






一、大数据分析技术概述
1.1 数据分析
1.2 数据仓库
1.3 数据建模
1.4 大数据的基本概念和特征
1.5 大数据处理技术
二、Hadoop
2.1 Hadoop简介
2.2 Hadoop发展简史
2.3 Hadoop的特性
2.4 Hadoop的应用
2.5 Hadoop版本演变
2.6 Hadoop生态系统
三、分布式文件系统(Distributed File System,DFS)
3.1 文件系统的定义
文件系统是一种存储和组织数据的方法,实现了数据的存储、分级组织、访问和获取等操作,使得用户对文件访问和查找变得容易
文件系统使用树形目录的抽象逻辑概念代替 了硬盘等物理设备使用数据块的概念,用户不必关心数据底层存在硬盘哪里,只需要记住这个文件的所属目录和文件名即可
文件系统通常使用硬盘和光盘这样的存储设备,并维护文件在设备中的物理位置。
3.2 传统常见的文件系统
传统常见的文件系统更多指的是单机的文件系统,也就是底层不会横跨多台机器实现。比如windows操作系统上的文件系统、Linux上的文件系统、FTP文件系统等等。
传统 文件系统的共同特征包括:
①带有抽象的目录树结构,树都是从/根目录开始往下蔓延
②树中节点分为两类:目录和文件
③从根目录开始,节点路径具有唯一性,不能重名
3.3 数据、元数据
3.3.1 数据
指存储的内容本身,比如文件、视频、图片等,这些数据底层最终是存储在磁盘等存储介质上的,一般用户无需关心,只需要基于目录树进行增删改查即可,实际针对数据的操作由文件系统完成。
3.3.2 元数据
元数据(metadata)又称之为解释性数据,记录数据的数据
文件系统元数据一般指文件大小、最后修改时间、底层存储位置、属性、所属用户、权限等信息,元数据是数据的属性信息
海量数据存储遇到的问题
- 成本高
传统存储硬件通用性差,设备投资加上后期维护、升级扩容的成本非常高
- 如何支撑高效率的计算分析
传统存储方式意味着数据:存储是存储,计算是计算,当需要处理数据的时候把数据移动过来。程序和数据存储是属于不同的技术厂商实现,无法有机统一整合在一起。
- 性能低
单节点I/O性能瓶颈无法逾越,难以支撑海量数据的高并发高吞吐场景
- 可拓展性差
无法实现快速部署和弹性拓展,动态扩容、缩容成本高,技术实现难度大
3.4 分布式存储系统核心属性
- 分布式存储
- 元数据记录
- 分块存储
- 副本机制
3.4.1 分布式存储的优点
- 问题:数据量大,单机存储(传统存储方式)遇到瓶颈
- 解决:
单机纵向拓展:磁盘不够加磁盘,有上限瓶颈限制
多机横向拓展:机器不够加机器,理论上无限拓展

3.4.2 元数据记录功能
- 问题:文件分布在不同机器上不利于寻找
- 解决:元数据记录下文件及其存储位置信息,快速定位文件位置
3.4.3 分块存储好处
- 问题:文件过大导致单机存不下、上传下载效率低
- 解决:文件分块存储在不同机器,针对块并行操作(同时)提高效率
3.4.4 副本机制的作用
- 问题:硬件故障难以避免,数据易丢失
- 解决:不同机器设置备份,冗余存储,保障数据安全
3.1.1 计算机集群结构
计算机集群,简称”集群”,是一种计算机系统,它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作。
在某种意义上,它们可以被看作是一台计算机。集群系统中的单个计算机通常称为节点,通常通过局域网连接,也可能有其他的连接方式。
集群计算机通常用来改进单个计算机的计算速度和可靠性,一般情况下集群计算机比单个计算机、工作站或超级计算机性能价格比要高得多。
总结:集群就是一组相互独立的计算机,通过高速的网络组成一个计算机系统,每个集群节点都是运行其自己进程的一个独立服务器。对网络用户来讲,网站后端就是一个单一的系统,协同起来向用户提供系统资源,系统服务。通过网络连接组合成一个组合来共同完一个任务。
3.1.1 补:计算机系统
3.2 HDFS简介
- HDFS(Hadoop Distributed File System),意为:Hadoop分布式文件系统
- 是Apache Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在,也可以说大数据首先要解决的问题就是海量数据的存储问题
- HDFS主要是解决大数据如何存储问题的,分布式意味着HDFS是横跨在多台计算机上的存储系统
- HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据(比如TB和PB)
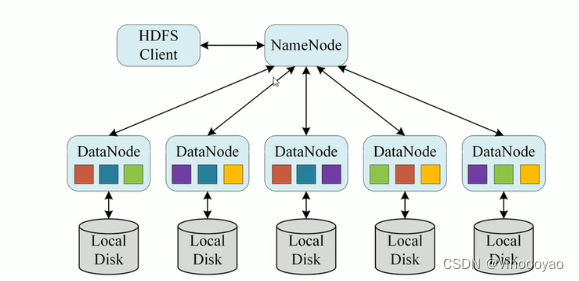
- HDFS使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统
HDFS Client代表的是用户,去访问文件系统
NameNode是名称节点,即主节点
DataNode是数据节点,即从节点
一主多从的分布式架构
3.2.1 HDFS起源发展
- Doug Cutting领导Nutch项目研发,Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能。
- 随着爬虫抓取网页数量的增加,遇到了严重的可拓展性问题——如何解决数十亿网页的存储和索引问题
- 2003年的时候,Google发表的论文为该问题提供了可行的解决方案。(《分布式文件系统(GFS),可用于处理海量网页的存储》)
- Nutch的开发人员完成了相应的开源实现HDFS,并从Nutch中剥离和MapReduce成为独立项目Hadoop
3.2.2 HDFS设计目标
- 硬件故障(Hardware Failure)是常态,HDFS可能有成百上千的服务器组成,每一个组件都有可能出现故障。因此故障检测和自动快速恢复是HDFS的核心架构目标
- HDFS上的应用主要是以流式读取数据(Streaming Data Access)。HDFS被设计成用于批处理,而不是用户交互式的。相较于数据访问的反应时间,更注重数据访问的高吞吐量
- 典型的HDFS文件大小是GB到TB的级别。所以,HDFS被调整成支持大文件(Large Data Sets)。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件
- 大部分HDFS应用对文件要求的是write-one-read-many(一次写入,多次读取)访问模型。一个文件一旦创建、写入、关闭之后就不需要修改了。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。
- 移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效。将计算移动到数据附件,比之将数据移动到应用所在显然更好。
- HDFS被设计为可从一个平台轻松移植到另一个平台,这有助于将HDFS广泛用作大量应用程序的首选平台。
3.2.3 HDFS应用场景
适合场景
- 大文件
- 数据流式访问
- 一次写入多次读取
- 低成本部署,廉价PC
- 高容错
不适合场景
- 小文件(并不是文件越小就存储不了,而是存储起来非常不适,浪费)
- 数据交互式访问
- 频繁任意修改
- 低延迟处理(满足不了数据交互式访问的需求,因为只注重数据吞吐,且数据延迟性高,所以数据任意频繁的修改都不可能)
3.2.3 HDFS的特性
整体概述
- 主从架构
- 分块存储
- 副本机制
- 元数据记录
- 抽象统一的目录树结构(namespace)
3.3 HDFS相关概念
3.4 HDFS体系结构
3.5 HDFS存储原理
3.6 HDFS数据读写过程
四、分布式计算系统MapReduce
4.1 MapReduce概述
4.2 MapReduce体系结构
4.3 MapReduce工作流程
4.4 MapReduce实例
五、资源调度框架YARN
5.1 Hadoop的优化与发展
5.2 YARN——资源管理调度框架
六、数据仓库工具Hive
6.1 Hive概述
6.1.1 什么是Hive
- Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似于SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集
- Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行
- Hive由Facebook实现并开源
6.1.2 为什么使用Hive
使用Hadoop MapReduce直接处理数据所面临的问题
- 人员学习成本太高 需要掌握iava语言
- MapReduce实现复杂查询逻辑开发难度太大
使用Hive处理数据的好处
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免直接写MapReduce,减少开发人员的学习成本
- SQL中有许多内置函数,也支持自定义函数,功能扩展很方便
- 背靠Hadoop,擅长存储分析海量数据集
6.1.3 Hive和Hadoop的关系(非常紧密的耦合关系)
- 从功能来说,数据仓库软件,至少需要具备下述两种能力:存储数据的能力、分析数据的能力
- Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
- Hive利用HDFS存储数据,利用MapReduce查询分析数据
- 这样突然发现Hive没啥用,不过是套壳Hadoop罢了。其实不然,Hive的最大的魅力在于用户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析
6.1.4 Hive功能模拟实现底层猜想
如果让您设计Hive这款软件,要求能够实现用户只编写SQL语句,Hive自动将SQL转换MapReduce程序,处理位于HDFS上的结构化数据。如何实现?
- 如何模拟实现Apache Hive的功能?
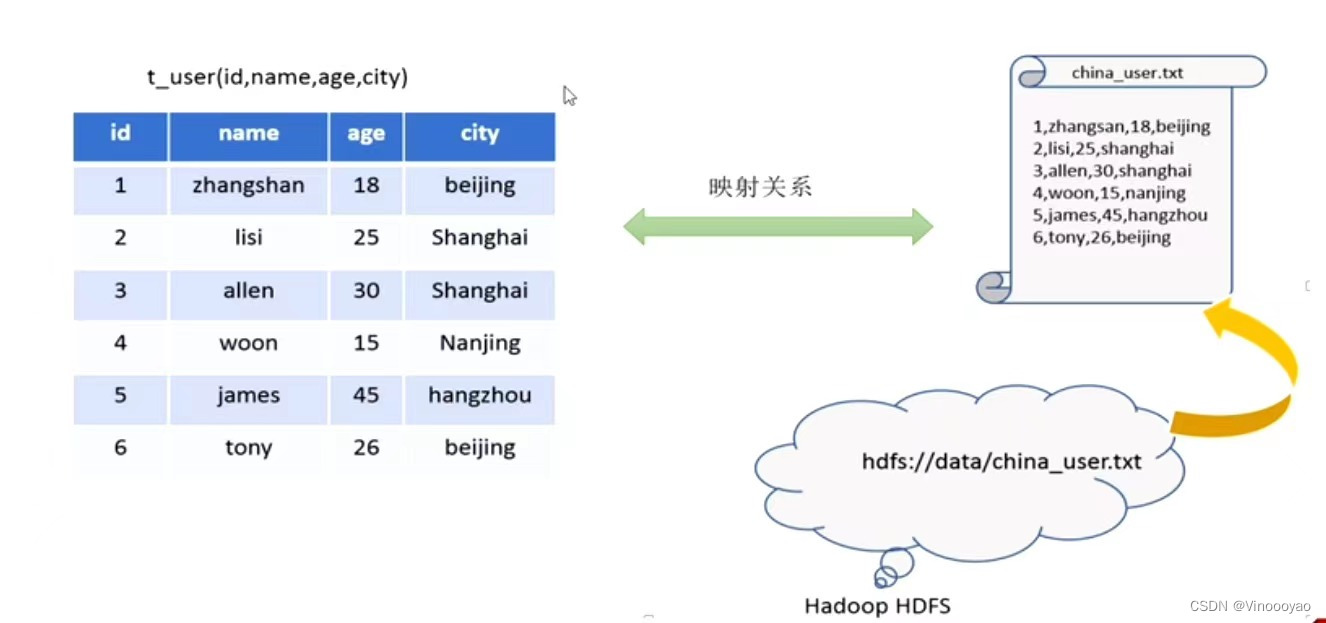
在HDFS文件系统上有一个文件,路径为/data/china_user.txt
需求:统计来自上海年龄大于25岁的用户有多少个?

重点理解下面两点:
①Hive能将数据文件映射成为一张表,这个映射是指什么?
②Hive软件本身到底承担了什么功能职责?
映射
- 映射在数学上称之为一种对应关系,比如y=x+1,对于每一个x的值都有与之对应的y的值
- 在Hive中能够写SQL处理的前提是针对表,而不是针对文件,因此需要将文件与表之间的对应关系描述记录清楚。映射信息专业的叫法称之为元数据信息(元数据是指用来描述数据的数据metadata)
映射信息记录
- 具体来看,要记录的元数据信息包括
表对应着哪个文件(位置信息)
表的列对应着文件哪一个字段(顺序信息)
文件字段之间的分隔符是什么
SQL语法解析、编译
- 用户写完SQL之后,Hive需要针对SQL进行语法校验,并且根据记录的元数据信息解读SQL背后的含义,制定执行计划
- 并且把执行计划转换成MapReduce程序来具体执行,把执行的结果封装返回给用户
对Hive的理解
①Hive能将数据文件映射成为一张表,这个映射是指什么?
指的是文件和表之间的对应关系
②Hive软件本身到底承担了什么功能职责?
承担了将用户的SQL语法解析编译成为MapReduce的职责
最终效果
- 基于上述分析,最终想要模拟实现的Hive的功能,大致需要下图所示组件参与其中
- 从中可以感受一下Hive承担了什么职责,当然也可以把这个理解为Hive的架构图

文件china_user.txt一定是一个结构化文件
该文件存储在Hadoop集群当中的HDFS中,意味着数据一定是存储在文件系统当中的
元数据存储系统是把那些映射信息对应的信息存储在当中,一旦映射信息记录的不详细,后续写SQL语句就会出问题
用户根据表写SQL,SQL将被Hive软件接收到,首先判断SQL语法写得对不对,接下来对SQL语句进行编译:理解SQL语句要干什么,用途是什么;用户写的时候操作的是表,我们转换成操作的是文件,通过查询元数据中记录的信息,知道表对应的是哪个文件。知道了执行计划之后,将执行计划编译成一个MapReduce程序,将程序提交到YARN执行,开始去申请资源、读取数据进行处理,将处理的最终结果返回给用户
Hive组件
6.2 Hive系统架构
6.3 Hive工作原理
6.4 Hive的数据类型
七、Sqoop
7.1 Sqoop简介
7.2 Sqoop工作原理
7.3 Sqoop安装部署
7.4 Sqoop数据导入导出
八、Apache Flume
8.1 Flume简介
8.2 Flume的架构
8.3 核心组件介绍
8.4 Flume配置演示
九、Kafka
9.1 Kafka简介
9.2 Kafka基础
9.3 Kafka集群架构
9.4 Kafka工作流程
数据仓库工具Hive
Hive概述
MapReduce的编程接口只支持编程语言,如Java、Python等;
MapReduce本身不支持SQL开发;
Hive是一款分布式SQL计算的工具,其主要功能是:将SQL语句翻译成MapReduce程序运行
总结:基于Hive 为用户提供了分布式SQL计算的能力,写的是SQL,执行的是MapReduce
编译技术
B+树用于数据库索引的实现















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









