








2.Stream流
2.1体验Stream流【理解】
-
案例需求
按照下面的要求完成集合的创建和遍历
-
创建一个集合,存储多个字符串元素
-
把集合中所有以"张"开头的元素存储到一个新的集合
-
把"张"开头的集合中的长度为3的元素存储到一个新的集合
-
遍历上一步得到的集合
-
-
原始方式示例代码
public class MyStream1 { public static void main(String[] args) { //集合的批量添加 ArrayList<String> list1 = new ArrayList<>(List.of("张三丰","张无忌","张翠山","王二麻子","张良","谢广坤")); //list.add() //遍历list1把以张开头的元素添加到list2中。 ArrayList<String> list2 = new ArrayList<>(); for (String s : list1) { if(s.startsWith("张")){ list2.add(s); } } //遍历list2集合,把其中长度为3的元素,再添加到list3中。 ArrayList<String> list3 = new ArrayList<>(); for (String s : list2) { if(s.length() == 3){ list3.add(s); } } for (String s : list3) { System.out.println(s); } } } -
使用Stream流示例代码
public class StreamDemo { public static void main(String[] args) { //集合的批量添加 ArrayList<String> list1 = new ArrayList<>(List.of("张三丰","张无忌","张翠山","王二麻子","张良","谢广坤")); //Stream流 list1.stream().filter(s->s.startsWith("张")) .filter(s->s.length() == 3) .forEach(s-> System.out.println(s)); } } -
Stream流的好处
-
直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流、过滤姓张、过滤长度为3、逐一打印
-
Stream流把真正的函数式编程风格引入到Java中
-
代码简洁
-
理论理解:
Stream流是Java 8 引入的新特性,旨在简化集合操作,让数据处理更像“声明式流水线”。核心优势是:
-
链式调用:多个处理步骤可以无缝连接,极大简化代码结构。
-
懒执行机制:中间操作不会立即执行,只有调用终结方法时才触发,避免了不必要的计算。
-
可读性强:每一步处理逻辑一目了然,告别层层for循环的繁琐。
企业实战理解(BAT、字节、Google、NVIDIA、OpenAI):
-
字节跳动: 推荐系统中用Stream处理大批量用户行为数据,快速筛选符合条件的推荐内容。
-
阿里巴巴: 在中台商品服务中,用Stream实现商品数据的分组、过滤、分页等操作,优化代码结构。
-
Google: 内部工具使用Stream流处理批量数据日志,并在MapReduce等分布式场景中结合使用。
-
OpenAI: 在早期接口数据监控时,用Stream高效聚合、过滤模型调用记录。
面试题1:什么是Stream流?它的核心优势是什么?
参考答案:
Stream流是Java 8引入的新特性,主要用于对集合、数组等数据源进行高效、简洁、函数式风格的处理。Stream本质上是一个流水线,支持数据的筛选、转换、聚合等操作,它强调“什么做”而不是“怎么做”,即更偏向声明式编程。
Stream流的核心优势包括:
1️⃣ 简洁优雅的代码风格:支持链式调用,多个操作可以无缝连接,显著减少了for循环和中间变量的使用,使代码更易读、维护成本更低。
2️⃣ 懒加载机制:中间操作(如filter、map)不会立刻执行,只有遇到终结操作(如forEach、count)时才触发执行,这有助于节省资源,提高性能。
3️⃣ 内建并行计算支持:通过parallelStream(),可以简单地启用并行流,从而利用多核CPU的优势进行数据并行处理,极大提高了数据密集型任务的执行效率。
4️⃣ 函数式编程引入:结合Lambda表达式和函数式接口,Stream流使Java真正具备了函数式编程能力,提升了灵活性和表达能力。
大厂实战补充(字节/腾讯/Google):
字节的内容推荐系统广泛使用Stream流来实现数据筛选和分组逻辑,腾讯云在日志处理服务中利用Stream实现大规模数据的管道式处理,而Google在某些内部工具中通过Stream流快速组合MapReduce输入。
场景题1:美团外卖骑手任务筛选
题目:
美团外卖后台系统中有一个“骑手任务单”列表,现在你有一个List<RiderTask>集合,里面包含了骑手任务信息。每个任务对象有如下字段:
-
String riderName:骑手姓名 -
String area:送餐区域 -
String orderStatus:订单状态(如“已完成”、“待配送”、“已取消”) -
double distance:配送距离(单位:公里)
请用Stream流完成以下需求:
1️⃣ 筛选出“张三”所在的所有任务单。
2️⃣ 从中找出配送距离小于5公里的任务。
3️⃣ 提取这些任务的orderStatus,并去重后收集到List<String>中。
4️⃣ 统计满足条件的总任务数量。
参考答案:
List<RiderTask> tasks = ... // 模拟任务列表
// 1. 筛选张三的任务
List<RiderTask> zhangSanTasks = tasks.stream()
.filter(task -> "张三".equals(task.getRiderName()))
.collect(Collectors.toList());
// 2. 筛选距离小于5公里的任务
List<RiderTask> shortDistanceTasks = zhangSanTasks.stream()
.filter(task -> task.getDistance() < 5)
.collect(Collectors.toList());
// 3. 提取订单状态并去重
List<String> orderStatuses = shortDistanceTasks.stream()
.map(RiderTask::getOrderStatus)
.distinct()
.collect(Collectors.toList());
// 4. 统计总任务数量
long count = shortDistanceTasks.size();
System.out.println("张三的近距离任务状态列表: " + orderStatuses);
System.out.println("总任务数量: " + count);
思路解析:
这道题是典型的“分步式Stream流处理”场景,大厂(如美团)经常这样链式操作:
-
先筛选骑手名(filter)
-
再筛选距离条件(再filter)
-
通过map映射出你想要的字段
-
用distinct去重
-
用collect收集结果
-
用size或count统计
优点是代码一目了然,避免嵌套for循环写法,提高维护性。
2.2Stream流的常见生成方式【应用】
-
Stream流的思想
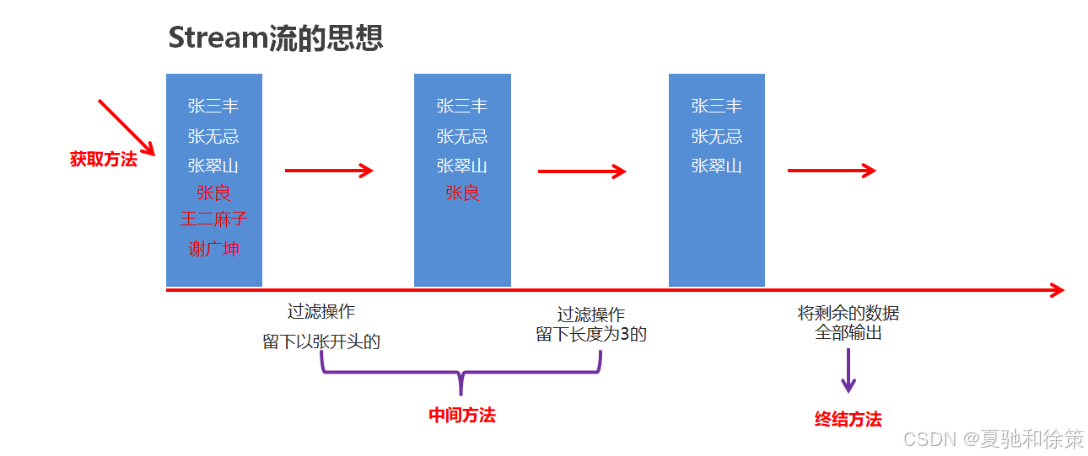
-
Stream流的三类方法
-
获取Stream流
-
创建一条流水线,并把数据放到流水线上准备进行操作
-
-
中间方法
-
流水线上的操作
-
一次操作完毕之后,还可以继续进行其他操作
-
-
终结方法
-
一个Stream流只能有一个终结方法
-
是流水线上的最后一个操作
-
-
-
生成Stream流的方式
-
Collection体系集合
使用默认方法stream()生成流, default Stream<E> stream()
-
Map体系集合
把Map转成Set集合,间接的生成流
-
数组
通过Arrays中的静态方法stream生成流
-
同种数据类型的多个数据
通过Stream接口的静态方法of(T... values)生成流
-
-
代码演示
public class StreamDemo { public static void main(String[] args) { //Collection体系的集合可以使用默认方法stream()生成流 List<String> list = new ArrayList<String>(); Stream<String> listStream = list.stream(); Set<String> set = new HashSet<String>(); Stream<String> setStream = set.stream(); //Map体系的集合间接的生成流 Map<String,Integer> map = new HashMap<String, Integer>(); Stream<String> keyStream = map.keySet().stream(); Stream<Integer> valueStream = map.values().stream(); Stream<Map.Entry<String, Integer>> entryStream = map.entrySet().stream(); //数组可以通过Arrays中的静态方法stream生成流 String[] strArray = {"hello","world","java"}; Stream<String> strArrayStream = Arrays.stream(strArray); //同种数据类型的多个数据可以通过Stream接口的静态方法of(T... values)生成流 Stream<String> strArrayStream2 = Stream.of("hello", "world", "java"); Stream<Integer> intStream = Stream.of(10, 20, 30); } }
理论理解:
Stream流来源广泛:集合、数组、甚至单个值序列,都可以轻松生成Stream流。生成后数据进入“流水线”进行一系列操作。
-
Collection接口的默认方法
stream()是最直接的入口。 -
数组类则通过
Arrays.stream()方法来生成流。 -
Stream.of() 则提供了“单独元素组装成流”的功能。
企业实战理解:
-
京东: 电商场景中,大批量的商品数据通过
List.stream()快速处理。 -
百度: 日志系统读取多维数组数据,使用
Arrays.stream()批量清洗。 -
亚马逊AWS: 通过
Stream.of()动态构造配置参数流,实现灵活的云服务配置加载。
面试题2:Stream流有哪些常用生成方式?分别应用在什么场景?
参考答案:
Stream流的生成方式主要分为以下几类:
1️⃣ 集合(Collection)生成流:
所有Collection子类(如List、Set)都可以通过stream()方法生成流。这是最常见的生成方式,适用于大多数业务场景。
👉 例子:List<String> list = ...; list.stream();
2️⃣ Map生成流:
Map本身没有stream方法,但可以通过其keySet()、values()、entrySet()方法间接生成流。
👉 例子:Map<String, Integer> map = ...; map.entrySet().stream();
3️⃣ 数组生成流:
通过Arrays.stream(数组)生成流,适用于已有数组的数据场景。
👉 例子:String[] arr = ...; Arrays.stream(arr);
4️⃣ Stream.of()生成流:
适用于创建少量元素的流,通常用于测试或临时拼装数据。
👉 例子:Stream.of("a", "b", "c");
5️⃣ 无限流生成(了解):
如Stream.iterate()、Stream.generate()可以生成无限流,适用于特殊算法场景。
大厂实战补充(京东/阿里/OpenAI):
阿里在大促场景中,结合List.stream()处理商品库存;京东用entrySet().stream()聚合订单数据;OpenAI内部数据处理脚本利用Arrays.stream()读取配置数组并动态加载。
场景题2:阿里电商订单处理系统
题目:
阿里电商后台有一个List<Order>订单列表,每个订单有如下属性:
-
String orderId -
String buyerName -
double totalPrice -
List<String> productList
要求:
1️⃣ 找出订单金额超过1000元的所有订单ID;
2️⃣ 找到包含“手机”关键词的订单(productList中包含“手机”);
3️⃣ 合并这两类订单的订单ID并去重,放到一个Set中。
参考答案:
List<Order> orders = ... // 模拟订单列表
// 1. 筛选金额超过1000的订单ID
Stream<String> highValueOrderIds = orders.stream()
.filter(order -> order.getTotalPrice() > 1000)
.map(Order::getOrderId);
// 2. 筛选包含“手机”的订单ID
Stream<String> phoneOrderIds = orders.stream()
.filter(order -> order.getProductList().stream().anyMatch(product -> product.contains("手机")))
.map(Order::getOrderId);
// 3. 合并去重收集到Set
Set<String> finalOrderIds = Stream.concat(highValueOrderIds, phoneOrderIds)
.collect(Collectors.toSet());
System.out.println("高价值/包含手机的订单ID集合: " + finalOrderIds);
思路解析:
这里的关键点是:
-
处理嵌套集合(
productList)时用到anyMatch -
两个流通过
Stream.concat拼接 -
最终用
Collectors.toSet()完成去重
在大厂场景(阿里、京东)下,这类问题典型用于处理订单筛选逻辑,比如黑五活动时筛选高消费订单+热门商品组合单。
2.3Stream流中间操作方法【应用】
-
概念
中间操作的意思是,执行完此方法之后,Stream流依然可以继续执行其他操作
-
常见方法
方法名 说明 Stream<T> filter(Predicate predicate) 用于对流中的数据进行过滤 Stream<T> limit(long maxSize) 返回此流中的元素组成的流,截取前指定参数个数的数据 Stream<T> skip(long n) 跳过指定参数个数的数据,返回由该流的剩余元素组成的流 static <T> Stream<T> concat(Stream a, Stream b) 合并a和b两个流为一个流 Stream<T> distinct() 返回由该流的不同元素(根据Object.equals(Object) )组成的流 -
filter代码演示
public class MyStream3 { public static void main(String[] args) { // Stream<T> filter(Predicate predicate):过滤 // Predicate接口中的方法 boolean test(T t):对给定的参数进行判断,返回一个布尔值 ArrayList<String> list = new ArrayList<>(); list.add("张三丰"); list.add("张无忌"); list.add("张翠山"); list.add("王二麻子"); list.add("张良"); list.add("谢广坤"); //filter方法获取流中的 每一个数据. //而test方法中的s,就依次表示流中的每一个数据. //我们只要在test方法中对s进行判断就可以了. //如果判断的结果为true,则当前的数据留下 //如果判断的结果为false,则当前数据就不要. // list.stream().filter( // new Predicate<String>() { // @Override // public boolean test(String s) { // boolean result = s.startsWith("张"); // return result; // } // } // ).forEach(s-> System.out.println(s)); //因为Predicate接口中只有一个抽象方法test //所以我们可以使用lambda表达式来简化 // list.stream().filter( // (String s)->{ // boolean result = s.startsWith("张"); // return result; // } // ).forEach(s-> System.out.println(s)); list.stream().filter(s ->s.startsWith("张")).forEach(s-> System.out.println(s)); } } -
limit&skip代码演示
public class StreamDemo02 { public static void main(String[] args) { //创建一个集合,存储多个字符串元素 ArrayList<String> list = new ArrayList<String>(); list.add("林青霞"); list.add("张曼玉"); list.add("王祖贤"); list.add("柳岩"); list.add("张敏"); list.add("张无忌"); //需求1:取前3个数据在控制台输出 list.stream().limit(3).forEach(s-> System.out.println(s)); System.out.println("--------"); //需求2:跳过3个元素,把剩下的元素在控制台输出 list.stream().skip(3).forEach(s-> System.out.println(s)); System.out.println("--------"); //需求3:跳过2个元素,把剩下的元素中前2个在控制台输出 list.stream().skip(2).limit(2).forEach(s-> System.out.println(s)); } } -
concat&distinct代码演示
public class StreamDemo03 { public static void main(String[] args) { //创建一个集合,存储多个字符串元素 ArrayList<String> list = new ArrayList<String>(); list.add("林青霞"); list.add("张曼玉"); list.add("王祖贤"); list.add("柳岩"); list.add("张敏"); list.add("张无忌"); //需求1:取前4个数据组成一个流 Stream<String> s1 = list.stream().limit(4); //需求2:跳过2个数据组成一个流 Stream<String> s2 = list.stream().skip(2); //需求3:合并需求1和需求2得到的流,并把结果在控制台输出 // Stream.concat(s1,s2).forEach(s-> System.out.println(s)); //需求4:合并需求1和需求2得到的流,并把结果在控制台输出,要求字符串元素不能重复 Stream.concat(s1,s2).distinct().forEach(s-> System.out.println(s)); } }
理论理解:
中间操作方法就是“加工步骤”。它们每次调用后都会返回一个新的Stream对象,并能继续后续操作,支持链式风格:
-
filter()用于条件筛选; -
limit()、skip()控制元素范围; -
concat()用于合并多个流; -
distinct()则实现去重。
企业实战理解:
-
字节跳动: 视频审核流程中,通过
filter()过滤违规内容,结合distinct()去除重复举报数据。 -
美团: 商家商品列表用
skip()和limit()实现高性能分页。 -
Google: 内部数据流处理中常用
concat()将多个来源的数据合并分析。
面试题3:Stream流的中间操作有哪些?请说明作用及典型应用。
参考答案:
中间操作方法的核心作用是对数据进行筛选、变换、组合等“加工”操作,主要包括:
-
filter(Predicate):过滤流中满足条件的元素。 -
map(Function):将每个元素映射为新形式(如类型转换)。 -
limit(long n):截取前n个元素。 -
skip(long n):跳过前n个元素。 -
distinct():去重。 -
sorted()/sorted(Comparator):自然排序或自定义排序。 -
flatMap(Function):扁平化处理,处理嵌套结构(如集合中的集合)。
典型应用场景:
-
filter:筛选满足业务规则的用户数据(如年龄>18)。
-
map:提取商品对象中的价格字段。
-
limit:实现分页查询的前n条数据。
-
skip:跳过已处理的数据块,实现分页的“下一页”功能。
-
distinct:防止重复数据入库。
大厂实战补充(字节/美团/腾讯):
字节的搜索系统用filter实现关键词精确过滤;美团外卖用distinct去重骑手任务单;腾讯视频用map批量提取视频播放量。
场景题3:字节跳动视频评论分析系统
题目:
字节跳动的视频后台中,每条视频对应List<Comment>评论对象,Comment对象有:
-
String userName -
String content -
int likeCount
需求:
1️⃣ 提取点赞数大于100的评论内容;
2️⃣ 只保留用户名以“王”开头的评论;
3️⃣ 合并这两类评论的内容并去重,统计总数量。
参考答案:
List<Comment> comments = ... // 模拟评论列表
// 1. 点赞数大于100的评论内容
Stream<String> likedComments = comments.stream()
.filter(comment -> comment.getLikeCount() > 100)
.map(Comment::getContent);
// 2. 用户名以“王”开头的评论内容
Stream<String> wangComments = comments.stream()
.filter(comment -> comment.getUserName().startsWith("王"))
.map(Comment::getContent);
// 3. 合并去重统计
List<String> finalComments = Stream.concat(likedComments, wangComments)
.distinct()
.collect(Collectors.toList());
System.out.println("符合条件的评论数量: " + finalComments.size());
System.out.println("评论内容列表: " + finalComments);
思路解析:
-
两次filter逻辑区分“点赞数”与“用户名”条件
-
map将对象转为字符串内容
-
合并(concat)和去重(distinct)是精髓
-
字节跳动/抖音经常有这类“评论分析”需求
2.4Stream流终结操作方法【应用】
-
概念
终结操作的意思是,执行完此方法之后,Stream流将不能再执行其他操作
-
常见方法
方法名 说明 void forEach(Consumer action) 对此流的每个元素执行操作 long count() 返回此流中的元素数 -
代码演示
public class MyStream5 { public static void main(String[] args) { ArrayList<String> list = new ArrayList<>(); list.add("张三丰"); list.add("张无忌"); list.add("张翠山"); list.add("王二麻子"); list.add("张良"); list.add("谢广坤"); //method1(list); // long count():返回此流中的元素数 long count = list.stream().count(); System.out.println(count); } private static void method1(ArrayList<String> list) { // void forEach(Consumer action):对此流的每个元素执行操作 // Consumer接口中的方法void accept(T t):对给定的参数执行此操作 //在forEach方法的底层,会循环获取到流中的每一个数据. //并循环调用accept方法,并把每一个数据传递给accept方法 //s就依次表示了流中的每一个数据. //所以,我们只要在accept方法中,写上处理的业务逻辑就可以了. list.stream().forEach( new Consumer<String>() { @Override public void accept(String s) { System.out.println(s); } } ); System.out.println("===================="); //lambda表达式的简化格式 //是因为Consumer接口中,只有一个accept方法 list.stream().forEach( (String s)->{ System.out.println(s); } ); System.out.println("===================="); //lambda表达式还是可以进一步简化的. list.stream().forEach(s->System.out.println(s)); } }
理论理解:
终结操作是流的“收尾”,一旦调用流就会被消费,不可再用。最典型的终结方法:
-
forEach():用于遍历并执行操作。 -
count():统计流中元素数量。
企业实战理解:
-
字节跳动: 审核平台用
forEach()把内容逐条输出到日志。 -
阿里云: 在后台服务中用
count()快速统计符合条件的实例数,监控健康状态。 -
OpenAI: 用
forEach()遍历模型日志,提取高风险请求。
面试题4:终结操作和中间操作的区别是什么?
参考答案:
-
中间操作:
-
返回Stream对象,允许链式调用。
-
特点是“懒执行”,只有在遇到终结操作时才真正开始执行。
-
例如:filter、map、limit、distinct等。
-
-
终结操作:
-
返回具体的值(如long、List、Map等)或执行具体动作(如forEach输出),不会再返回Stream对象。
-
一旦执行终结操作,流就会被“消费”,无法再次使用。
-
例如:forEach、count、collect、reduce等。
-
大厂考点提示(阿里/字节/Google):
大厂面试会经常提问Stream的懒执行机制和流不可重用特性,重点是能否解释“中间操作只定义流水线,终结操作才触发执行”的本质。
2.5Stream流的收集操作【应用】
-
概念
对数据使用Stream流的方式操作完毕后,可以把流中的数据收集到集合中
-
常用方法
方法名 说明 R collect(Collector collector) 把结果收集到集合中 -
工具类Collectors提供了具体的收集方式
方法名 说明 public static <T> Collector toList() 把元素收集到List集合中 public static <T> Collector toSet() 把元素收集到Set集合中 public static Collector toMap(Function keyMapper,Function valueMapper) 把元素收集到Map集合中 -
代码演示
// toList和toSet方法演示 public class MyStream7 { public static void main(String[] args) { ArrayList<Integer> list1 = new ArrayList<>(); for (int i = 1; i <= 10; i++) { list1.add(i); } list1.add(10); list1.add(10); list1.add(10); list1.add(10); list1.add(10); //filter负责过滤数据的. //collect负责收集数据. //获取流中剩余的数据,但是他不负责创建容器,也不负责把数据添加到容器中. //Collectors.toList() : 在底层会创建一个List集合.并把所有的数据添加到List集合中. List<Integer> list = list1.stream().filter(number -> number % 2 == 0) .collect(Collectors.toList()); System.out.println(list); Set<Integer> set = list1.stream().filter(number -> number % 2 == 0) .collect(Collectors.toSet()); System.out.println(set); } } /** Stream流的收集方法 toMap方法演示 创建一个ArrayList集合,并添加以下字符串。字符串中前面是姓名,后面是年龄 "zhangsan,23" "lisi,24" "wangwu,25" 保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值 */ public class MyStream8 { public static void main(String[] args) { ArrayList<String> list = new ArrayList<>(); list.add("zhangsan,23"); list.add("lisi,24"); list.add("wangwu,25"); Map<String, Integer> map = list.stream().filter( s -> { String[] split = s.split(","); int age = Integer.parseInt(split[1]); return age >= 24; } // collect方法只能获取到流中剩余的每一个数据. //在底层不能创建容器,也不能把数据添加到容器当中 //Collectors.toMap 创建一个map集合并将数据添加到集合当中 // s 依次表示流中的每一个数据 //第一个lambda表达式就是如何获取到Map中的键 //第二个lambda表达式就是如何获取Map中的值 ).collect(Collectors.toMap( s -> s.split(",")[0], s -> Integer.parseInt(s.split(",")[1]) )); System.out.println(map); } }
理论理解:
Stream流不仅能处理数据,还可以通过collect()方法把数据“收回来”。常见收集器:
-
Collectors.toList()→ 收集到List -
Collectors.toSet()→ 收集到Set -
Collectors.toMap()→ 收集到Map
这让Stream既有“计算力”又有“存储力”。
企业实战理解:
-
腾讯云: 大规模日志分析后,用
toList()封装成分页对象。 -
京东: 使用
toSet()快速去重SKU列表,提高数据清洁度。 -
阿里巴巴: 将订单数据通过
toMap()聚合为“订单号→详情”的映射关系。
面试题5:Stream流为什么是“懒执行”?它是怎么实现的?
参考答案:
Stream流的“懒执行”是指中间操作不会立即执行,而是等到终结操作执行时才开始计算。这是为了提高性能,避免不必要的中间结果计算,并支持优化操作(如短路操作limit、findFirst)。
其实现依赖于:
-
内部维护了一个操作链(Pipeline):每次中间操作都会将操作逻辑加入到Pipeline中,而不是立刻执行。
-
只有遇到终结操作时才触发执行:Stream内部会遍历整个Pipeline链条,将数据源中的元素依次通过各个中间操作处理,最后汇聚到终结方法。
大厂实战补充(腾讯/阿里):
腾讯面试会追问:为什么limit可以优化处理性能?因为流是一次一批处理的(惰性求值),当limit满足条件后后续数据根本不会加载,提高了效率。
2.6Stream流综合练习【应用】
-
案例需求
现在有两个ArrayList集合,分别存储6名男演员名称和6名女演员名称,要求完成如下的操作
-
男演员只要名字为3个字的前三人
-
女演员只要姓林的,并且不要第一个
-
把过滤后的男演员姓名和女演员姓名合并到一起
-
把上一步操作后的元素作为构造方法的参数创建演员对象,遍历数据
演员类Actor已经提供,里面有一个成员变量,一个带参构造方法,以及成员变量对应的get/set方法
-
-
代码实现
演员类
public class Actor { private String name; public Actor(String name) { this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } }测试类
public class StreamTest { public static void main(String[] args) { //创建集合 ArrayList<String> manList = new ArrayList<String>(); manList.add("周润发"); manList.add("成龙"); manList.add("刘德华"); manList.add("吴京"); manList.add("周星驰"); manList.add("李连杰"); ArrayList<String> womanList = new ArrayList<String>(); womanList.add("林心如"); womanList.add("张曼玉"); womanList.add("林青霞"); womanList.add("柳岩"); womanList.add("林志玲"); womanList.add("王祖贤"); //男演员只要名字为3个字的前三人 Stream<String> manStream = manList.stream().filter(s -> s.length() == 3).limit(3); //女演员只要姓林的,并且不要第一个 Stream<String> womanStream = womanList.stream().filter(s -> s.startsWith("林")).skip(1); //把过滤后的男演员姓名和女演员姓名合并到一起 Stream<String> stream = Stream.concat(manStream, womanStream); // 将流中的数据封装成Actor对象之后打印 stream.forEach(name -> { Actor actor = new Actor(name); System.out.println(actor); }); } }
理论理解:
这个案例体现了Stream的灵活性:
-
多个过滤条件
-
不同数据源的合并
-
转换成对象并打印输出
它把流的全流程(生成 → 中间 → 终结)都串了起来。
企业实战理解:
-
美团外卖: 筛选活跃骑手+高评分商家,并把他们封装成任务对象派单。
-
滴滴: 聚合司机和乘客数据,过滤特定条件后生成行程单。
-
OpenAI: 结合多源API日志,把筛选出的异常接口封装成告警对象推送。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











