







来源:多模态机器学习与大模型
本文约1800字,建议阅读10分钟
本文介绍了三种常见的多模态场景(雷达光学、RGB 仰角和 RGB 深度)中评估 DeCUR,并展示其持续改进,无论架构如何,以及多模态和模态缺失设置。Decoupling Common and Unique Representations for Multimodal Self-supervised Learning
作者: Yi Wang , Conrad M Albrecht , Nassim Ait Ali Braham, Chenying Liu , Zhitong Xiong , and Xiao Xiang Zhu
作者单位:
德国慕尼黑工业大学,德国航空航天中心遥感技术研究所,慕尼黑机器学习中心
论文链接:
https://arxiv.org/pdf/2309.05300
代码链接:
https://github.com/zhu-xlab/DeCUR
简介
大多数现有多模态自监督方法仅学习跨模态的通用表示,而忽略模态内训练和模态独特的表示。文中提出了一种简单而有效的多模态自监督学习方法,即解耦通用和独特表示(DeCUR)。通过减少多模态冗余来区分模态间和模内嵌入,DeCUR 可以整合不同模态之间的互补信息。文中在三种常见的多模态场景(雷达光学、RGB 仰角和 RGB 深度)中评估 DeCUR,并展示其持续改进,无论架构如何,以及多模态和模态缺失设置。
研究动机
特征嵌入维度可以分为跨模态常见维度和模态独特维度。在训练过程中,计算两种模态之间的公共维度和唯一维度的归一化互相关矩阵,并将公共维度的矩阵驱动到恒等,而将唯一维度的矩阵驱动到零。因此,常见的嵌入在不同模态中保持一致,而模态独特的嵌入则被排除。
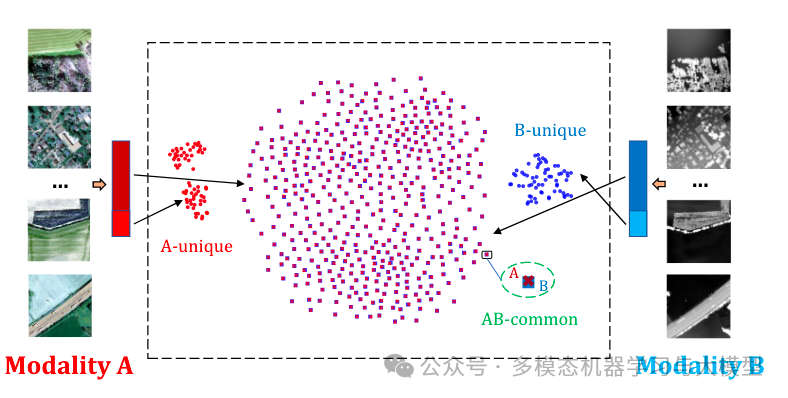 图 1:t-SNE 可视化的两种模态的解耦共同和独特表示
图 1:t-SNE 可视化的两种模态的解耦共同和独特表示
然而,简单地推开独特的维度将导致崩溃,因为这些维度无法学习任何有用的信息。因此,除了跨模态学习之外,文中还包括模态内学习,利用所有嵌入维度并将同一模态的两个增强视图之间的互相关矩阵驱动到同一模态。这种模态内组件不仅通过让独特的维度在一种模态内学习有意义的表示来避免崩溃,而且还通过更强大的模态内知识来增强跨模态学习。图 1 提供了学习表示的潜在空间的 t-SNE可视化,其中每种模态的共同和独特嵌入,以及模态之间的模态独特嵌入都被很好地分开。
论文贡献
提出了 一种简单而有效的多模态自监督学习方法 DeCUR,将不同模态之间的常见和独特表示解耦,并增强模内和模间学习。对于ConvNet主干网,采用可变形注意力的简单调整来进行模态信息特征学习。
通过丰富的实验和涵盖三个重要多模态场景的综合分析来评估 DeCUR,证明其在多模态和模态缺失环境中的有效性。
方法
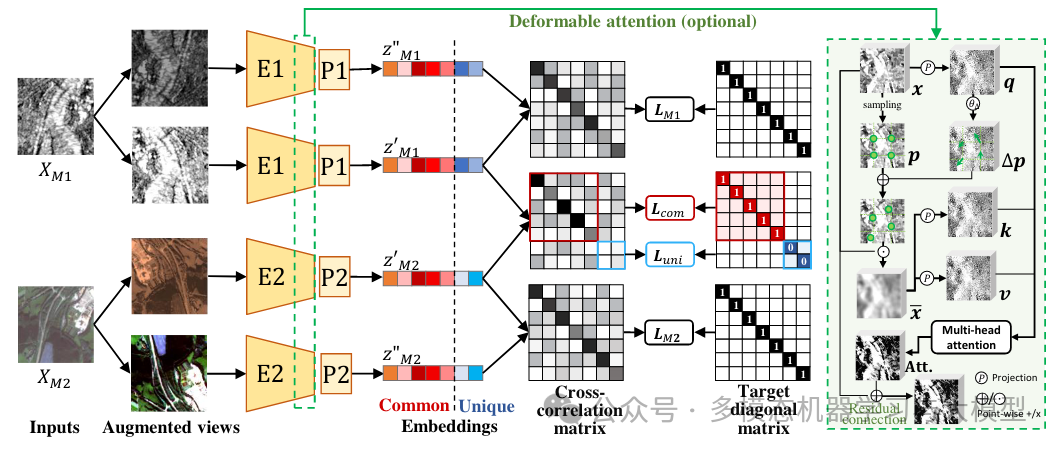 图 2:DeCUR 的结构。M 1 和M 2 代表两种模态。来自每种模态的两个增强视图被馈送到特定于模态的编码器(E1,E2)和投影仪(P 1,P 2)以获得嵌入Z。
图 2:DeCUR 的结构。M 1 和M 2 代表两种模态。来自每种模态的两个增强视图被馈送到特定于模态的编码器(E1,E2)和投影仪(P 1,P 2)以获得嵌入Z。
图 2 展示了 DeCUR 的总体结构。作为 Barlow Twins 的多模态扩展,DeCUR 通过从模内/跨模态角度减少增强视图的联合嵌入空间中的冗余来执行自监督学习。本文的主要贡献在于简单的损失设计,以解耦跨模态的有意义的模态独特表示。
解耦common和独特的表示
如图 2 所示,将来自每种模态的输入的两批增强视图输入模态特定的编码器和投影。批量归一化应用于嵌入,使得它们沿批量维度以均值为中心。然后使用这些嵌入来计算模态之间/模态内的互相关矩阵以进行优化。
互相关矩阵 给定两个嵌入向量 ,它们之间的互相关矩阵 C 表示为:
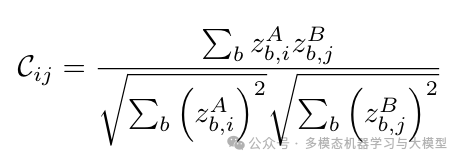
跨模态表示解耦 在跨模态情况下,计算来自不同模态的两个嵌入之间的相关矩阵C,如图2中的和。而大多数多模态自监督学习算法仅考虑它们的共同表示,w文中明确考虑模态唯一表示的存在,并在训练期间将它们解耦。具体来说,将总嵌入维度 K 分为 和 ,其中 分别存储公共和唯一表示。跨模态的通用表示应该是相同的(图 2 中的红色部分),而模态特定的独特表示应该是去相关的(图 2 中的蓝色部分。
跨模态通用表示的冗余减少损失如下:
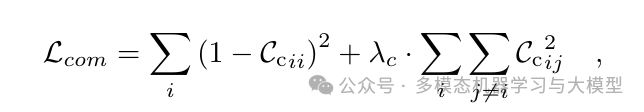
模态唯一表示的冗余减少损失如下:
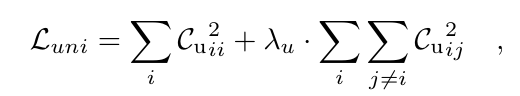
模内表示增强 为了避免跨模态训练中解耦的唯一维度的崩溃,以及增强模内表示,文中引入了涵盖所有嵌入维度的模内训练。对于每种模态,互相关矩阵 (或 )是根据嵌入向量Z'_{M1}$ 和 Z''{M1}(或 $Z'{M2} 和 )的全维度生成的。模态内表示的冗余减少损失如下:
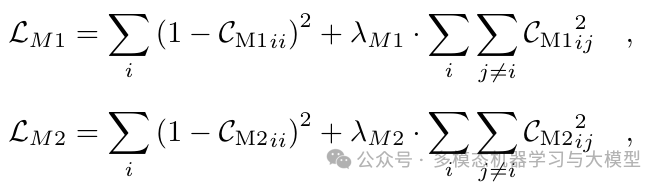
结合跨模态常见和独特损失以及模内损失,DeCUR 的总体训练目标为:
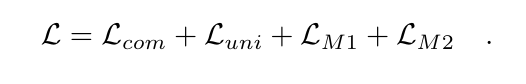
模态信息特征的可变形注意力
除了 DeCUR 损失设计之外,文中还采用可变形注意力来帮助 ConvNet 模型关注模态信息区域。DAT 和 DAT++ 中提出了可变形注意模块,以在特征图中重要区域的指导下有效地建模特征标记之间的关系。具体可参照原文。
实验结果
表 2:使用冻结编码器和在 GeoNRW 上进行全面微调的 RGB-DEM 迁移学习结果 (mIoU)(左:多模态;右:仅 RGB)。
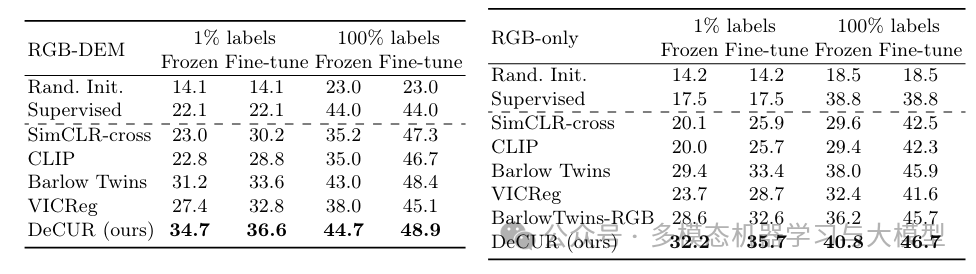 表 3:SUN-RGBD 和 NYU-Depth v2 上的 RGB 深度微调结果。
表 3:SUN-RGBD 和 NYU-Depth v2 上的 RGB 深度微调结果。
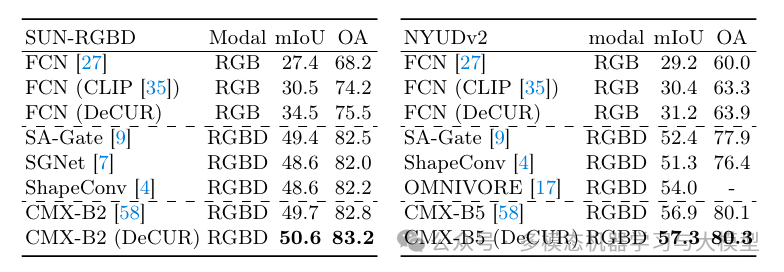
表 4:可变形注意模块的消融结果 (mAP)。
编辑:王菁
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









