







来源:专知
本文约1000字,建议阅读5分钟
本文旨在通过最小化监督且无需人工干预的方式,为细粒度类别寻找具有视觉区分度的提示。
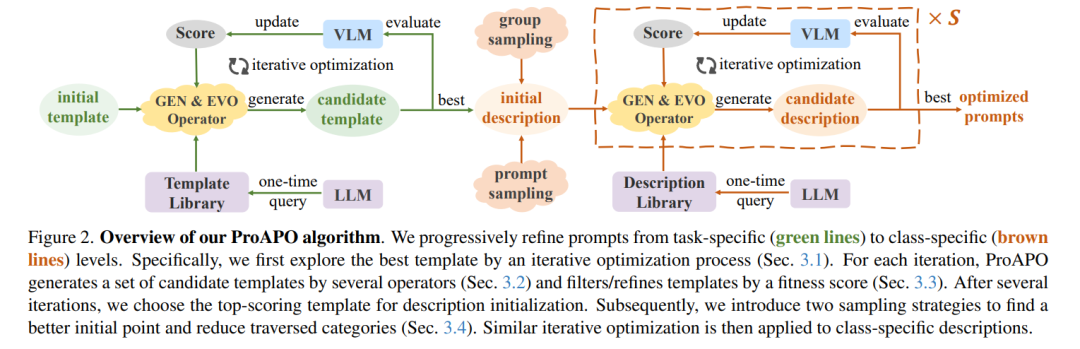
视觉-语言模型(VLMs)通过大规模成对的图像-文本数据进行训练,在图像分类领域取得了显著进展。其性能在很大程度上依赖于提示(prompt)的质量。尽管最近的研究表明,由大型语言模型(LLMs)生成的视觉描述能够增强VLMs的泛化能力,但由于LLMs的“幻觉”问题,针对特定类别的提示可能不准确或缺乏区分度。本文旨在通过最小化监督且无需人工干预的方式,为细粒度类别寻找具有视觉区分度的提示。我们提出了一种基于进化的算法,逐步优化语言提示,从任务特定的模板到类别特定的描述。与优化模板不同,类别特定的候选提示搜索空间呈爆炸式增长,这增加了提示生成成本、迭代次数以及过拟合问题。为此,我们首先引入了几种简单但有效的基于编辑和进化的操作,通过一次性查询LLMs生成多样化的候选提示。接着,提出了两种采样策略,以找到更好的初始搜索点并减少遍历的类别数量,从而节省迭代成本。此外,我们应用了一种带有熵约束的新型适应度评分来缓解过拟合问题。在具有挑战性的单样本图像分类任务中,我们的方法优于现有的基于文本提示的方法,并在13个数据集上提升了LLM生成描述方法的效果。同时,我们证明了我们的最优提示能够改进基于适配器的方法,并在不同骨干网络中有效迁移。我们的代码已公开在此处。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









