







在android应用中加入语音功能,将使应用更加的实用、方便。google的语音使用还是比较简单的,下面给大家介绍一下使用方法:
1、下载Google Voice的APK安装包,在手机中进行安装。
2、Android调用Google Voice代码
private static final int RESULT_FROM_VOICE = 1;(1) 启动谷歌语音
/**
* 启动谷歌语音
*/
private void startGoogleVoice() {
try{
Intent intent = new Intent(RecognizerIntent.ACTION_RECOGNIZE_SPEECH);
intent.putExtra(RecognizerIntent.EXTRA_LANGUAGE_MODEL,
RecognizerIntent.LANGUAGE_MODEL_FREE_FORM);
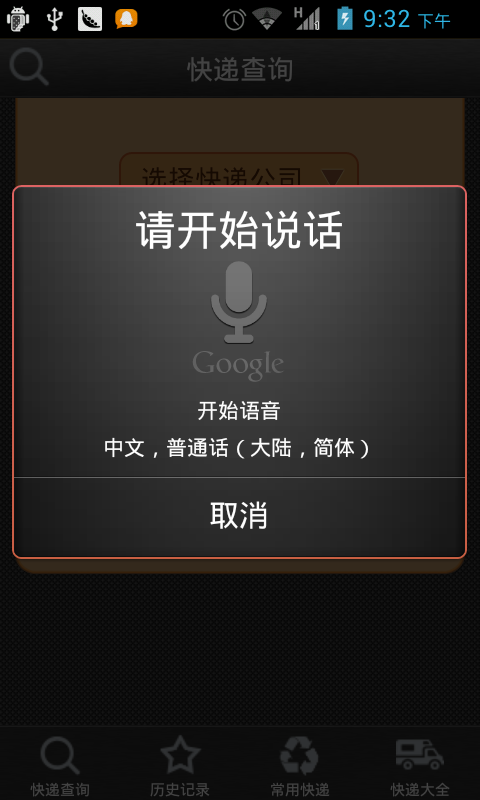
intent.putExtra(RecognizerIntent.EXTRA_PROMPT, "开始语音");
startActivityForResult(intent, RESULT_FROM_VOICE);
}catch(ActivityNotFoundException e){
// 下载谷歌语音APK包,并安装。
FileDownload fd = new FileDownload(ExpressActivity.this,
ConstData.googleVoiceUrl, "下载谷歌语音引擎");
fd.showDownloadNoticeDialog();
}
}(2)接收返回值
重写Activity的onActivityResult方法
//返回值
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
if(data == null)
return;
//谷歌语音
if(requestCode == RESULT_FROM_VOICE){
matches = data.getStringArrayListExtra(
RecognizerIntent.EXTRA_RESULTS);
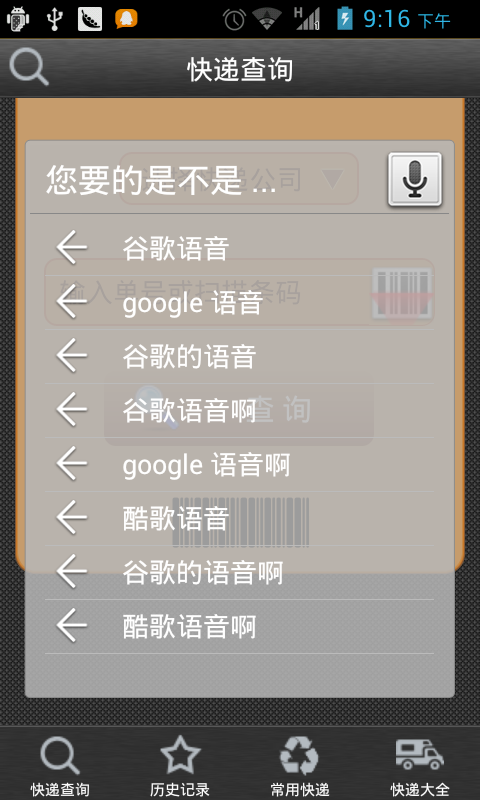
if(matches != null && matches.size() > 0){
Dialog dialog = new GoogleVoiceDialog(ExpressActivity.this,
R.style.GoogleVoiceDialog);
dialog.show();
}
}
super.onActivityResult(requestCode, resultCode, data);
}3、效果图















 2766
2766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









