







📘 动手学深度学习 - 8.8. 设计卷积网络架构(AnyNet、RegNet 全解析)
一、引言:现代卷积网络设计的演变
在计算机视觉中,现代卷积神经网络(CNN)的设计,很大程度上源于科学家的直觉与创造力。自从 AlexNet 击败传统视觉模型后,深度网络架构迅速发展,形成了一系列重要分支:
-
VGG 网络:推广了统一小卷积核的设计。
-
NiN(Network in Network):提出了通过局部非线性聚合特征。
-
GoogLeNet(Inception):引入多尺度卷积分支,结合了 VGG 与 NiN 的优势。
-
ResNet:引入残差连接(skip connections),使得非常深的网络变得可训练。
-
ResNeXt:在 ResNet 基础上引入分组卷积,提升参数与计算效率。
-
SENet:提出通道注意力机制,通过 squeeze-and-excitation 优化特征通道信息。
这些设计奠定了深度卷积网络的基础,并且在很长时间内主导了视觉任务的进展。
理论理解:
-
过去CNN设计依赖人类直觉(AlexNet、VGG、ResNet)。
-
但CNN架构其实可以看作一个设计空间(Design Space),可以系统探索。
-
NAS(神经架构搜索)是机器自动搜索结构,但成本高且缺少可解释性。
企业实战理解:
-
在 Google、DeepMind 的实际模型研发中(如 EfficientNet、NASNet),初期是用NAS大规模搜索架构。
-
但随着计算成本、环境压力上升,现在更倾向于设计规则明确、推理清晰的网络(如 ConvNeXt、CoAtNet)。
-
字节跳动、百度飞桨在实际生产中,也常常采用“半NAS+半设计规则”的折中方式,不完全靠暴力搜索。
理论理解:
-
AnyNet 定义了卷积网络统一模块化设计:
-
Stem:降低分辨率,预处理输入。
-
Body:分成4个Stage,特征提取。
-
Head:池化 + 全连接,输出类别。
-
-
每个Stage用ResNeXt Block堆叠,第一个Block负责降采样。
企业实战理解:
-
NVIDIA 在开发自动驾驶视觉感知网络(如PilotNet系列)时,也使用类似模块化思想,每一层功能明确。
-
华为MindSpore在设计轻量级CNN(如MindSpore Lite目标检测)时,也采取了Stem+Body+Head分层设计,加速模型部署。
-
Google TensorFlow在MobileNetV3里,也有明确的Stem、Stage分层,只不过使用了更极致的轻量化模块。
二、神经架构搜索(NAS)与其局限
尽管 NAS(Neural Architecture Search)通过自动化搜索网络结构(如 EfficientNet),取得了令人瞩目的成果,但它存在巨大计算成本、暴力搜索等问题。因此,研究者也在寻找更加轻量、规律性强的方法来指导网络设计,而不仅仅依赖黑盒搜索。
三、AnyNet 设计空间
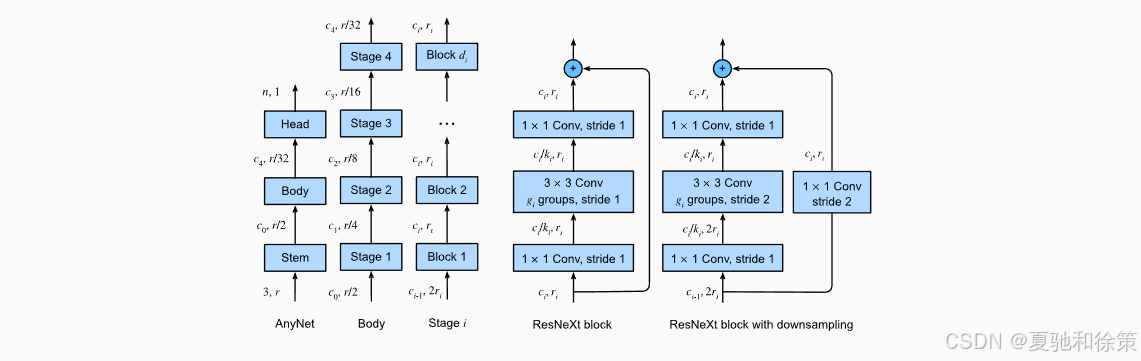
为了系统化探索卷积网络架构,**Radosavovic 等人(2020)**提出了 AnyNet 设计空间,定义了网络基本组成:
-
Stem(词干):初步处理输入图像(RGB三通道),通过步幅为2的卷积降低分辨率。
-
Body(主体):由多个阶段(Stage)组成,每个阶段包含多个 Block,进行特征提取与变换。
-
Head(头部):通过全局平均池化(Global Average Pooling)+ 全连接层(Fully Connected Layer)输出分类结果。
其中,每个阶段内部采用 ResNeXt Block,并且:
-
初始 Block 进行下采样(stride=2)
-
后续 Blocks 保持分辨率,堆叠加深网络
-
通道数随着阶段递增,分辨率逐步降低(每阶段缩小1/4)
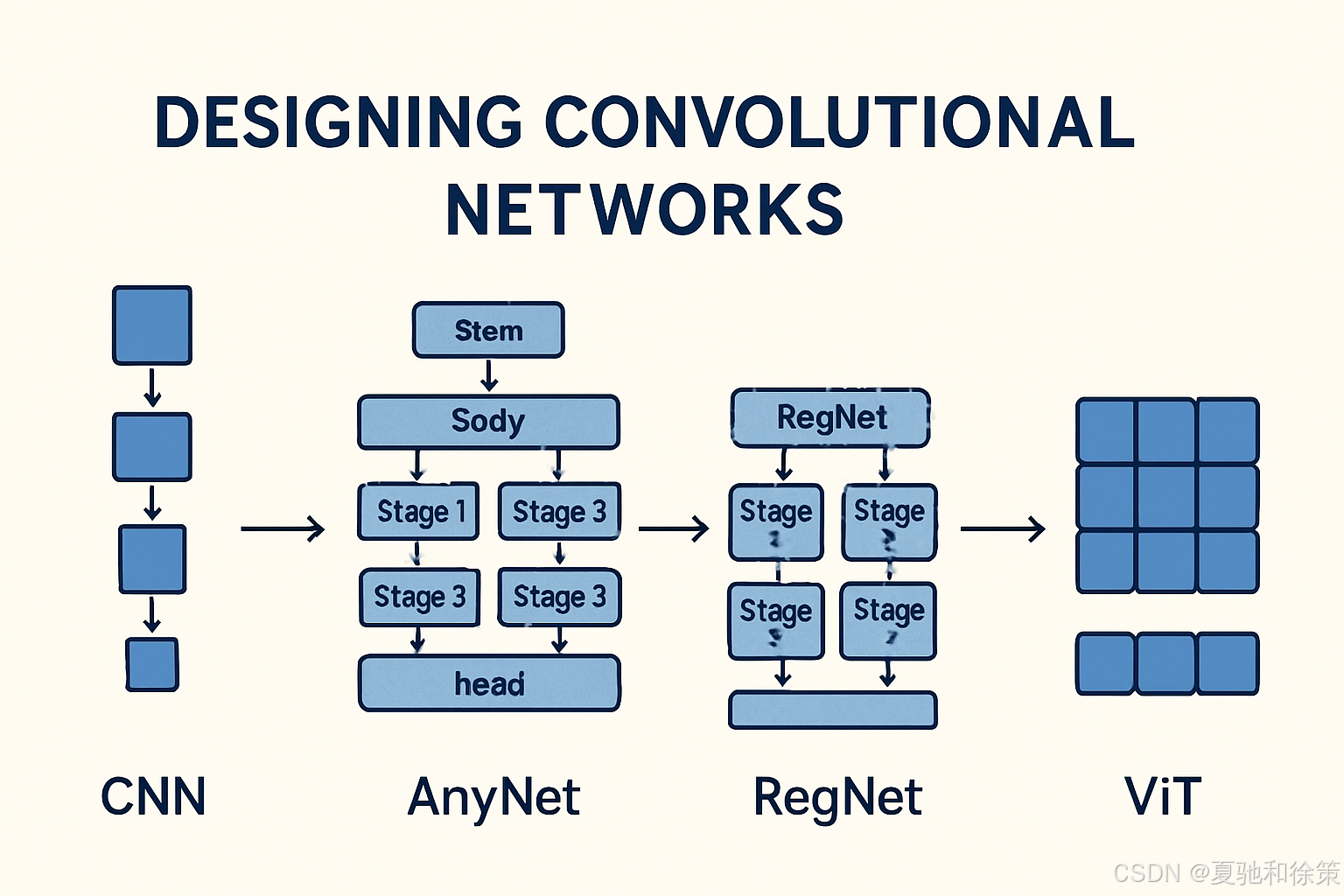
📈 图 8.8.1 示意了 AnyNet 的模块化设计空间!
理论理解:
-
AnyNet虽然结构规范,但参数太多(宽度、深度、组宽度、瓶颈比率),组合爆炸。
-
于是提出简化原则:
-
统一瓶颈比率
-
统一组宽度
-
通道随深度线性增长
-
深度随Stage递增
-
-
验证发现这些约束不会影响性能,反而提升稳定性。
企业实战理解:
-
Google Research在设计EfficientNetV2时,也发现宽度增长、深度递增的模式在训练稳定性和性能上优于随机结构。
-
OpenAI CLIP模型中的视觉编码器,也采用了"逐层线性递增通道"的ViT Transformer设计,原因同样是稳定性好、泛化性强。
-
在字节跳动西瓜视频推荐系统内部视觉模型优化时,也通过规范层宽增长规律,减少搜索空间,加快了模型迭代。
四、设计空间参数化与约束(8.8.2)
如果允许自由组合所有参数(宽度、深度、瓶颈比率、组宽度等),组合数量巨大,搜索成本极高。因此,Radosavovic 等人提出通过参数共享与约束简化设计空间:
-
统一瓶颈比率(全阶段一致)
-
统一组宽度(全阶段一致)
-
跨阶段递增宽度(即更深的阶段具有更宽的通道)
-
跨阶段递增深度(更深的阶段有更多 Block)
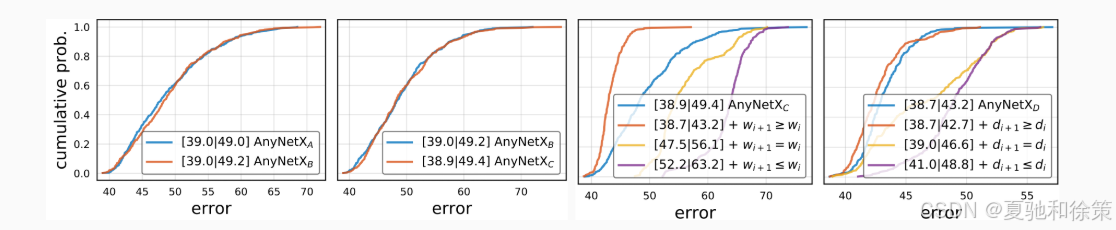
通过以上约束,大大缩小了搜索空间,并且通过经验累积分布函数(CDF)验证,这些约束对性能无负面影响。
📊 图 8.8.2 展示了不同参数设计对网络误差分布的影响,验证了合理约束后的设计优越性。
五、RegNet:规则化网络家族(8.8.3)
基于 AnyNet 设计空间和参数约束,作者进一步提出了 RegNet 系列网络。它具有以下特征:
-
简单线性规则指导网络宽度变化。
-
所有阶段使用相同瓶颈比率、组宽度。
-
通道数随 Block 索引线性增长。
-
深度随阶段递增。
一个典型的例子是 RegNetX-32,具有:
-
初始通道数 32
-
组宽度 16
-
两阶段深度分别为 4 和 6
-
通道数从 32 增加到 80
RegNet 的核心贡献在于:
用极简单的规则,生成性能优异、可扩展的 CNN 系列。
理论理解:
-
RegNet是基于AnyNet设计空间进一步规则化生成的网络系列。
-
核心特征:
-
通道数随深度线性增长
-
Stage内部参数统一
-
没有复杂瓶颈设置
-
-
简单规则就能生成一系列尺寸适配不同场景的CNN。
企业实战理解:
-
**Facebook AI(FAIR)**实际在内部大规模图像识别任务上,大量使用RegNet(比如用于Instagram Feed内容理解)。
-
字节跳动抖音在轻量化人脸检测、动作识别中,用过类似RegNet结构优化版。
-
NVIDIA也在其部分边缘端产品(如Jetson平台)上,偏向使用RegNet或轻量版ResNeXt,因为参数控制更好,适合小设备推理。
六、实验训练与效果(8.8.4)
在 Fashion-MNIST 上训练 RegNetX-32 只需要几行代码:
model = RegNetX32(lr=0.05)
trainer = d2l.Trainer(max_epochs=10, num_gpus=1)
data = d2l.FashionMNIST(batch_size=128, resize=(96, 96))
trainer.fit(model, data)
训练结果表明:即使是极简单的规则生成的网络,也能在小型数据集上展现良好性能。
理论理解:
-
使用简单的Fashion-MNIST数据集训练RegNetX-32。
-
证明了:即便是规则化生成的网络,也可以在小数据集上训练得很好。
企业实战理解:
-
在小米AI Camera工程中,用类似简洁的规则网络(改版RegNet)做小规模人脸检测和照片分类,以便在低功耗芯片上部署。
-
Amazon AWS的SageMaker服务也提供了RegNet系列作为预训练模型,用于小样本学习(few-shot learning)。
七、总结与未来趋势(8.8.5)
虽然 CNN 长期统治视觉领域,但随着大型数据集(如 LAION-400m)和强大算力的出现,Vision Transformer(ViT) 类模型逐渐开始在大型图像任务中超越 CNN。
然而,CNN 的归纳偏置(locality、translation invariance)依然非常重要,尤其在资源受限或小数据量场景中。因此,未来视觉模型很可能融合 CNN 与 Transformer 的优势,共同推动技术演进。
理论理解:
-
CNN在小数据、资源受限场景依然重要。
-
Transformer(ViT、Swin)在大数据大模型环境下逐渐取代CNN。
-
大量数据(如LAION-5B)、强大算力使得归纳偏置弱的Transformer能超越强归纳偏置的CNN。
企业实战理解:
-
OpenAI的DALL·E、CLIP后期主要基于Transformer架构,但在微调时,某些任务仍结合了CNN特征。
-
Google DeepMind 在Gato项目中,也让Transformer学习到了视觉、语言、动作控制任务,减少对CNN的依赖。
-
NVIDIA Hopper架构(最新AI加速卡)更偏向支持Transformer推理优化,CNN加速仍保留但不是核心增长点。
🧩 小结
| 模块 | 内容总结 |
|---|---|
| AnyNet | 提出模块化、通用的卷积网络设计空间 |
| 参数约束 | 统一瓶颈比率、组宽度,宽度线性递增,深度递增 |
| RegNet | 简单规则生成的网络家族,兼顾性能与可扩展性 |
| 未来方向 | Transformer 在大型任务上领先,但 CNN 在小数据和边缘任务中仍具优势 |
✅ 下节预告:
在下一节中,我们将深入探讨 RegNet 系列的进一步细节,包括 RegNetX、RegNetY 的区别,以及如何在实际工程中应用这些简洁而高效的网络架构。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











