外部位置。这个外部位置可以是分布式缓存或数据库,可以从多个引擎工作节点访问。
以下是提取会话或对话状态的步骤:
步骤1)提取会话/对话历史。为了使LLM将过去的消息纳入考虑,我们需要传递会话历史。会话历史是一个需要保存在分离的位置,并在需要时加载到提示中的状态。
步骤2)提取LangChain状态。LangChain库通过设计是有状态的。它在内存中保留了许多信息,这些信息提供了如何继续、到目前为止发生了什么等提示。我们遇到的一个实际例子是使用“用户澄清工具”:当LangChain决定使用此工具时,它需要进行澄清,并从完全相同的位置以及完全相同的状态继续执行。
为了解决这个问题,我们需要深入分析LangChain代码,并重写部分内容,将状态序列化和反序列化到外部位置。
这并不是件容易的事情,但好消息是,这是可以做到的!
步骤3)提取您的项目/应用程序中非LLM的状态。如果您有不与LLM相关的状态,则也需要在需要时提取和加载。
例如,这里是引擎工作流程:
从用户获取请求-> 从外部缓存资源加载状态 -> 处理请求 -> LLM -> 将状态保存到外部缓存资源 -> 返回响应给用户。
下面的图也描述了这一过程:
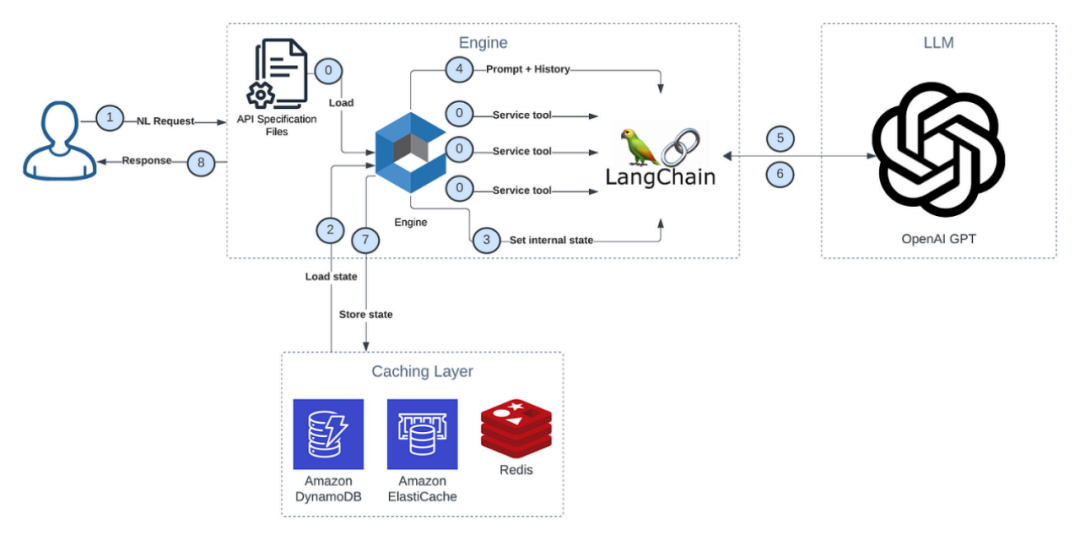
图:引擎的主要工作流程
安全性,安全性,安全性
好的,现在我们进入了令人担忧的部分。
如何在您无法控制的情况下保护安全性呢?
答案是:尽可能获取尽可能多的控制权!
首先,熟悉LLM的OWASP十大安全风险总是一个好主意:https://owasp.org/www-project-top-10-for-large-language-model-applications/
以下是我根据经验提供的一些额外tips:
Tip1:避免越狱(Jailbreak)
在LLM中,越狱的概念指的是绕过您LLM项目的内置功能和安全保护,将其用于用户个人利益的行为。我们发现这确实是一件很难避免的事情。令人惊讶的是,LLM很容易忽略您的规则,以满足用户的请求。根据您的项目的不同,您可能需要在采取保护措施时进行特殊的处理。
以下是一些可能的做法:
使用系统提示的指令和规则
使用系统提示功能为您的LLM提供规则,以避免越狱。系统提示的规则比用户提示的规则更为严格,更不容忽视。然而,从我们的测试来看,这并不能提供100%的保护。
使用白名单技术限制LLM的功能
如果您的LLM功能使用LangChain工具,可以确保每个请求都使用您的工具之一。这确保请求与您的内置功能相关联。
以下是两个例子:
有效的prompt
“创建一个名为‘user1’的用户”:
这使用了一个负责用户功能API的工具。我们可以允许这个请求。
无效的prompt
“美国第一任总统是谁?”
我们的项目中没有工具可以回答这个问题,然而LLM可以根据自己的知识来回答。我们必须阻止这个请求。
Tip2:加强模型访问的安全性
托管和提供LLM服务可能会很昂贵,并且有其配额限制。因此,尽可能加强对LLM的访问控制是明智的做法,除了使用OpenAI密钥外,还可以考虑网络加固和访问限制。
在我们的项目中,当使用Azure OpenAI时,我们可以将LLM部署在隔离的网络环境中(Azure虚拟网络),并且仅限于使用引擎 —— 在我们的情况下是AWS引擎Lambda,位于专用VPC(Amazon虚拟私有云)中。LLM与引擎之间的连接也通过VPN进行保护。
Tip3:阻止冒犯性回应
想象一下,您的LLM项目开始诅咒和冒犯您的客户。这听起来像是一场噩梦,对吧?我们应该尽一切努力避免这种情况发生。
可以采用的两种方法是:
OpenAI的内容管理: https://platform.openai.com/docs/guides/moderation
Azure OpenAI的内容过滤:
https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/content-filter?tabs=warning%2Cpython
Tip4:向LLM引擎添加控制点/挂钩
假设您有一个需要LLM依次执行多个动作的项目。在这种情况下,向LLM引擎添加“检查点”可能是一个不错的主意,以确保这些动作是有意义的。
这里有一个具体的例子:
在我们的项目中,LLM需要使用自然语言输入生成API和参数,执行产品的API,分析响应并在需要时进行重试,然后返回格式化的结果。
在这种情况下,一个主要的控制点出现在生成API并执行之前。我们可能希望验证API、参数,甚至对输入进行清理,以避免提示注入。另一个控制点可能出现在将结果返回给客户之前 —— 用于验证响应的内容和格式。
Tip5:不要忽视通常的安全准则
请记住,这个项目面临与任何其他项目相同甚至更多的风险。许多人希望获得免费的LLM访问权限,包括那些仍然想访问被禁止的资产的攻击者等。
重点关注以下几点:
身份验证和授权。验证访问您新产品的人员是否有许可。
租户隔离。保持与往常一样的租户隔离措施。不要让您的新LLM项目成为访问敏感信息的后门。
防火墙和限流。控制您收到的请求数量,不要让您的项目被滥用,确保您的LLM可以处理负载。
其他需要考虑的事情
我们几乎准备好投入生产了!
以下是需要考虑的一些事项:
反馈
您如何知道您的LLM项目在生产中表现良好?您如何知道客户是否对他们获得的结果满意?考虑设置一个反馈机制可能是明智的选择,这样您可以跟踪结果并持续改进项目。
模型评估
在发布之前,您如何知道您的模型是否按预期运行?如何确保对模型应用的更改是可信的?模型评估是一个复杂而重要的主题。
您应该考虑以下几点:
添加测试以覆盖LLM项目的基本功能。这些测试可能与您过去的经验有所不同(记得我们提到过如何在新的非确定性世界中导航吗?)。例如,您可能无法使用精确的单词匹配,但应该做的是测试核心功能。在我们的项目中,我们可以提供一个使用案例,然后验证是否选择了正确的API以及正确的主要参数。
使用LLM来评估您自己的LLM引擎。LLM评估器可以生成使用案例,提供预测结果,然后与实际结果进行比较。非常酷,对吧?
法律问题
请记住,当开始一个新的LLM计划时,您可能需要与法律团队联系,确保您所做的事情是合法的。
这包括从客户那里获取使用AI/Gen-AI的同意,避免使用客户数据来训练LLM,如何强制您的LLM托管平台不保留有关对话的任何信息,以及如何符合法规(如GDPR等)。
旅行终点
下面是我们本次LLM产品的架构,涵盖了这篇博客里说的所有内容:
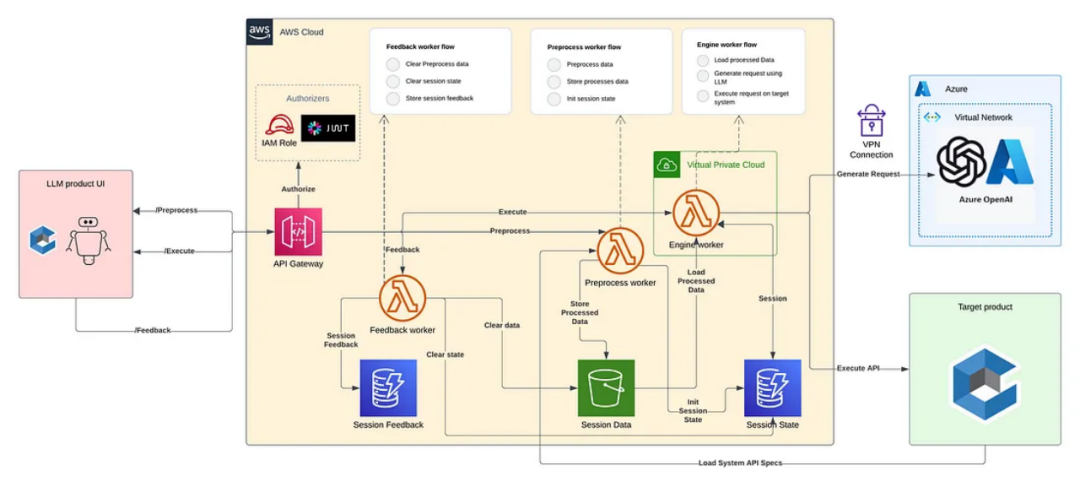
图:完整解决方案
这是我们LLM产品架构的主要组成部分:
GPT模型:托管在Azure OpenAI上,通过我们的AWS Virtual Private Cloud (VPC) 进行安全访问。
预处理工作器:托管在AWS Lambda上。在会话开始时准备数据(API规范文件),并将处理后的数据保存在外部存储中。
引擎工作器:托管在AWS Lambda上。加载处理后的数据和状态,使用我们的LLM生成相关的API请求,并在产品上执行操作。
反馈工作器:托管在AWS Lambda上。收集和存储会话反馈,并清除会话状态。
这标志着我们旅程的结束。或许这只是一个新的开始? ☺
原文标题:An LLM Journey: From POC to Production
原文链接:
https://medium.com/cyberark-engineering/an-llm-journey-from-poc-to-production-6c5ec6a172fb
编辑:黄继彦
译者简介

付雯欣,中国人民大学统计学专业硕士研究生在读,数据科学道路上的探索者一枚。小时候梦想做数学家,现在依旧着迷于数据背后的世界。热爱阅读,热爱遛弯儿,不停感受打开生命大门的瞬间。欢迎大家和我一起用概率的视角看世界~
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU
点击“阅读原文”拥抱组织


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









