







来源:时序人
本文约4600字,建议阅读10+分钟
本文介绍一篇 ICLR 2025 中的工作,该工作旨在调查大型语言模型(LLMs)是否能够理解并检测时间序列数据中的异常,重点关注零样本和少样本场景。受时间序列预测研究中关于 LLMs 行为的猜想的启发,研究者针对 LLMs 在时间序列异常检测方面的能力提出了关键假设。研究表明:(1) LLMs 将时间序列作为图像理解的效果优于作为文本理解;(2) 当被提示进行显式的时间序列分析推理时,LLMs 并未表现出性能提升;(3) 与普遍观点相反,LLMs 对时间序列的理解并非源于其重复偏差或算术能力;(4) 在时间序列分析中,不同 LLMs 的行为和性能存在显著差异。
本研究首次全面分析了当代 LLMs 在时间序列异常检测方面的能力。结果表明,虽然 LLMs 能够理解简单的时间序列异常,但研究者并没有证据表明它们能够理解更微妙的现实世界中的异常。

【论文标题】
CAN LLMS UNDERSTAND TIME SERIES ANOMALIES?
【论文地址】
https://arxiv.org/abs/2410.05440
【论文源码】
https://github.com/rose-stl-lab/anomllm
论文概述
LLMs 在时间序列预测中的显著进展使其被应用于多个领域,但在时间序列分析中的有效性仍存在争议。虽然一些研究人员认为 LLMs 可以利用其预训练知识来理解时间序列模式,但其他研究人员认为简单的模型可以与 LLMs 相匹配甚至超越它们。这种争议引发了以下根本性问题:LLMs 是否真正理解时间序列?
要回答这个问题,必须超越模型的预测性能。预测通常依赖于均方误差(MSE)等指标,这些指标可能会掩盖模型对时间序列动态的深层理解。一个仅输出接近常数的模型可能仍然能够获得可接受的 MSE,但这并不能揭示其对模式的解释能力。将重点转向异常检测会改变游戏规则:它迫使 LLMs 识别出不规律的行为,从而测试它们是否真正理解底层模式,而不仅仅是如何外推平均值。
本文首次全面研究了 LLMs 在时间序列异常检测中的能力。研究者专注于最先进的 LLMs 和多模态 LLMs(M-LLMs),并在受控条件下针对不同类型的异常进行了测试。实验评估策略包括多模态输入(时间序列的文本和视觉表示)、各种提示技巧以及结构化输出格式,结果通过亲和力 F1 分数进行量化评估。研究者提供了实证证据来挑战关于 LLMs 时间序列理解的现有假设。该研究发现并揭示了 LLMs 在时间序列分析中的几个令人惊讶的方面,包括:
视觉优势:与文本表示相比,LLMs 在处理时间序列图像时表现更好。
有限推理能力:在分析时间序列时,LLMs 不会从明确的推理提示中受益。当被提示解释其推理过程时,其表现通常会下降。
替代处理机制:与普遍观点相反,LLMs 对时间序列的理解并非源于其重复偏差或算术能力,这挑战了关于这些模型如何处理数值数据的常见假设。
模型异质性:不同 LLM 架构在时间序列理解和异常检测能力上存在显著差异,这突出了模型选择的重要性。
时序异常检测概述
01 异常定义
时间序列异常检测的目标是识别出偏离正常模式的数据点。具体定义如下:
1. 时间序列的表示:
时间序列 X:={x1,x2,…,xT} 是在固定时间间隔内收集的数据点,其中 xt 是时间 t 的特征标量或向量,T 是总时间点数。
2. 异常的定义:
生成函数:假设时间序列是确定性的,数据点 xt 如果偏离由生成函数 G 预测的值超过阈值 δ,则被认为是异常:
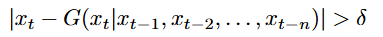
条件概率:假设时间序列是随机的,数据点 xt 如果其条件概率低于某个阈值 ϵ,则被认为是异常:
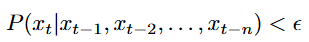
3. 异常检测算法的输出:
输出可以是二进制标签 Y:={y1,y2,…,yT},其中 yt=1 表示异常,yt=0 表示正常。
输出异常分数 {s1,s2,…,sT},其中分数越高表示越可能是异常。通过阈值 θ 可以将分数转换为二进制标签。
02 异常模式分类
时间序列预测和异常检测在任务定义上存在相似性,都依赖于对时间序列模式的外推。具体如下:
1. 时间序列预测:
确定性预测:学习生成函数 G。
概率性预测:学习条件概率函数 P。
2. 异常检测:
通过外推“正常”行为来识别偏离预期模式的点。这与预测任务类似,只是目标是识别异常而非预测未来值。
3. LLMs 的应用:
LLMs 在时间序列预测中的零样本外推能力被广泛研究,这些研究的假设可以扩展到异常检测任务中。例如,LLMs 的自回归生成能力与时间序列步骤的外推相似,这为将 LLMs 应用于异常检测提供了理论基础。
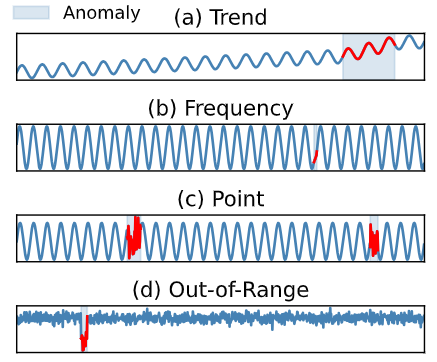
图1:不同异常类型的时间序列示例,异常区域用红色高亮显示
LLMs对时序的理解
01 提出假设
为了系统地研究 LLMs 在时间序列异常检测中的表现,研究者提出了以下七个假设,这些假设涵盖了 LLMs 的推理路径和偏差:
假设1:链式思考推理
LLMs 不会从逐步推理中受益。即在分析时间序列数据时,明确的推理提示(如“让我们一步一步思考”)不会提升 LLMs 的性能,甚至可能导致性能下降。
假设2:重复偏差
LLMs 的重复偏差与其识别周期性结构的能力相关。如果 LLMs 依赖于重复的模式来识别周期性异常,那么在引入微小噪声后,其性能应该会显著下降。
假设3:算术能力
LLMs 的算术能力(如加法和乘法)与其外推线性和指数趋势的能力相关。如果 LLMs 依赖算术能力来识别趋势异常,那么在削弱其算术能力后,其性能应该会下降。
假设4:视觉推理
时间序列异常作为图像比作为文本更容易被 LLMs 检测。这可能是因为人类分析师通常通过视觉方式检测时间序列异常,而多模态 LLMs(M-LLMs)在视觉任务上表现出色。
假设5:视觉感知偏差
LLMs 的异常检测能力受到人类感知偏差的限制。例如,人类在检测加速变化时比检测趋势反转更困难,如果 LLMs 表现出类似的感知偏差,那么它们在检测加速异常时的表现应该比检测趋势反转更差。
假设6:长文本上下文偏差
LLMs 在处理较短时间序列时表现更好,即使这意味着信息丢失。这可能是因为 LLMs 在处理长序列时存在困难,尤其是在需要处理大量时间步长时。
假设7:模型家族一致性
LLMs 对时间序列的理解在不同模型家族之间是一致的。如果这一假设成立,那么在某些模型上观察到的现象应该在其他模型上也能复现。
02 提示策略
为了验证上述假设,研究者设计了多种提示策略,以测试LLMs在不同条件下的表现:
1. 零样本和少样本学习:
零样本学习:LLMs 在没有任何标注样本的情况下进行异常检测。
少样本学习:LLMs 使用少量标注样本进行学习,以提高检测性能。
2. 链式思考:
通过逐步推理的方式引导 LLMs 进行异常检测。例如,提示 LLMs 描述时间序列的一般模式,识别偏离模式的点,并判断这些偏离是否构成异常。
3. 输入表示:
文本表示:将时间序列数据以文本形式输入 LLMs,包括原始数值、CSV 格式、统计信息前缀(如均值、中位数、趋势)和按位表示(将浮点数拆分为单独的数字)。
视觉表示:将时间序列数据以图像形式输入多模态 LLMs,利用其视觉理解能力。
4. 输出格式:
要求 LLMs 以 JSON 格式输出异常范围,例如 [{"start": 10, "end": 25}, {"start": 310, "end": 320}]。这种格式便于与真实标签进行比较,并进行量化评估。
LLMs对时序的理解
01 实验设置
1. 模型选择
实验使用了四种最先进的多模态大语言模型(M-LLMs),包括:
Qwen-VL-Chat:阿里巴巴云开发的高性能量子语言模型,支持文本-图像对话任务。
InternVL2-Llama3-76B:开源的多模态 LLM,结合了高质量的双语数据集和强大的视觉编码器。
GPT-4o-mini:OpenAI 开发的成本效益较高的小型版本 GPT-4o,支持文本和视觉输入。
Gemini-1.5-Flash:谷歌开发的快速多模态模型,优化了高容量和高频任务。
这些模型涵盖了不同的架构(如Qwen、LLaMA、Gemini、GPT),以验证模型架构对时间序列理解的影响。
2. 数据集构建
为了测试不同类型的异常,研究者合成了以下四种主要数据集:
点异常(Point Anomalies):在周期性正弦波中插入噪声和不可预测的偏差。
范围异常(Range Anomalies):在高斯噪声中插入突然的尖峰。
趋势异常(Trend Anomalies):在缓慢增加的趋势中插入加速或反转的趋势。
频率异常(Frequency Anomalies):在周期性正弦波中插入频率变化。
此外,还添加了噪声版本的数据集以测试假设2(重复偏差)和假设5(视觉感知偏差)。所有数据集均包含400个时间序列,每个序列有1000个样本点。
3. 评估指标
由于 LLMs 输出的是离散的异常区间,而不是连续的异常分数,因此研究者使用了以下评估指标:
精确率(Precision)、召回率(Recall) 和 F1分数:这些指标将时间序列视为离散点的集合,但忽略了时间顺序。
亲和力精确率(Affinity Precision) 和 亲和力召回率(Affinity Recall):这些指标考虑了时间序列的时间顺序,更适合评估异常检测任务。最终的评估指标是亲和力F1分数(Affinity F1),它是亲和力精确率和亲和力召回率的调和平均值。

图2:超出范围异常的异常检测结果示例。
4. 基线方法
为了验证 LLMs 的有效性,研究者使用了两种简单的基线方法进行对比:
隔离森林(Isolation Forest):一种基于树的异常检测算法。
阈值化方法(Thresholding):将时间序列的顶部2%和底部2%的值视为异常。
02 实验结果
实验结果验证了前文提出的假设,并揭示了 LLMs 在时间序列异常检测中的表现和局限性。
假设1:链式思考推理
实验发现,当明确使用链式思考(CoT)提示时,LLMs 的异常检测性能在所有模型和异常类型中均显著下降。这表明LLMs在时间序列分析中可能并不依赖于逐步推理,而是采用了其他机制。
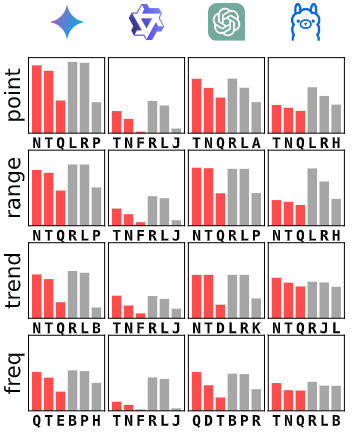
图3:反射性(诱导推理的提示)/反思性(直接要求答案的提示),每种模式下得分最高的三个Affi-F1提示变体
假设2:重复偏差
在引入噪声后,文本和视觉输入的性能下降幅度相似,且文本性能的下降并不显著。这表明 LLMs 识别周期性异常的能力并非源于其重复偏差,而是可能依赖于其他机制。
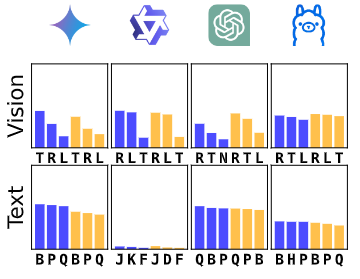
图4:清洁数据(原始时间序列)/噪声数据(注入最小噪声的时间序列),每个噪声水平下得分最高的三个Affi-F1变体
假设3:算术能力
通过削弱 LLMs 的算术能力(例如,通过上下文学习使其在加法任务中表现较差),实验发现其异常检测性能并未显著下降。这表明 LLMs 的异常检测能力与其算术能力无关。
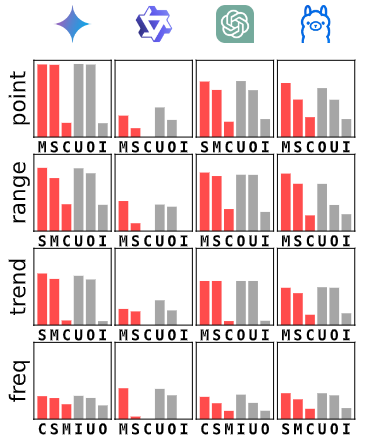
图5:计算(包含正确算术示例的提示)/计算障碍(包含错误示例的提示),每种模式下得分最高的三个Affi-F1变体
假设4:视觉推理
实验结果表明,多模态 LLMs 在处理时间序列图像时的表现显著优于处理文本数据的 LLMs。这与人类分析师通过视觉方式检测异常的偏好一致。
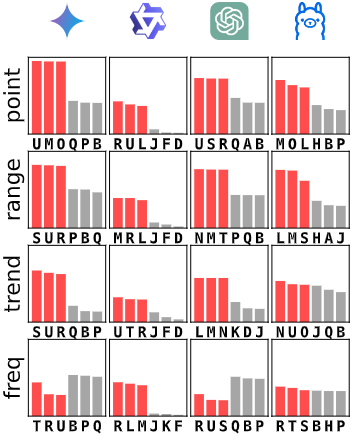
图6:视觉(包含可视化时间序列的提示)/文本(原始数值提示),每种模态下得分最高的三个Affi-F1变体
假设5:视觉感知偏差
通过设计难以被人类视觉检测到的“平坦趋势”异常,实验发现 LLMs 的性能与常规趋势异常数据集相似。这表明 LLMs 的异常检测能力并不受人类视觉感知偏差的限制。
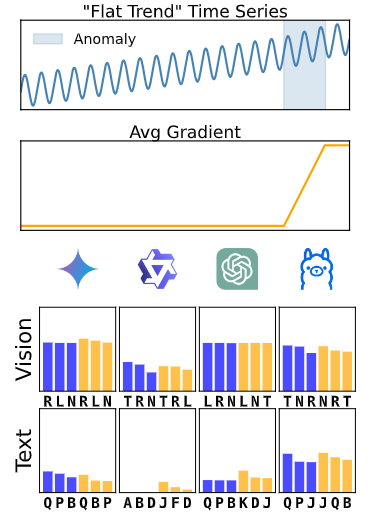
图8:平稳趋势(上面已给出示例)/趋势(趋势在异常期间可能会反转),每个数据集下得分最高的三个Affi-F1变体
假设6:长文本上下文偏差
实验通过将时间序列从1000个时间步长缩短到300个时间步长,发现 LLMs 的性能显著提升。这表明 LLMs 在处理较短时间序列时表现更好,可能是因为长序列增加了模型的处理负担。
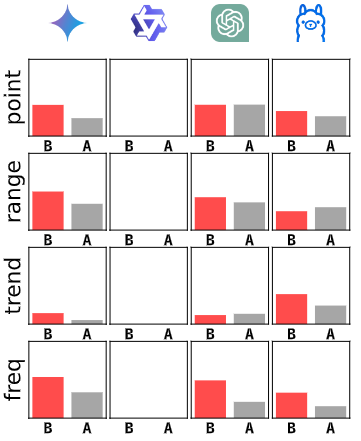
图7:子采样(时间序列被子采样以缩短)/原始数据,0次(0-shot)原始文本与30%文本对比
假设7:模型架构偏差
不同 LLM 架构在时间序列异常检测中的表现存在显著差异,即假设7被否定了。例如,GPT-4o-mini 在视觉输入上的表现优于文本输入,而 Qwen 在视觉输入上的表现优于文本输入。这表明 LLMs 在时间序列任务中的性能可能极大地依赖于训练数据、参数数量和微调策略等因素。
03 其他观察结果
文本表示方法
实验发现,没有一种文本表示方法在所有情况下都优于其他方法。例如,Qwen 仅在使用统计信息前缀(PaP)时表现非零,而其他模型则在不同表示方法下表现各异。
LLMs 的性能
在某些情况下,LLMs 的性能优于传统的隔离森林和阈值化方法,尤其是在点异常、范围异常和趋势异常数据集上。这表明 LLMs 在零样本时间序列异常检测中是一个合理的选择。
Token-per-Digit 表示
实验发现,Token-per-Digit(TPD)表示方法仅在某些情况下对 GPT-4o-mini 有效,而对其他模型无效。这表明 TPD 可能仅在特定条件下对某些模型有帮助。
编辑:黄继彦
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









