







来源:专知
本文约1000字,建议阅读5分钟
决策变换器(Decision Transformers)最近作为离线强化学习(RL)的一种新颖且引人注目的范式出现,通过自回归的方式完成轨迹。
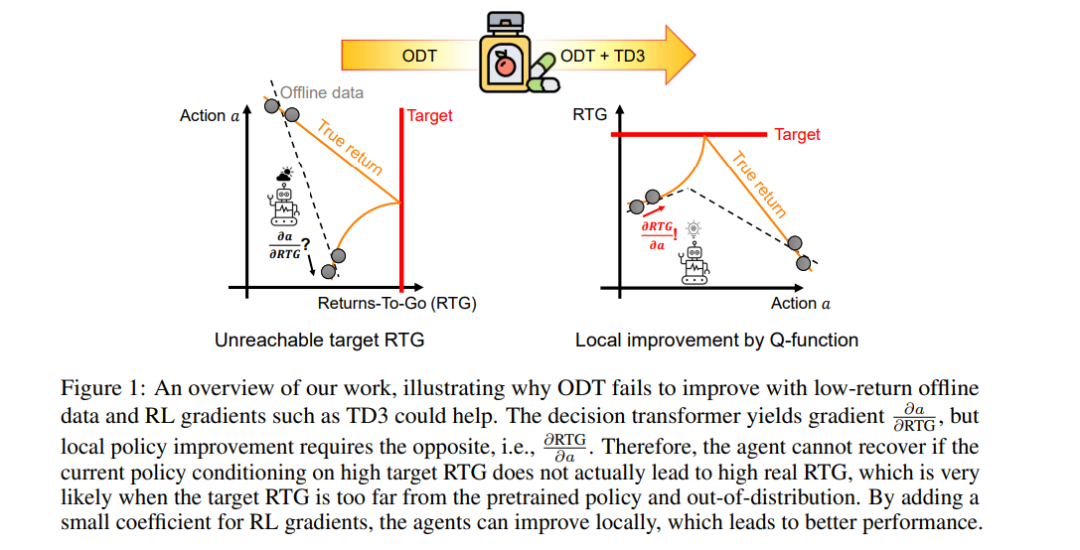
决策变换器(Decision Transformers)最近作为离线强化学习(RL)的一种新颖且引人注目的范式出现,通过自回归的方式完成轨迹。尽管已有改进以克服最初的缺点,决策变换器的在线微调却仍然鲜有深入探索。广泛采用的最先进的在线决策变换器(ODT)在使用低奖励离线数据进行预训练时仍然面临困难。本文理论上分析了决策变换器的在线微调,显示常用的远离期望回报的“回报至终”(Return-To-Go, RTG)会妨碍在线微调过程。然而,这一问题在标准强化学习算法中通过值函数和优势函数得到了很好的解决。根据我们的分析,在实验中,我们发现简单地将TD3梯度添加到ODT的微调过程中,能够有效提高ODT的在线微调性能,特别是在ODT使用低奖励离线数据预训练的情况下。这些发现为进一步改进决策变换器提供了新的方向。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









