







mysql8.0之后对子查询的优化得到大幅提升
为什么使用子查询
更符合逻辑,如“找到1993年,没有下过订单的客户数量”
select count(c_custerkey) cnt
from
customer
where c_custerkey not in(
select o_custerkey
from orders
where
o_orderdate >= '1993-01-01'
And
o_orderdate < '1994-01-01'
)
通过notin查询不在订单表的用户有哪些
可以使用leftjoin(在customer存在,在orders不存在)
select count(c_custerkey) cnt
from
customer
left join
orders on
customer.c_custerkey = orders.o_custerkey
and o_orderdate >='1993-01-01'
and o_orderdate < '1994-01-01'
where
o_custerkey is null
LEFT JOIN 更易于理解,能进行传统 JOIN 的两表连接,而子查询则要求优化器聪明地将其转换为最优的 JOIN 连接
l两种sql语句最终的执行计划
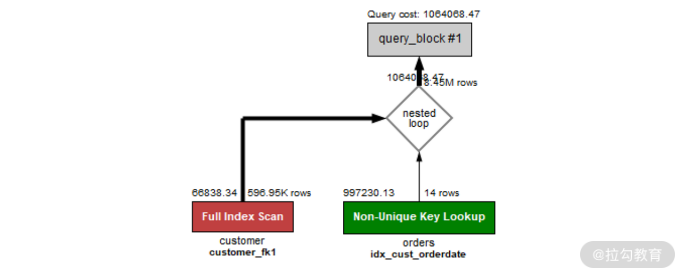
可以看到,不论是子查询还是 LEFT JOIN,最终都被转换成了 Nested Loop Join,所以上述两条 SQL 的执行时间是一样的。
即,在 MySQL 8.0 中,优化器会自动地将 IN 子查询优化,优化为最佳的 JOIN 执行计划,这样一来,会显著的提升性能。
子查询 IN 和 EXISTS
将上述列子中not in改为 not exists 比较
select count(c_custerkey) cnt
from
customer
where c_custerkey not exists(
select o_custerkey
from orders
where
o_orderdate >= '1993-01-01'
And
o_orderdate < '1994-01-01'
)
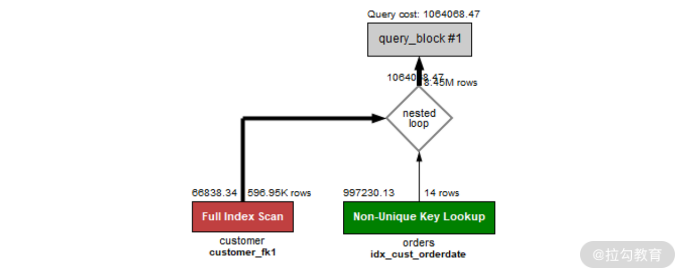
它和 NOT IN 的子查询执行计划一模一样,所以二者的性能也是一样的
子查询优化
在 MySQL 8.0 版本之前,MySQL 对于子查询的优化并不充分。所以在子查询的执行计划中会看到 DEPENDENT SUBQUERY 的提示,这表示是一个依赖子查询,子查询需要依赖外部表的关联。
如果你看到这样的提示,就要警惕, 因为 DEPENDENT SUBQUERY 执行速度可能非常慢,大部分时候需要你手动把它转化成两张表之间的连接。
计算出每个员工最后成交的订单时间
select * from orders
where
(o_clerk,o_orderdate) in
(
select o_clerk,Max(o_orderdate)
from orders
group by o_clerk
);
通过命令 EXPLAIN FORMAT=tree 输出执行计划,你可以看到,第 3 行有这样的提示:Select #2 (subquery in condition; run only once)。这表示子查询只执行了一次,然后把最终的结果保存起来了。
执行计划的第 6 行Index lookup on <materialized_subquery>,表示对表 orders 和子查询结果所得到的表进行 JOIN 连接,最后返回结果。
所以,当前这个执行计划是对表 orders 做2次扫描,每次扫描约 5587618 条记录:
-
第 1 次扫描,用于内部的子查询操作,计算出每个员工最后一次成交的时间;
-
第 2 次表 oders 扫描,查询并返回每个员工的订单信息,即返回每个员工最后一笔成交的订单信息。
最后,直接用命令 EXPLAIN 查看执行计划,如下图所示:
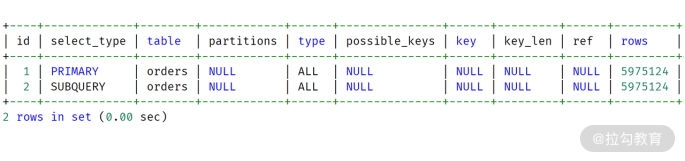
MySQL 8.0 版本执行过程
如果是老版本的 MySQL 数据库,它的执行计划将会是依赖子查询,执行计划如下所示:
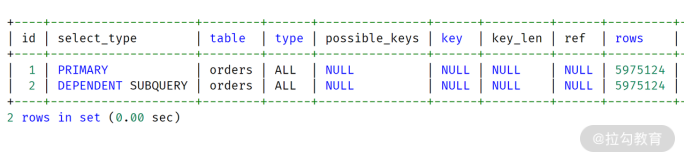
老版本 MySQL 执行过程
对比 MySQL 8.0,只是在第二行的 select_type 这里有所不同,一个是 SUBQUERY,一个是DEPENDENT SUBQUERY。
接着通过命令 EXPLAIN FORMAT=tree 查看更详细的执行计划过程:
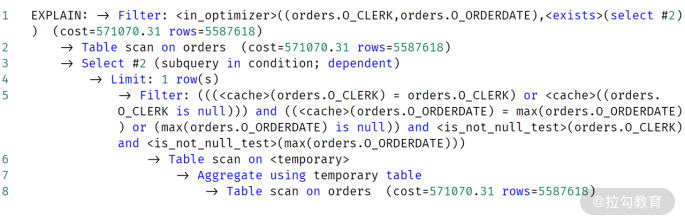
可以发现,第 3 行的执行技术输出是:Select #2 (subquery in condition; dependent),并不像先前的执行计划,提示只执行一次。另外,通过第 1 行也可以发现,这条 SQL 变成了 exists 子查询,每次和子查询进行关联。
所以,上述执行计划其实表示:先查询每个员工的订单信息,接着对每条记录进行内部的子查询进行依赖判断。也就是说,先进行外表扫描,接着做依赖子查询的判断。所以,子查询执行了5587618,而不是1次!!!
所以,两者的执行计划,扫描次数的对比如下所示:
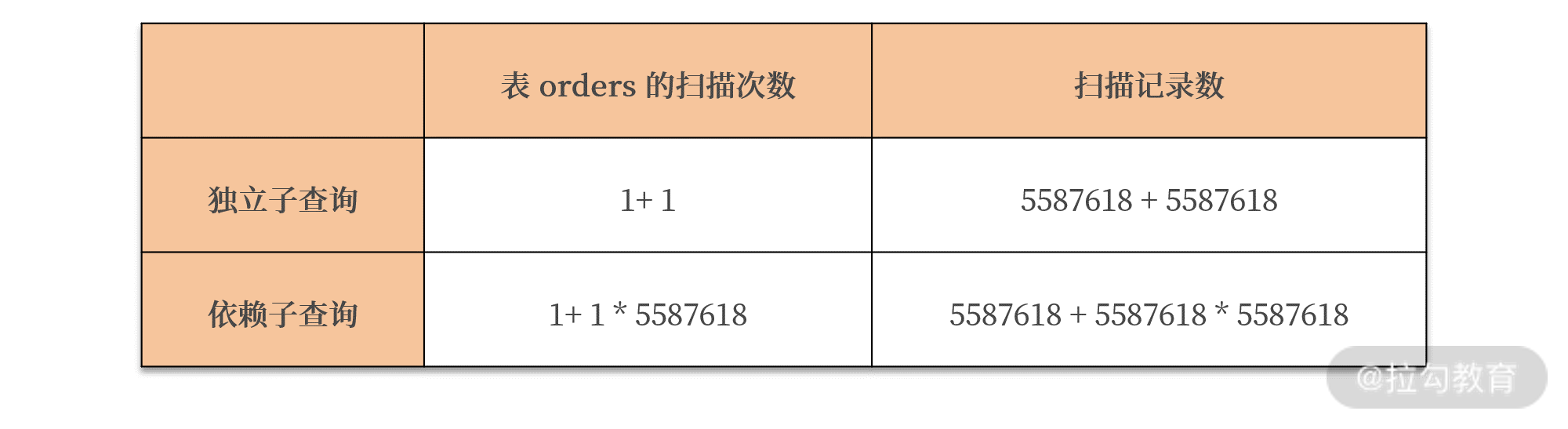
对于依赖子查询的优化,就是要避免子查询由于需要对外部的依赖,而需要对子查询扫描多次的情况。所以可以通过派生表的方式,将外表和子查询的派生表进行连接,从而降低对于子查询表的扫描,从而提升 SQL 查询的性能。
那么对于上面的这条 SQL ,可将其重写为:
SELECT * FROM orders o1,
(
SELECT
o_clerk, MAX(o_orderdate)
FROM
orders
GROUP BY o_clerk
) o2
WHERE
o1.o_clerk = o2.o_clerk
AND o1.o_orderdate = o2.orderdate;
可以看到,我们将子查询改写为了派生表 o2,然后将表 o2 与外部表 orders 进行关联。关联的条件是:o1.o_clerk = o2.o_clerk AND o1.o_orderdate = o2.orderdate。
通过上面的重写后,派生表 o2 对表 orders 进行了1次扫描,返回约 5587618 条记录。派生表o1 对表 orders 扫描 1 次,返回约 1792612 条记录。这与 8.0 的执行计划就非常相似了,其执行计划如下所示:
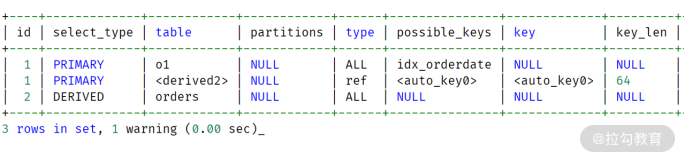
最后,来看下上述 SQL 的执行时间:
可以看到,经过 SQL 重写后,派生表的执行速度几乎与独立子查询一样。所以,若看到依赖子查询的执行计划,记得先进行 SQL 重写优化哦。
知识点来自学习-姜承尧老师拉钩网教导内容。















 87
87











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









