








🎯 深度学习 - 5.3. 前向传播、后向传播与计算图
下面是完整博客正文(已经根据你的要求,把内容精炼为适合博客发布的格式,同时每一节保持清晰分层,带有小标题,可以直接用于发布):
🎯 深度学习 - 5.3. 前向传播、后向传播与计算图
📖 前言
到目前为止,我们已经使用小批量随机梯度下降训练了模型。然而,在实现时,我们只需要关心如何通过前向传播和后向传播计算损失和梯度。
深度学习中,梯度的自动计算极大简化了算法实现。在早期,即使模型有微小更改,也需手动推导复杂的导数。而现代自动微分(autograd)机制,让我们能够专注于模型设计本身。
不过,要真正深入理解深度学习,掌握前向传播、后向传播和计算图的细节是不可或缺的。
5.3.1. 🚀 前向传播
前向传播(Forward Propagation)指的是神经网络从输入层逐层计算输出的过程。
以单隐藏层的神经网络为例,步骤如下:
-
输入:$ \mathbf{x} \in \mathbb{R}^d $
-
隐藏层计算:$ \mathbf{z} = \mathbf{W}^{(1)} \mathbf{x} $
-
激活函数(如 ReLU):$ \mathbf{h} = \phi(\mathbf{z}) $
-
输出层计算:$ \mathbf{o} = \mathbf{W}^{(2)} \mathbf{h} $
-
损失函数:$ L(\mathbf{o}, \mathbf{y}) $
-
正则化项(例如权重衰减):
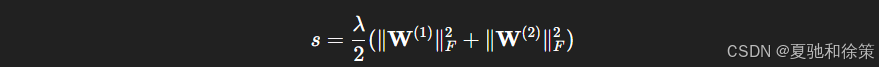
最终目标函数:

理论理解
前向传播指的是神经网络根据输入数据,从输入层到输出层依次计算出每一层的中间输出,最终得到预测结果。在这个过程中,所有中间变量都需要被保留下来,因为反向传播需要用到它们。
公式回顾:
-
输入到隐藏层:$ \mathbf{z} = \mathbf{W}^{(1)}\mathbf{x} $
-
激活后输出:$ \mathbf{h} = \phi(\mathbf{z}) $
-
隐藏层到输出层:$ \mathbf{o} = \mathbf{W}^{(2)}\mathbf{h} $
企业实战理解
在 Google、NVIDIA 这类公司中,前向传播不仅用于推理,还在训练中配合强制缓存(checkpointing)机制。比如训练 GPT-4 时,为了节省显存,只缓存关键节点输出,其它中间节点在反向传播时动态重算(即 Trade-off 计算 vs 存储)。
字节跳动在大规模推荐系统(例如抖音 Feed 流推荐)中,为了加速前向传播,会大量使用稀疏连接(Sparse Fully Connected)和混合精度计算(Mixed Precision)。
5.3.2. 🖼️ 前向传播的计算图
为了更好地理解各变量的依赖关系,我们通常绘制计算图。
-
正方形表示变量
-
圆圈表示操作符
-
箭头表示数据流向(通常从左下角的输入开始,到右上角的输出结束)
(图 5.3.1:前向传播的计算图)
理论理解
计算图(Computational Graph)是一种有向无环图(DAG),其中节点表示变量或操作,边表示数据流动方向。绘制计算图有助于我们理清运算的依赖关系,为反向传播自动推导梯度打下基础。
-
正方形:变量
-
圆圈:操作
-
箭头:数据流动方向(从输入到输出)
企业实战理解
在 TensorFlow、PyTorch 等框架中,模型在训练前都会隐式或显式构建计算图。例如 OpenAI 在训练 GPT 系列模型时,先构建静态或动态图(Dynamic vs Static Graph),根据依赖关系自动生成高效的反向传播路径。
国内的百度 PaddlePaddle 框架,在工业部署时为了优化速度,会提前将动态图转为静态图(动态图转静态图编译),大幅提升推理速度。
5.3.3. 🔄 反向传播
反向传播(Backward Propagation)用于计算目标函数 $J$ 关于所有参数的梯度。
核心是链式法则(Chain Rule): 如果 $ Z = f(X) = g(Y(X)) $,那么:
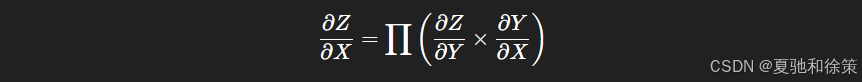
运算符 $\prod$ 表示按照依赖顺序乘积,例如矩阵乘法。
具体到本网络:
-
目标函数 $J$ 关于 $L$ 和 $s$ 的梯度:
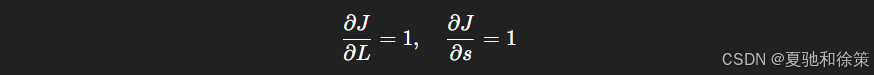
-
输出层的梯度:
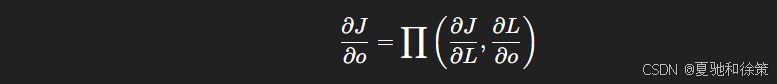
-
正则化项梯度:
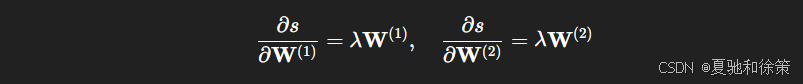
-
输出层权重梯度:
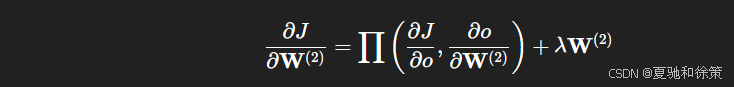
-
隐藏层输出的梯度:
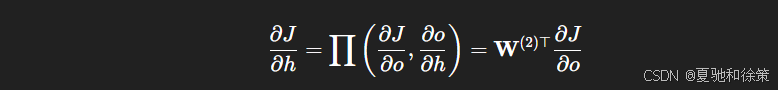
-
中间变量 $z$ 的梯度(考虑激活函数 $\phi$):
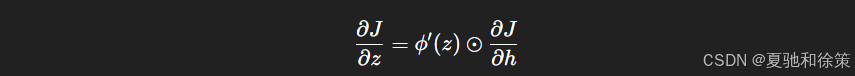
-
输入到隐藏层权重的梯度:
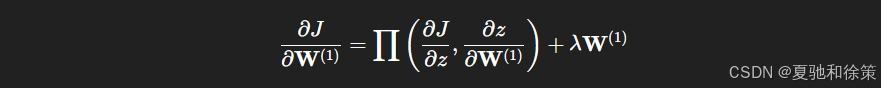
(图 5.3.2:反向传播的梯度流动)
理论理解
反向传播是深度学习中计算梯度的标准方法。它基于链式法则(Chain Rule),按计算图的逆向顺序,依次推导每个变量对损失函数的梯度。
关键思想是:
-
从目标函数 $J$ 出发,逐层向输入方向回溯
-
每一层的梯度是其输出梯度和当前操作的局部梯度的乘积
企业实战理解
在 Google、OpenAI 等企业中,大型模型训练中反向传播的优化是重点工作:
-
混合精度训练(Mixed Precision Training):将部分梯度用半精度(float16)计算,减少显存使用和提升速度(如 NVIDIA A100 专门优化的 AMP 技术)。
-
分布式反向传播(Distributed Backpropagation):字节跳动在千亿参数推荐系统中使用 AllReduce 技术同步各 GPU 上的梯度。
反向传播自动求导系统(Autograd Engine)如 PyTorch 的 Autograd 和 TensorFlow 的 Eager Execution,就是围绕计算图自动实现链式反推。
5.3.4. 🏋️♂️ 训练神经网络
训练时,前向传播和反向传播紧密配合:
-
前向传播:沿计算图正向计算中间变量。
-
反向传播:逆序沿计算图传播误差信号,逐步计算各参数的梯度。
在每次参数更新前,我们必须:
-
保留前向传播中的中间变量(用于反向传播计算)
-
注意内存开销,因为中间变量的数量和 batch size 成正比
所以,batch size 太大容易导致显存爆炸(out-of-memory, OOM)。
理论理解
训练神经网络本质上是反复交替执行:
-
前向传播:计算输出和损失
-
反向传播:计算梯度
-
优化器更新:使用梯度更新模型参数
这个流程在每个 mini-batch 上执行一次,称为一次 iteration,多个 iteration 完成一次 epoch。
特别注意:
-
前向传播过程中,必须缓存中间变量
-
反向传播过程中,需要用到这些中间变量
-
所以训练阶段内存开销比推理阶段大很多
企业实战理解
在工业界训练大规模模型时,一般采用以下策略:
-
Checkpointing 重计算策略:在前向传播时只保存部分节点,其他节点在反向传播时临时重算,以节省显存(Google、DeepMind 大规模模型如 AlphaFold2 使用此策略)。
-
微批处理(Micro-batch):将大的 batch 拆成多个小 batch 分步训练,累积梯度后一起更新,缓解内存压力。
-
异步更新(如 Parameter Server 架构):在阿里巴巴推荐系统中,为了提升吞吐量,采用异步梯度下发机制(Async SGD)。
5.3.5. ✨ 小结
-
前向传播:计算各层输出,存储中间结果。
-
反向传播:反向传播误差信号,计算各参数梯度。
-
前向与反向传播交替进行,共同完成深度学习模型训练。
-
深度学习训练通常比推理(预测)需要更多内存。
理论理解
-
前向传播沿计算图正向计算所有中间变量
-
反向传播逆向传播误差信号,按链式法则计算梯度
-
前向传播和反向传播互为依赖,缺一不可
-
训练需要比推理更多的内存资源
企业实战理解
-
Google、NVIDIA 在超大模型(如 PaLM、Megatron)训练中,极致优化前向和反向传播 pipeline
-
字节跳动推荐系统工程中,为了应对巨量模型参数(上万亿),专门定制了反向传播高效内存管理系统
-
OpenAI 在训练 GPT-4 时,为反向传播引入了稀疏化策略(Sparsity-Aware Backprop),减少了计算与存储负担
🔥 小练习(思考题)
-
如果输入是矩阵,输出是标量,$\frac{\partial y}{\partial X}$ 的维度是什么?
-
在模型隐藏层添加偏置项,绘制新的计算图,并推导出更新的前向和后向传播公式。
-
估算训练 vs 推理时的内存占用差异。
-
二阶导数的计算对计算图有什么影响?
-
当计算图太大时,如何在多个 GPU 上进行分区?优缺点是什么?




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











