







六、协同过滤
Slope One是一个可以用于推荐系统的算法,在只有很少的数据时候也能得到一个相对准确的推荐,而且算法很简单, 易于实现, 执行效率高,由此衍生的还有加权 Slope One 算法、双极 SlopeOne 算法(BI-Polar SlopeOne)将用户对于其的厌恶程度也引入打分机制中,下面简单解释一下 Slope One 算法的原理:
| 用户 | 东西一 | 东西二 |
|---|---|---|
| 张三 | 5分 | 3分 |
| 李四 | 4分 | 3分 |
| 王五 | 4分 | X分 |
我们已知张三和李四对两个东西的评分,然后知道王五关于东西一的评分,问王五有可能对东西二是什么态度,基于这个评分我们可以选择推荐给王五什么东西来吸引王五进行购买
给东西一和东西二打分的“平均差距”应该是相似的,比如这个样本中只有两个人,张三认为东西二要比东西一低2分,李四认为东西二应该比东西一低1分,根据已购买的这两个用户,东西二平均应该比东西一低1.5分,那么我有理由认为,王五有很大可能性也会这样认为,给东西二打分为3.5分(4分-1.5分)
所以Slope One的计算方法是:
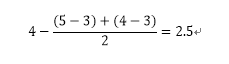
# encoding: utf-8
class SlopeOne(object):
# self.diffs 矩阵存储评分矩阵,
# self.freqs 存储一对 items 被相同用户评分的数量。
def __init__(self):
self.diffs = {}
self.freqs = {}
# 根据提供的数据,构建self.diffs / self.freqs字典
def update(self, data):
# 遍历每个用户的每个评分数据
for user, prefs in data.items():
# 确保子字典存在
for item, rating in prefs.items():
self.freqs.setdefault(item, {})
self.diffs.setdefault(item, {})
# setdefault 作用:
# 如果对于给定的键值/setdefault的第一个参数,
# 字典中为对应value为空,
# 则将setdefault的第二个参数赋值给它。
# 下面再次循环遍历user对应的prefs中的每一组评分
for item2, rating2 in prefs.items():
self.freqs[item].setdefault(item2, 0)
self.diffs[item].setdefault(item2, 0.0)
# 使用整数0初始化次数,浮点型零初始化评分。
# 利用两个item是否同时被一个用户评分,
# 对self.freqs进行更新
self.freqs[item][item2] += 1
# 利用两个item的评分之差,对self.diffs矩阵进行更新
self.diffs[item][item2] += rating - rating2
# 将两个item在diffs 矩阵与 freqs矩阵对应位置相除,
# 结果保存到freqs中,即为两个item的平均差距
for item, ratings in self.diffs.items():
for item2, rating in ratings.items():
ratings[item2] /= self.freqs[item][item2]
# 对新的用户偏好,根据 self.diffs / self.freqs 对新用户进行评分预测
def predict(self, userprefs):
# 定义两个空字典,preds存储预测数据,freqs存储计数
preds, freqs = {}, {}
# 迭代每一个物品(被用户评分过的)
# 使用try/except跳过没有被评分的物品对
for item, rating in userprefs.items():
for diffitem, diffratings in self.diffs.items():
try:
freq = self.freqs[diffitem][item]
except KeyError:
continue
# 设置preds初始值为0.0, freqs初始值为0
preds.setdefault(diffitem, 0.0)
freqs.setdefault(diffitem, 0)
# 累加
preds[diffitem] += freq * (diffratings[item] + rating)
freqs[diffitem] += freq
# 在返回结果之前,进行过滤
# 返回一个 带权重预测值 的新字典
# 结果中除去了 用户已经评分过的内容 和 物品计数为零的内容
return dict([(item, value / freqs[item]) for item, value in preds.items() if item not in userprefs and freqs[item] > 0])
s = SlopeOne()
s.update(dict(alice = dict(squid=1.0, cuttlefish=4.0), bob = dict(squid=1.0, cuttlefish=1.0, octupus=3.0)))
prediction = s.predict(dict(squid=3.0, cuttlefish=4.0))
for item, rating in prediction.items():
print(item+":\t"+str(rating))
注意的是文章中的iteritems以迭代器对象,返回键值对儿(Python3中不再支持),改用iterms
参考文献:
1、协同过滤算法的Python实现
2、上面文章英文原文的翻译
七、Bitmap算法
我们可能在算法书中都看过,对于海量数据的处理是有一些独特的算法的,通常来说如下六种:
| 序号 | 算法 |
|---|---|
| 1 | 分而治之/hash映射 + hash统计 + 堆/快速/归并排序 |
| 2 | 双层桶划分 |
| 3 | Bloom filter/Bitmap |
| 4 | Trie树/数据库/倒排索引 |
| 5 | 外排序 |
| 6 | 分布式处理之Hadoop/Mapreduce |
这里我介绍的是Bitmap,BitMap就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素,该方法在快速查找、去重、排序、压缩数据上都有应用
假设我们要对0-7内的5个元素(4,7,2,5,3)排序,因为要表示8个数,我们就只需要8个bit(1Bytes)。
| 元素 | 无 | 无 | 2 | 3 | 4 | 5 | 无 | 7 |
|---|---|---|---|---|---|---|---|---|
| 占位 | × | × | √ | √ | √ | √ | × | √ |
| 地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
这样就排序完成了,该方法难在数对二进制位的映射,因为类型到底多长是和平台和环境有关的,我们假定int是32bit,之后假设我们现在有320个数据需要排序,则int a[1+10],a[0]可以表示从0-31的共32个数字,a[1]可以表示从32-61的共32个数字,我们可以想象这是一个二位数组,但是其实并不是
我们可以很容易得出,对于一个十进制数n,对应在数组a[n/32][n%32]中
# encoding: utf-8
from collections import namedtuple
from copy import copy
Colour = namedtuple('Colour','r,g,b')
Colour.copy = lambda self: copy(self)
black = Colour(0,0,0)
white = Colour(255,255,255) # Colour ranges are not enforced.
class Bitmap():
def __init__(self, width = 40, height = 40, background=white):
assert width > 0 and height > 0 and type(background) == Colour
self.width = width
self.height = height
self.background = background
self.map = [[background.copy() for w in range(width)] for h in range(height)]
def fillrect(self, x, y, width, height, colour=black):
assert x >= 0 and y >= 0 and width > 0 and height > 0 and type(colour) == Colour
for h in range(height):
for w in range(width):
self.map[y+h][x+w] = colour.copy()
def chardisplay(self):
txt = [''.join(' ' if bit==self.background else '@'
for bit in row)
for row in self.map]
# Boxing
txt = ['|'+row+'|' for row in txt]
txt.insert(0, '+' + '-' * self.width + '+')
txt.append('+' + '-' * self.width + '+')
print('\n'.join(reversed(txt)))
def set(self, x, y, colour=black):
assert type(colour) == Colour
self.map[y][x]=colour
def get(self, x, y):
return self.map[y][x]
bitmap = Bitmap(20,10)
bitmap.fillrect(4, 5, 6, 3)
assert bitmap.get(5, 5) == black
assert bitmap.get(0, 1) == white
bitmap.set(0, 1, black)
assert bitmap.get(0, 1) == black
bitmap.chardisplay()八、优先队列
优先队列和普通队列大体上相似,但有一个重大区别:每个被添加进队列的元素都有一个优先级,在从队列中移除元素时,先移除优先级最高的元素。在观念上,元素是存储在按照优先级排序的队列中,而不是插入顺序。
在Python的标准库中有优先队列这个数据结构,队列这个数据结构中是同步的多生产者-多消费者,并且支持多线程
# encoding: utf-8
'''
Priority Task
3 Clear drains
4 Feed cat
5 Make tea
1 Solve RC tasks
2 Tax return
'''
import queue
pq = queue.PriorityQueue()
for item in ((3, "Clear drains"), (4, "Feed cat"), (5, "Make tea"), (1, "Solve RC tasks"), (2, "Tax return")):
pq.put(item)
while not pq.empty():
print(pq.get_nowait())想进一步了解优先队列,可以使用
import queue
help(queue.PriorityQueue)
Help on class PriorityQueue in module queue:查看帮助手册来获得更多get、join、put等函数的使用方法















 3009
3009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









