







感谢朋友支持本博客,欢迎共同探讨交流,由于能力和时间有限,错误之处在所难免,欢迎指正!
如有转载,请保留源作者博客信息。
如需交流,欢迎大家博客留言。
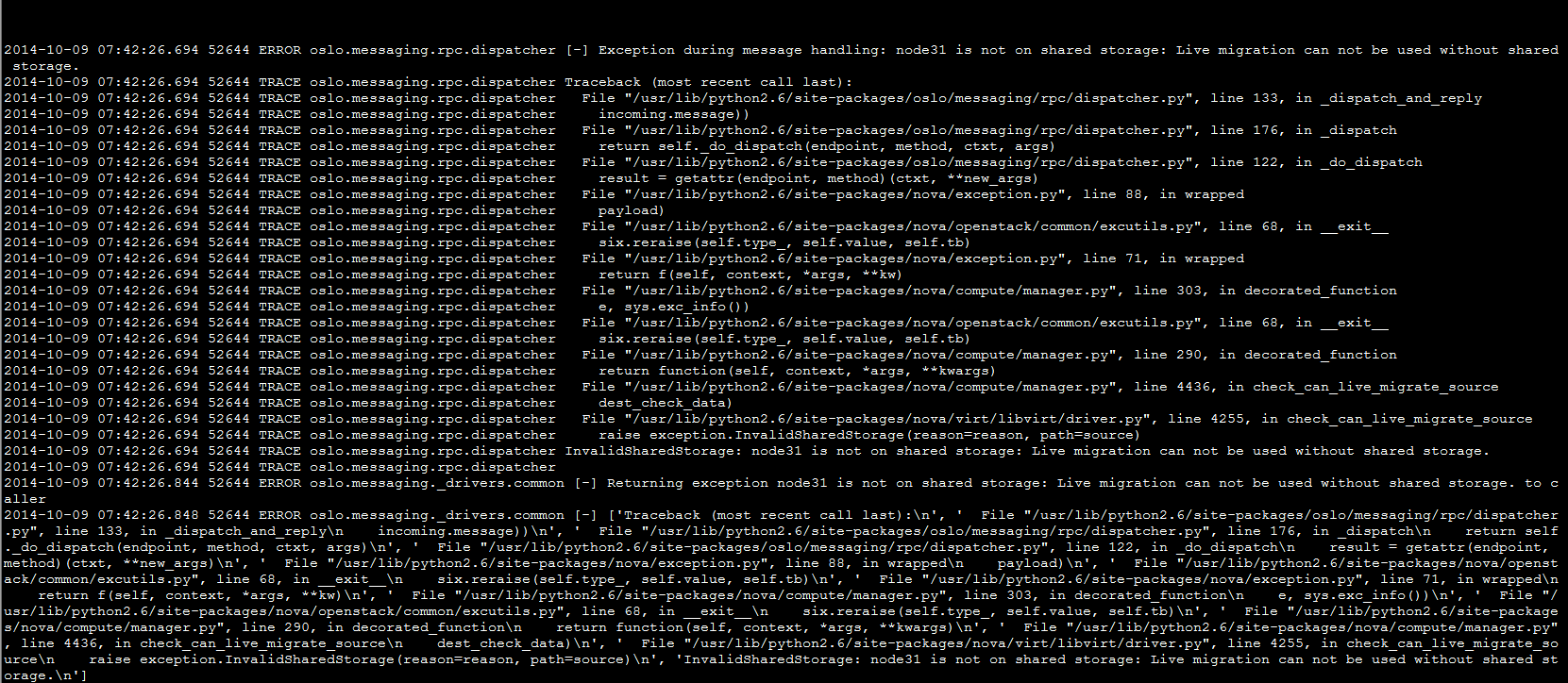
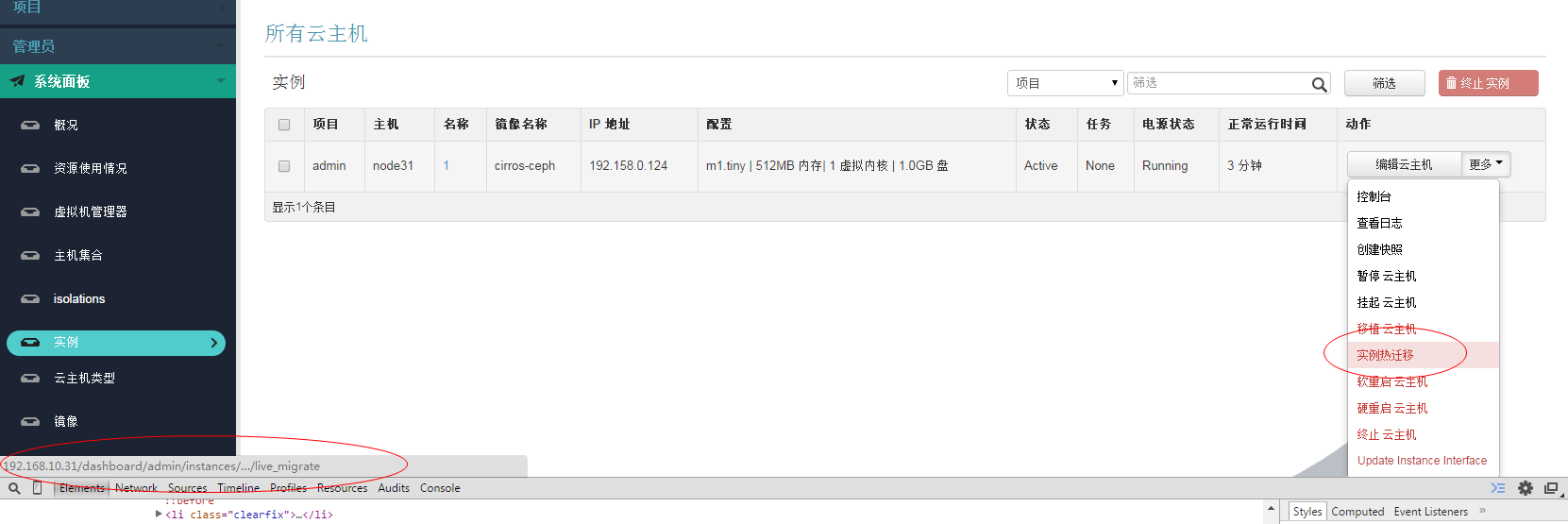
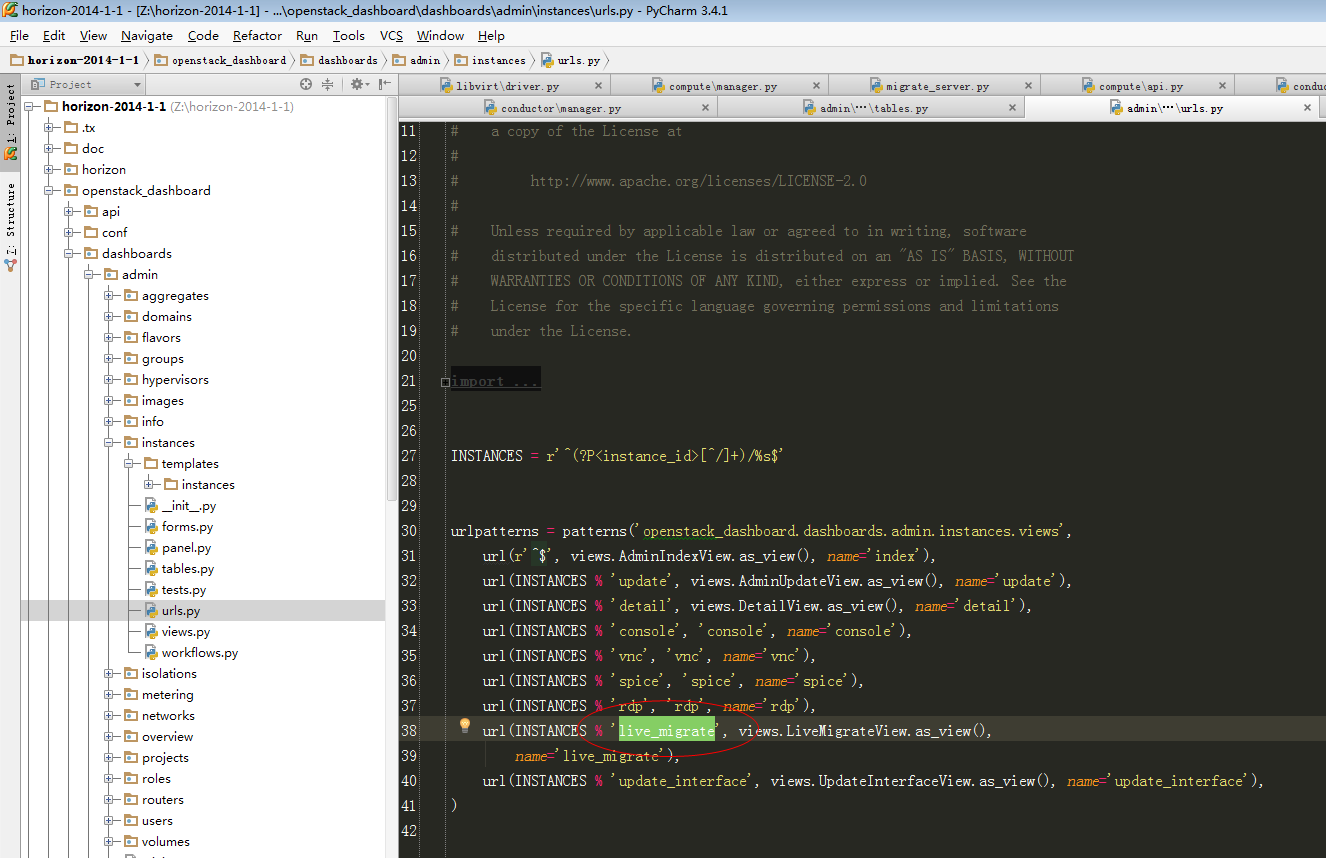
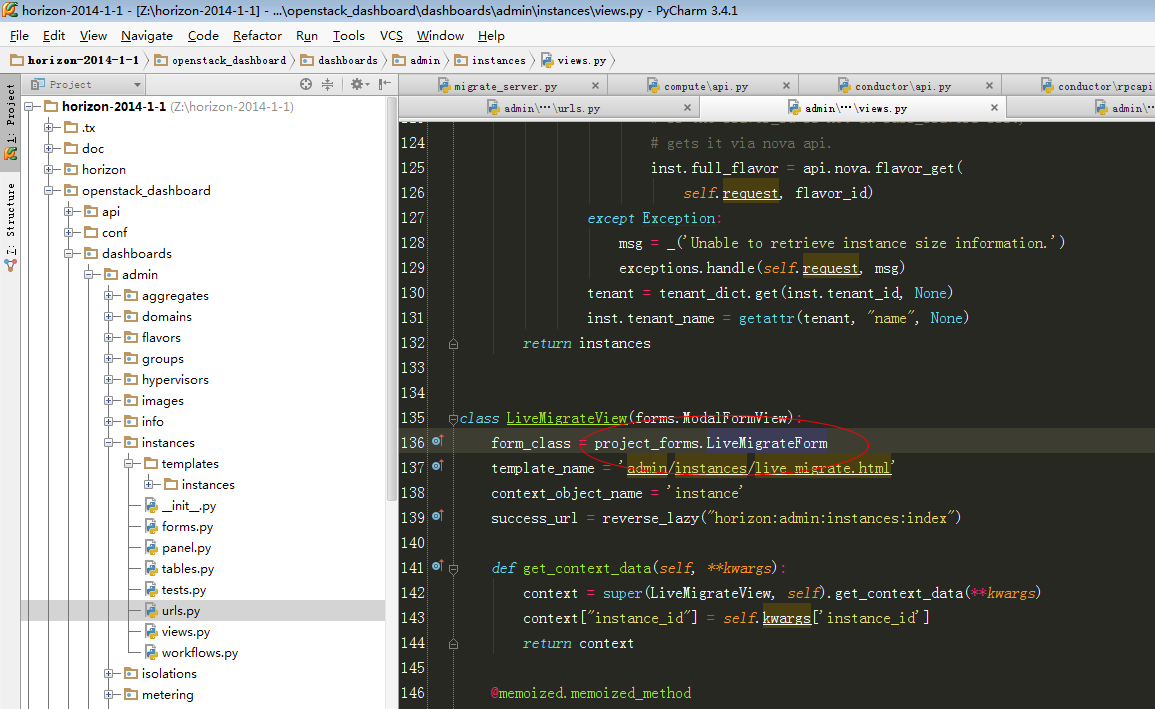
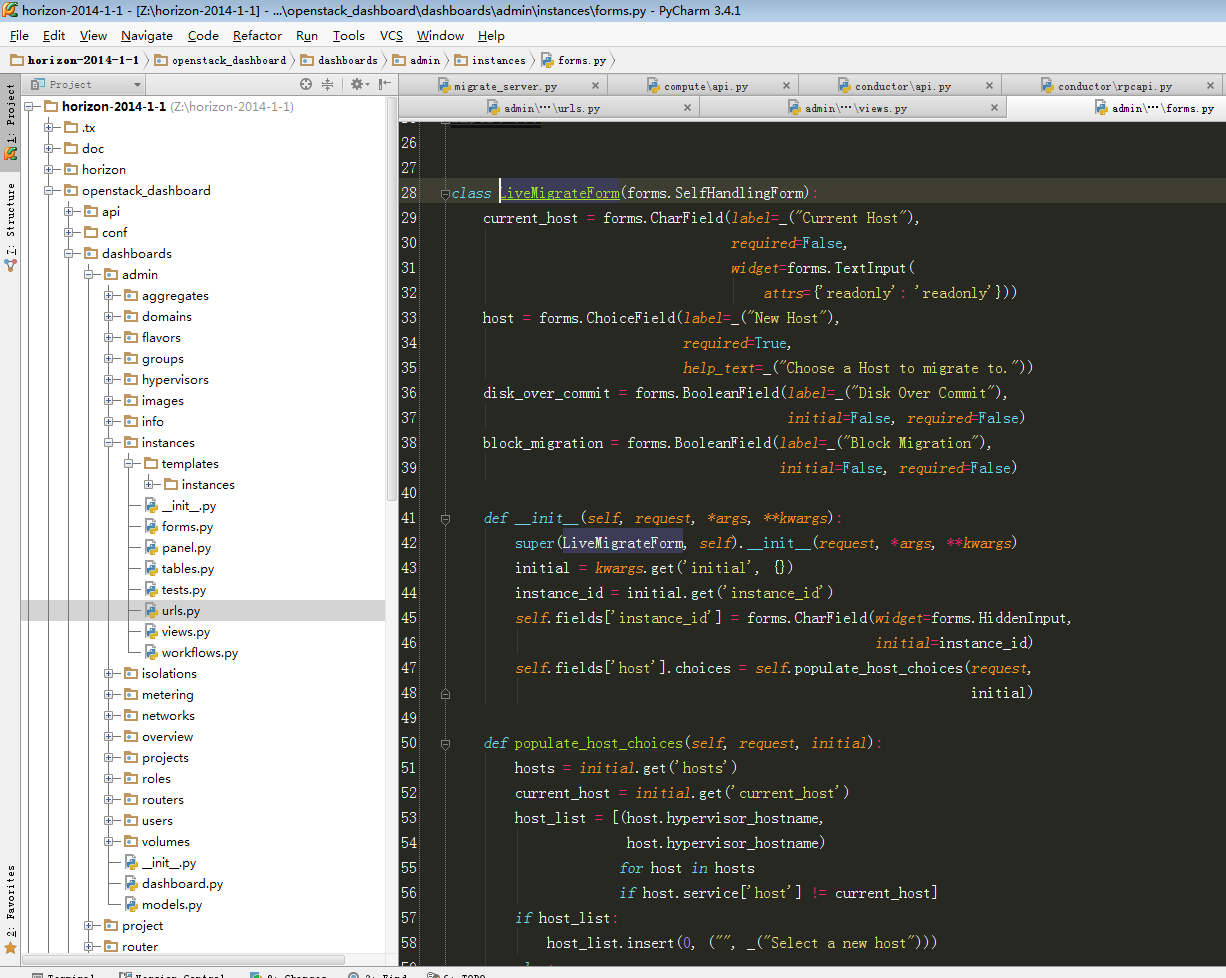
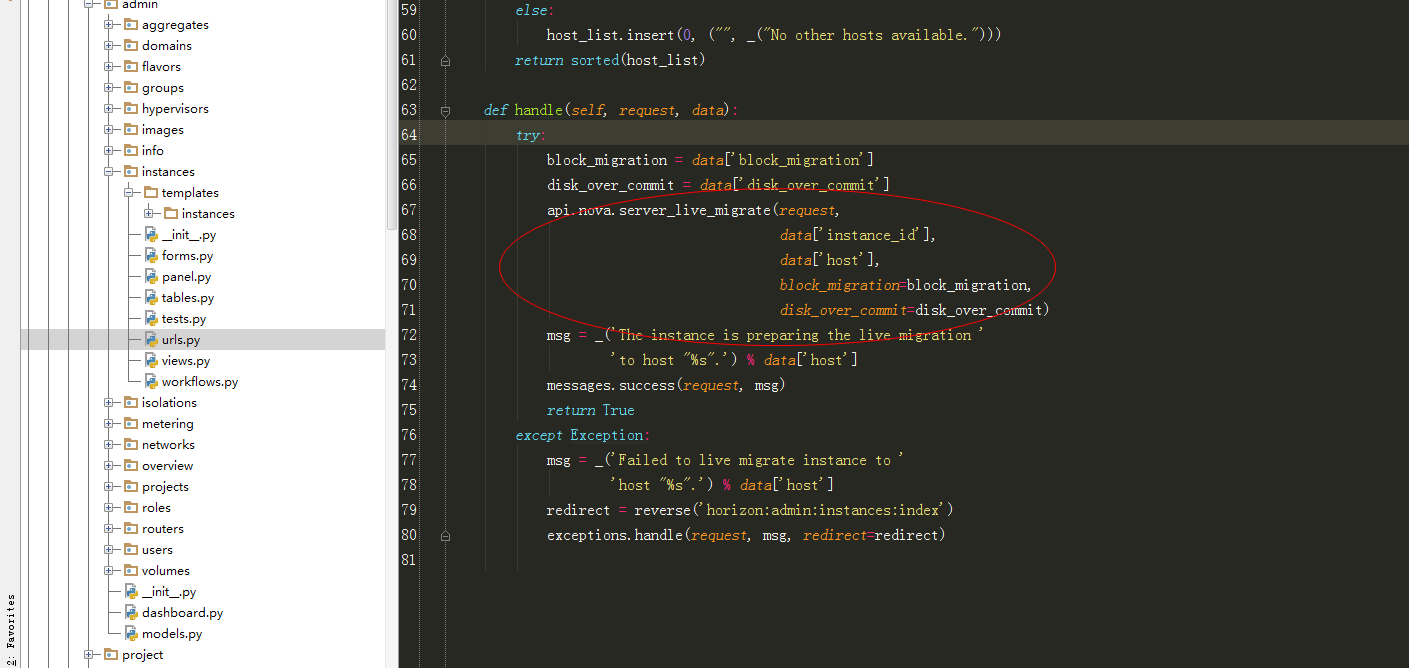

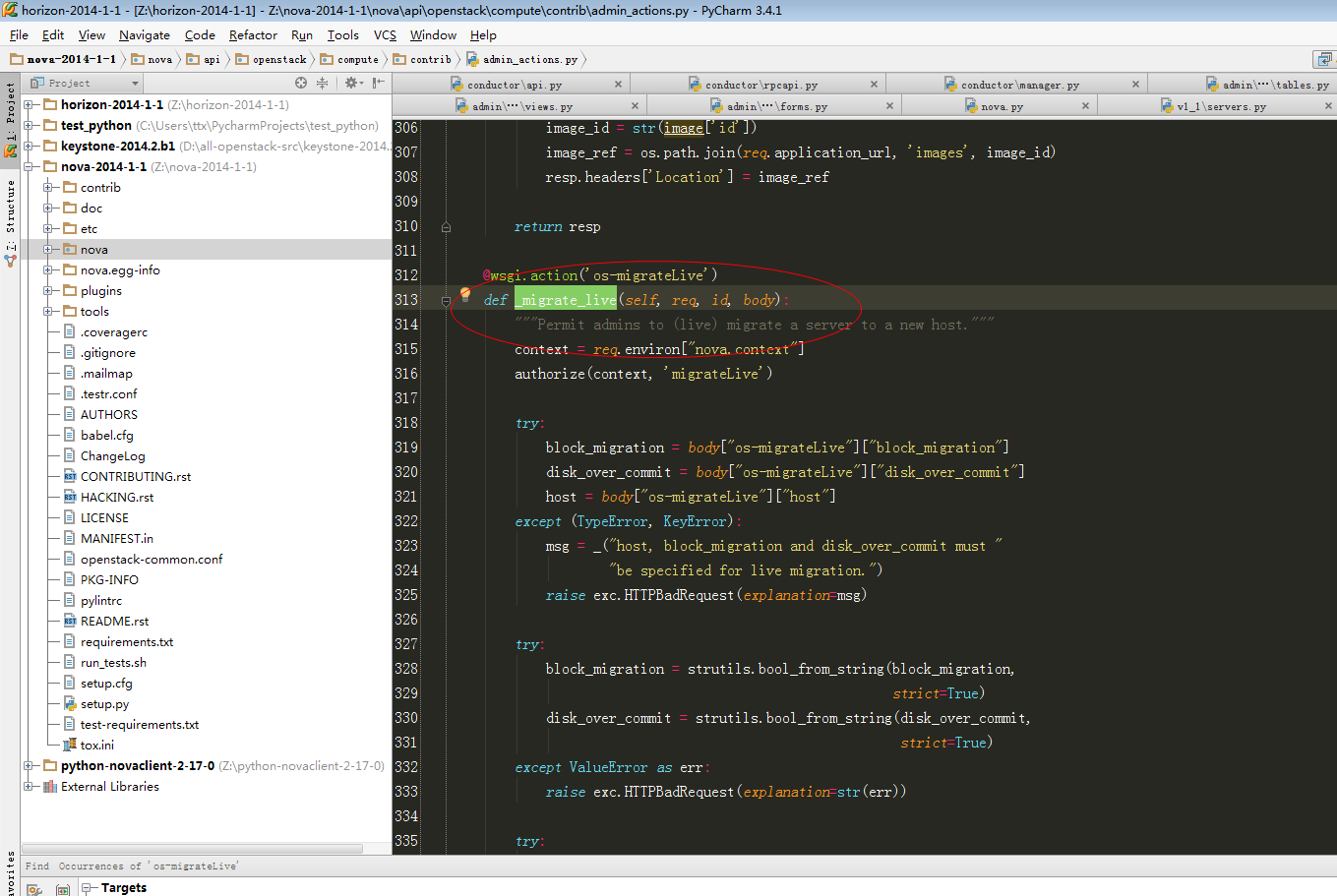

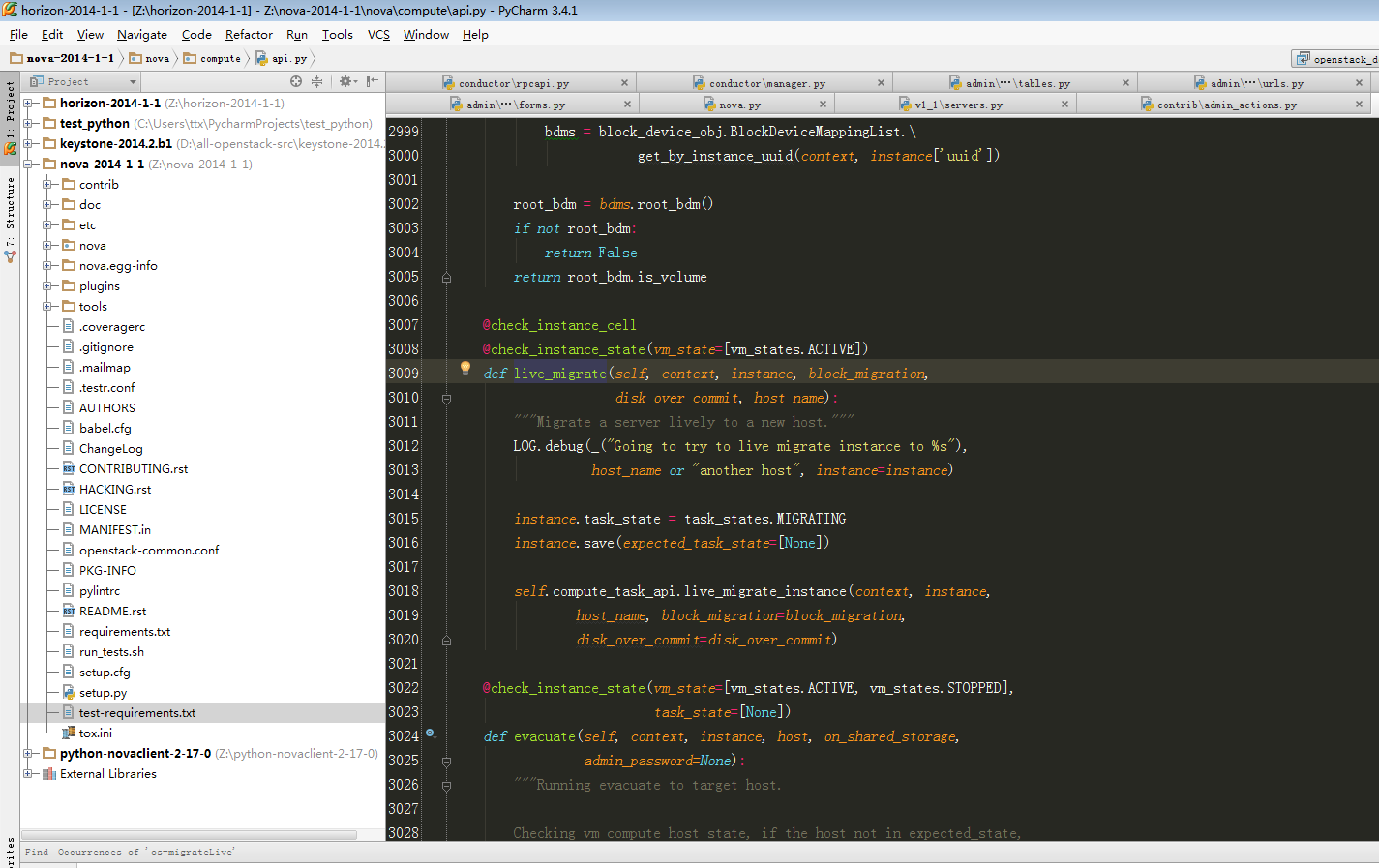

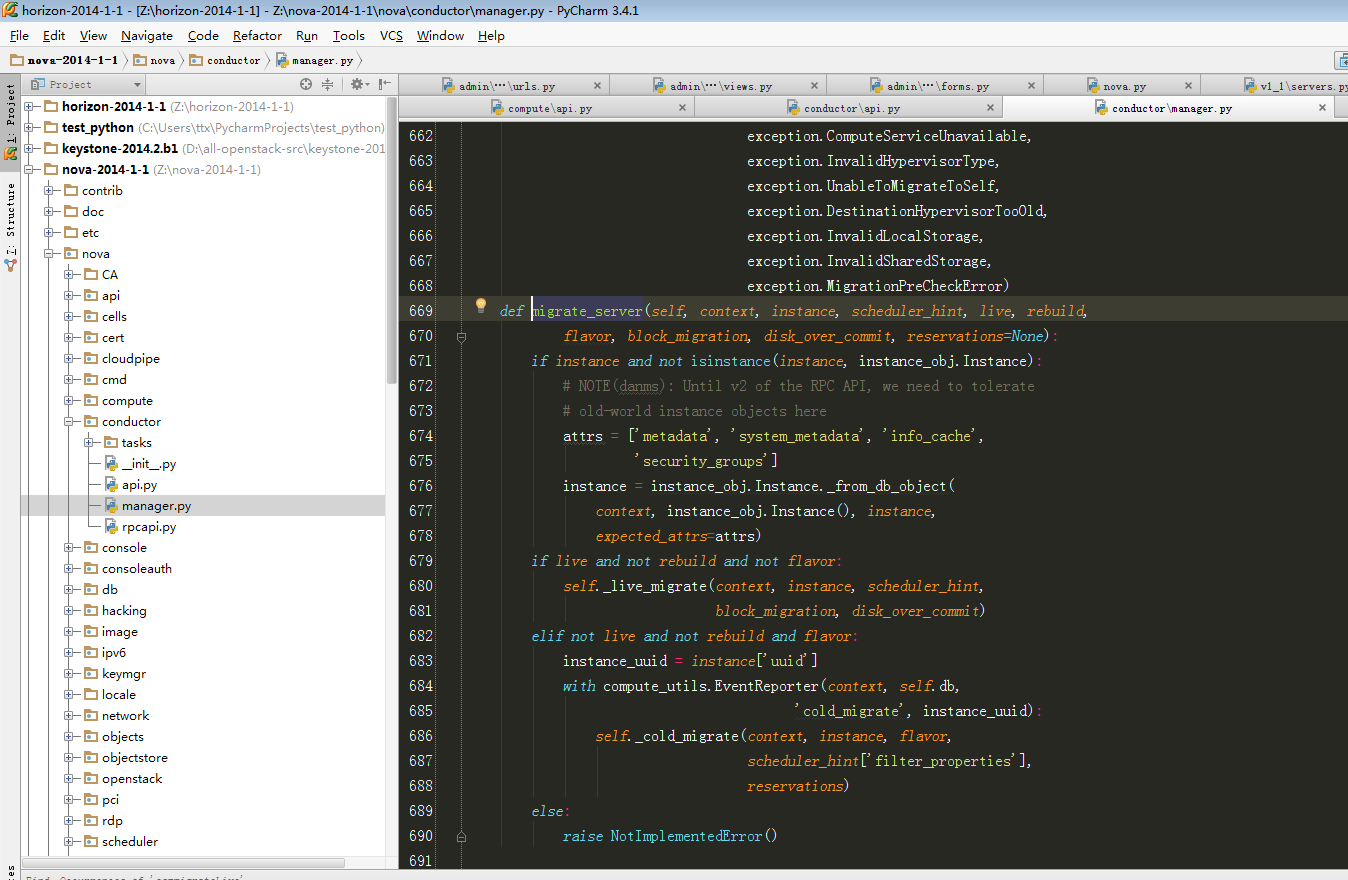
|
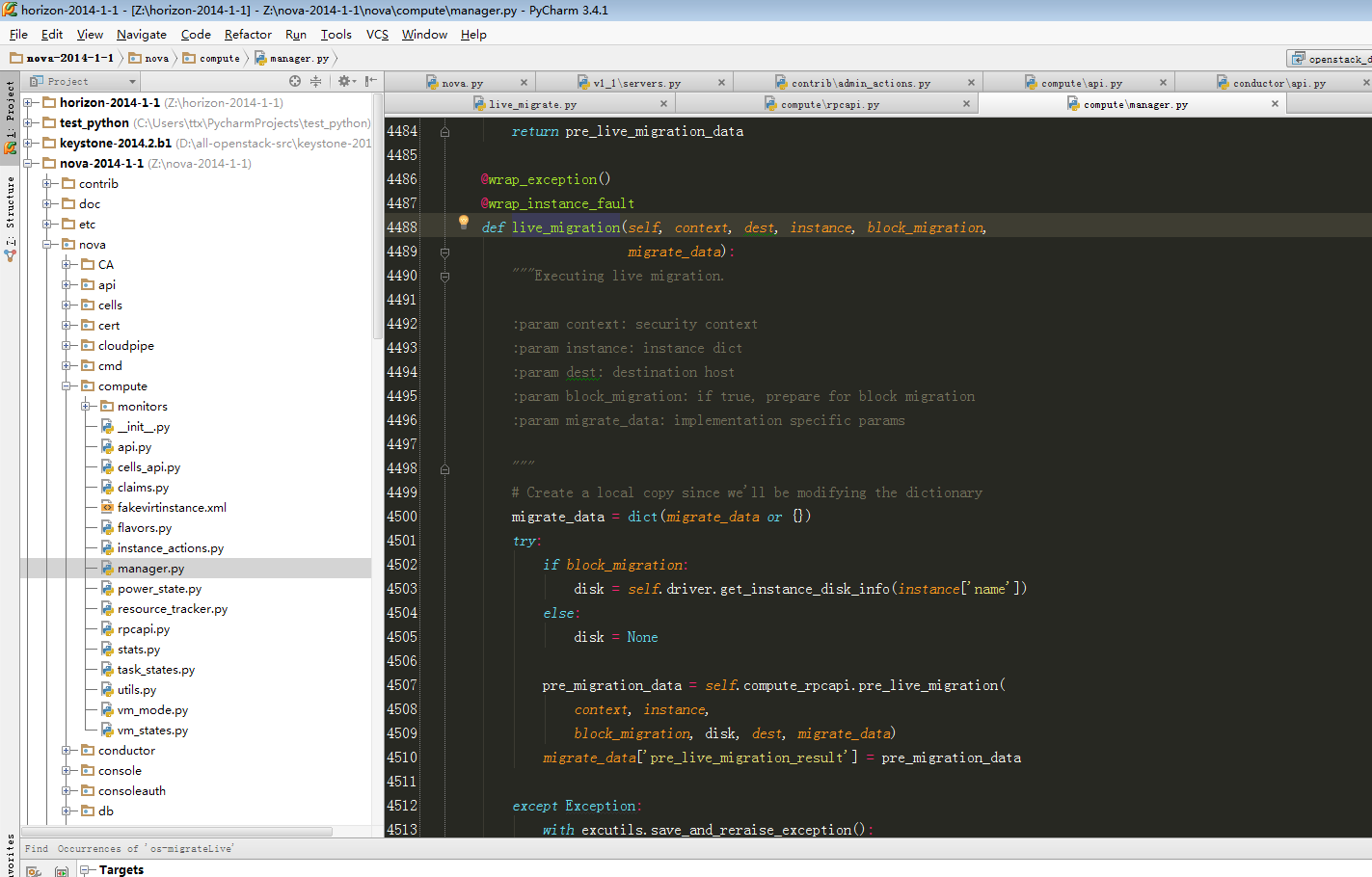
if live and not rebuild and not flavor:
self._live_migrate(context, instance, scheduler_hint,
block_migration, disk_over_commit)
elif not live and not rebuild and flavor:
instance_uuid = instance['uuid']
with compute_utils.EventReporter(context, self.db,
'cold_migrate', instance_uuid):
self._cold_migrate(context, instance, flavor,
scheduler_hint['filter_properties'],
reservations)
|

virsh使用qemu+tcp访问远程libvirtd

修改文件
vim /usr/local/libvirt/etc/sysconfig/libvirtd
用来启用tcp的端口(本环境中由于libvirt升级过,配置文件目录不一致,默认为/etc/sysconfig/libvirtd)
|
1
2
3
|
LIBVIRTD_CONFIG=/usr/local/libvirt/etc/libvirt/libvirtd.conf
LIBVIRTD_ARGS="--listen"
|
修改文件
vim /usr/local/libvirt/etc/libvirt/libvirtd.conf
|
1
2
3
4
5
6
7
8
9
|
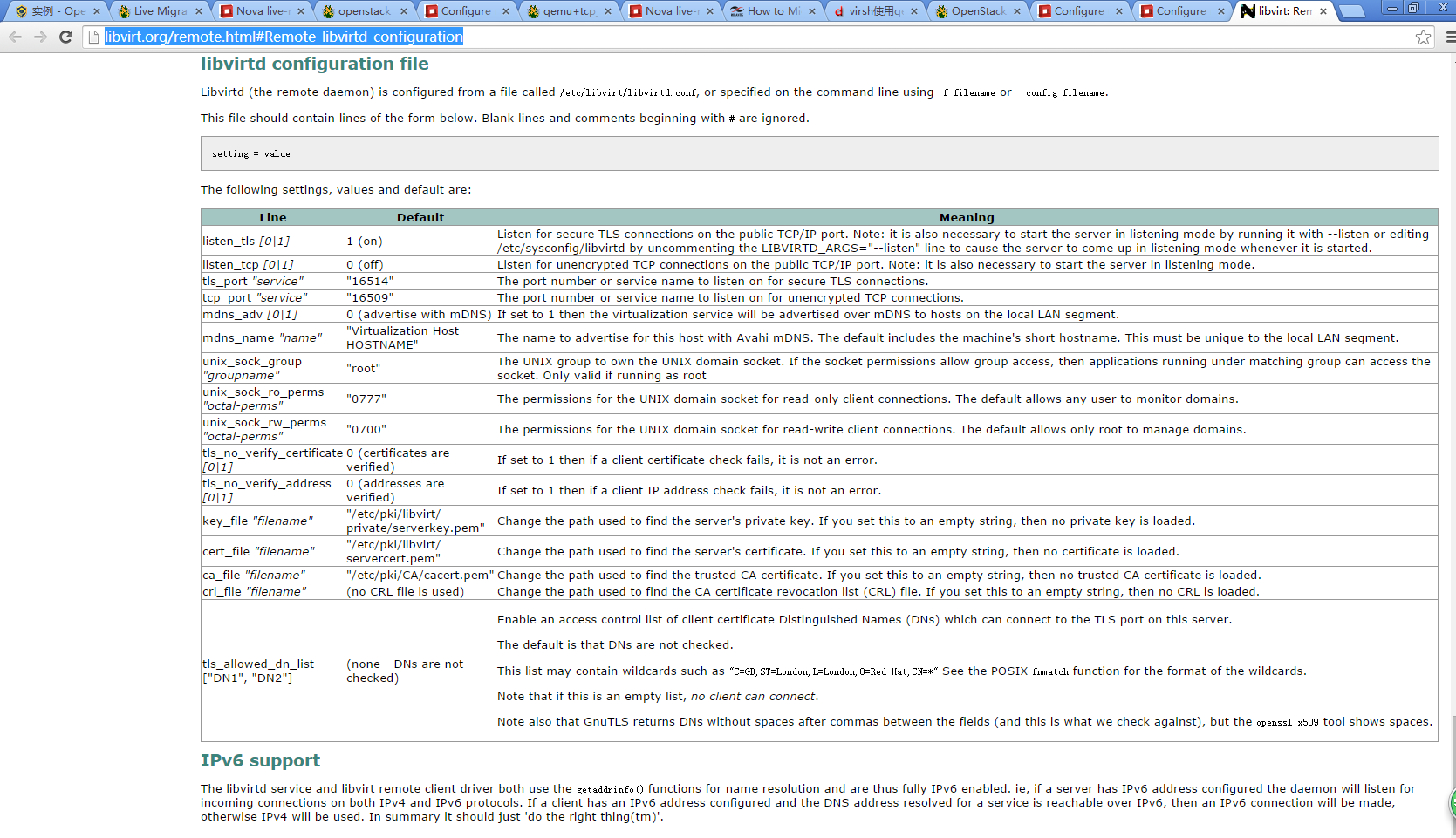
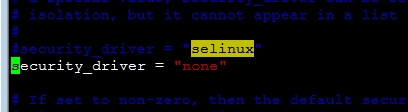
listen_tls = 0
listen_tcp = 1
tcp_port = "16509"
listen_addr = "0.0.0.0"
auth_tcp = "none"
|
运行 libvirtd
|
1
|
service libvirtd restart
|
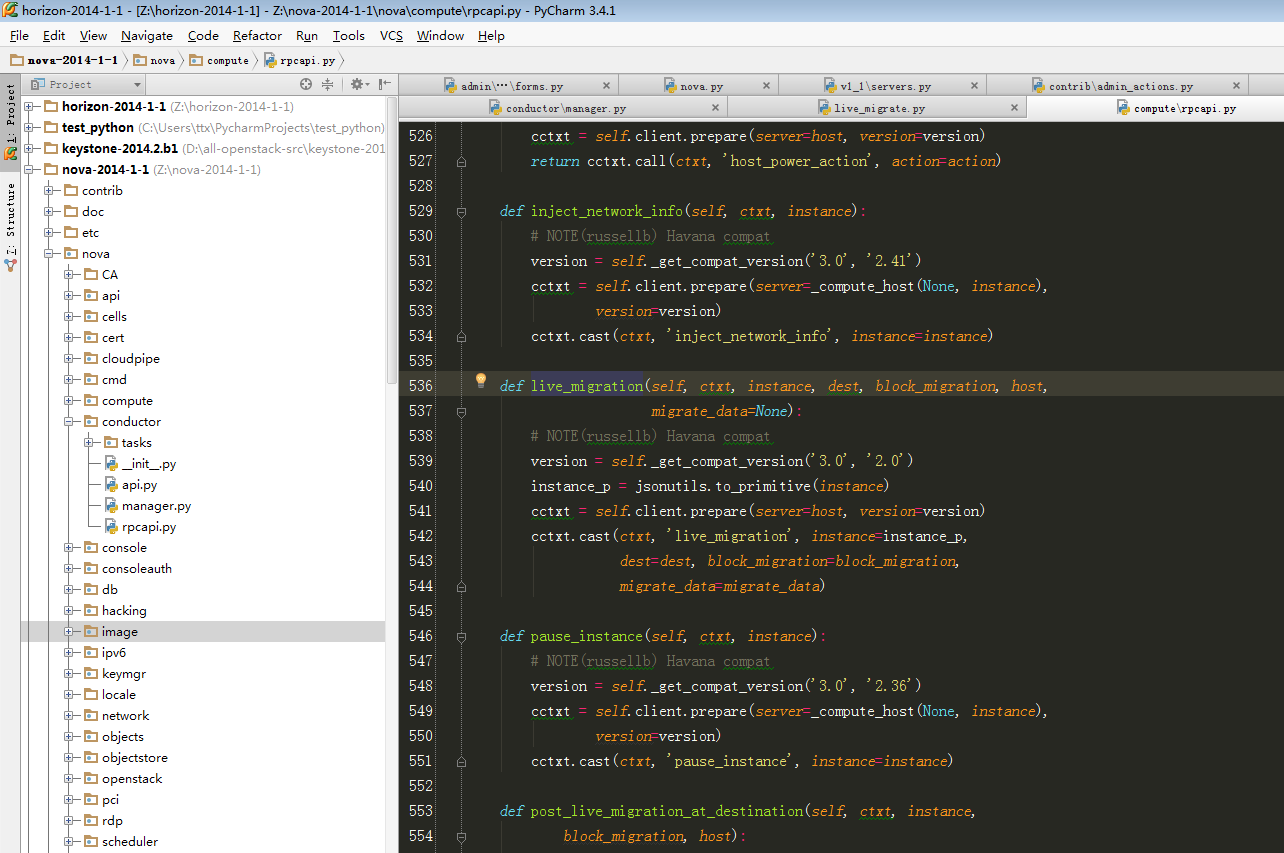
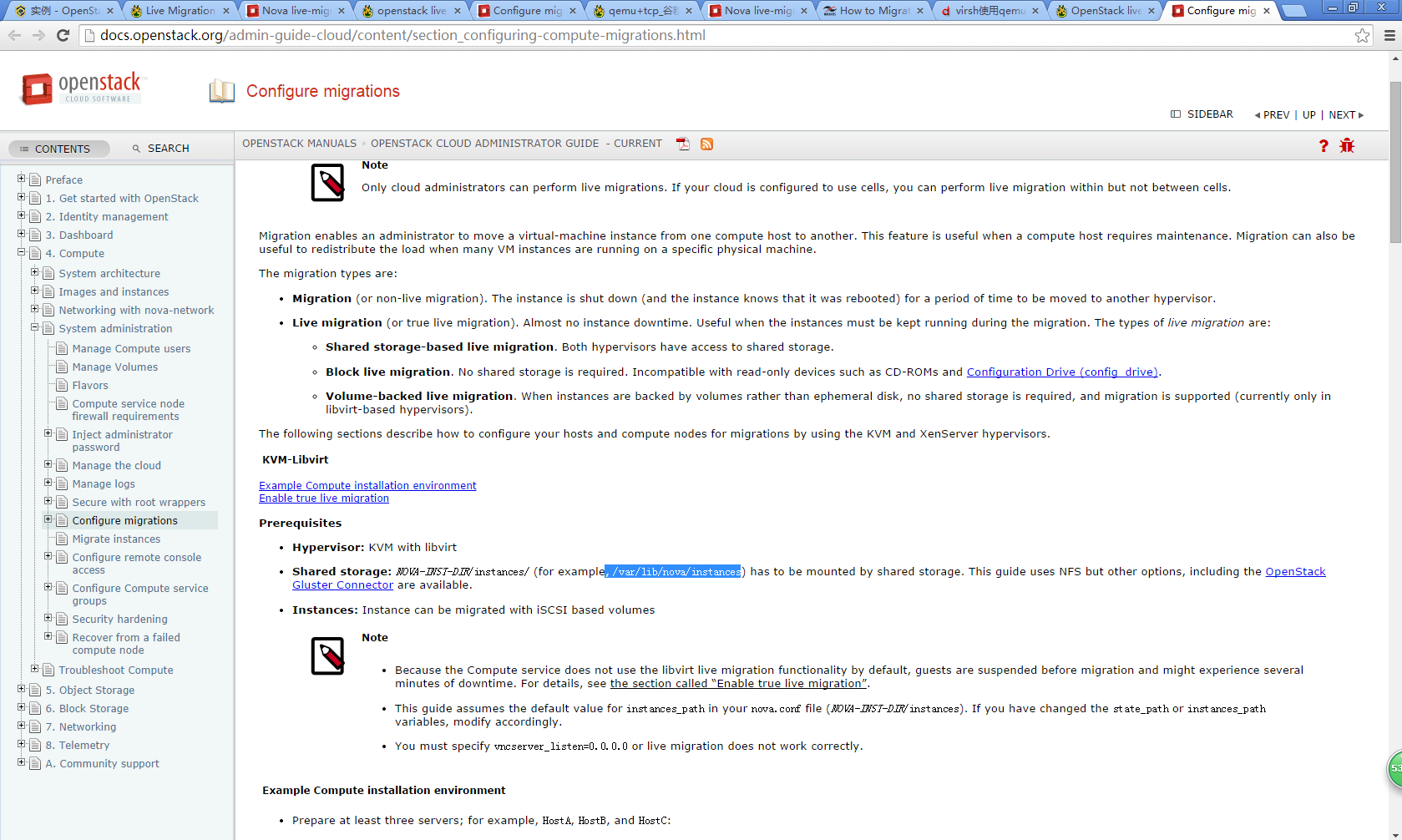
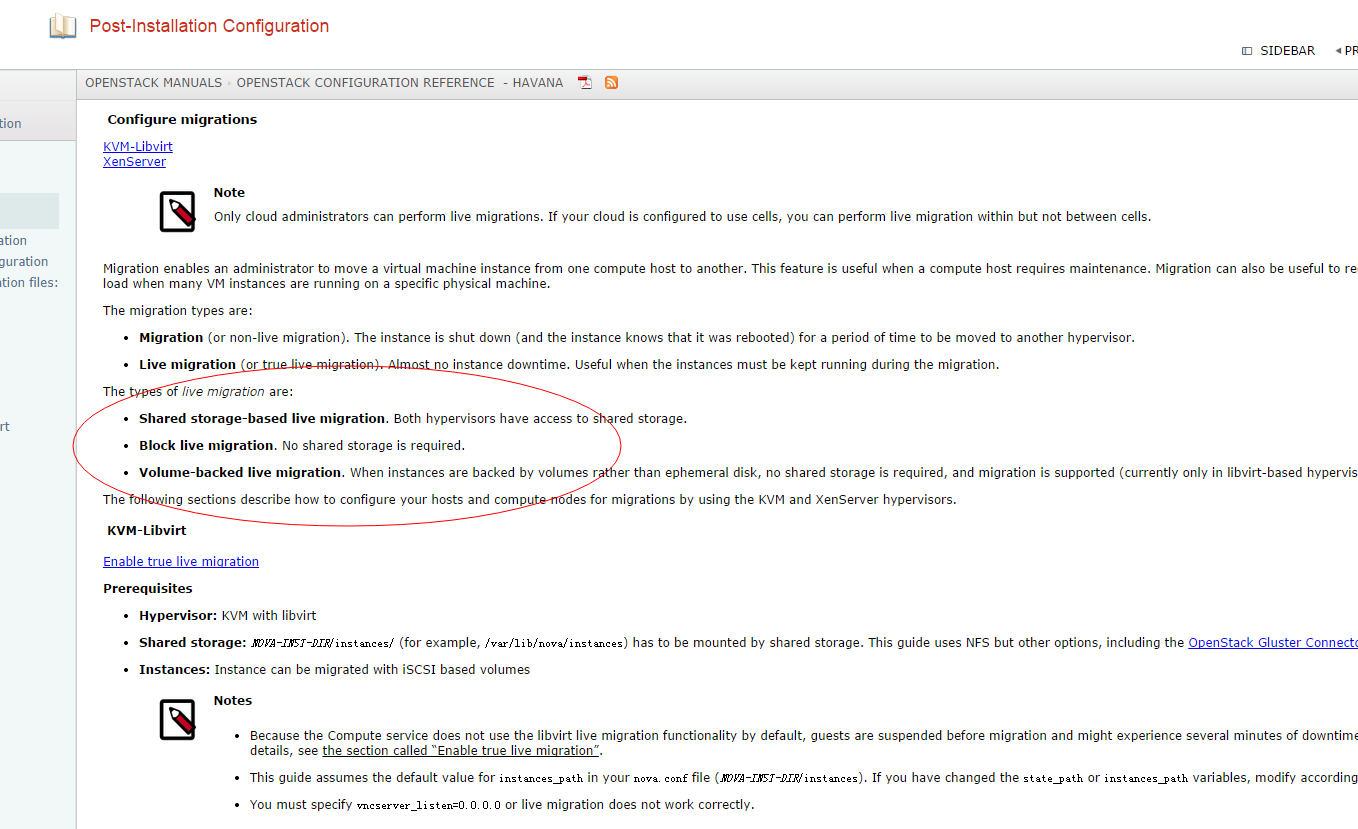
| Configuration option = Default value | Description |
|---|---|
| [DEFAULT] | |
| live_migration_retry_count = 30 | (IntOpt) Number of 1 second retries needed in live_migration |
| [libvirt] | |
| live_migration_bandwidth = 0 | (IntOpt) Maximum bandwidth to be used during migration, in Mbps |
| live_migration_flag = VIR_MIGRATE_UNDEFINE_SOURCE, VIR_MIGRATE_PEER2PEER, VIR_MIGRATE_LIVE, VIR_MIGRATE_TUNNELLED | (StrOpt) Migration flags to be set for live migration |
| live_migration_uri = qemu+tcp://%s/system | (StrOpt) Migration target URI (any included "%s" is replaced with the migration target hostname) |




|
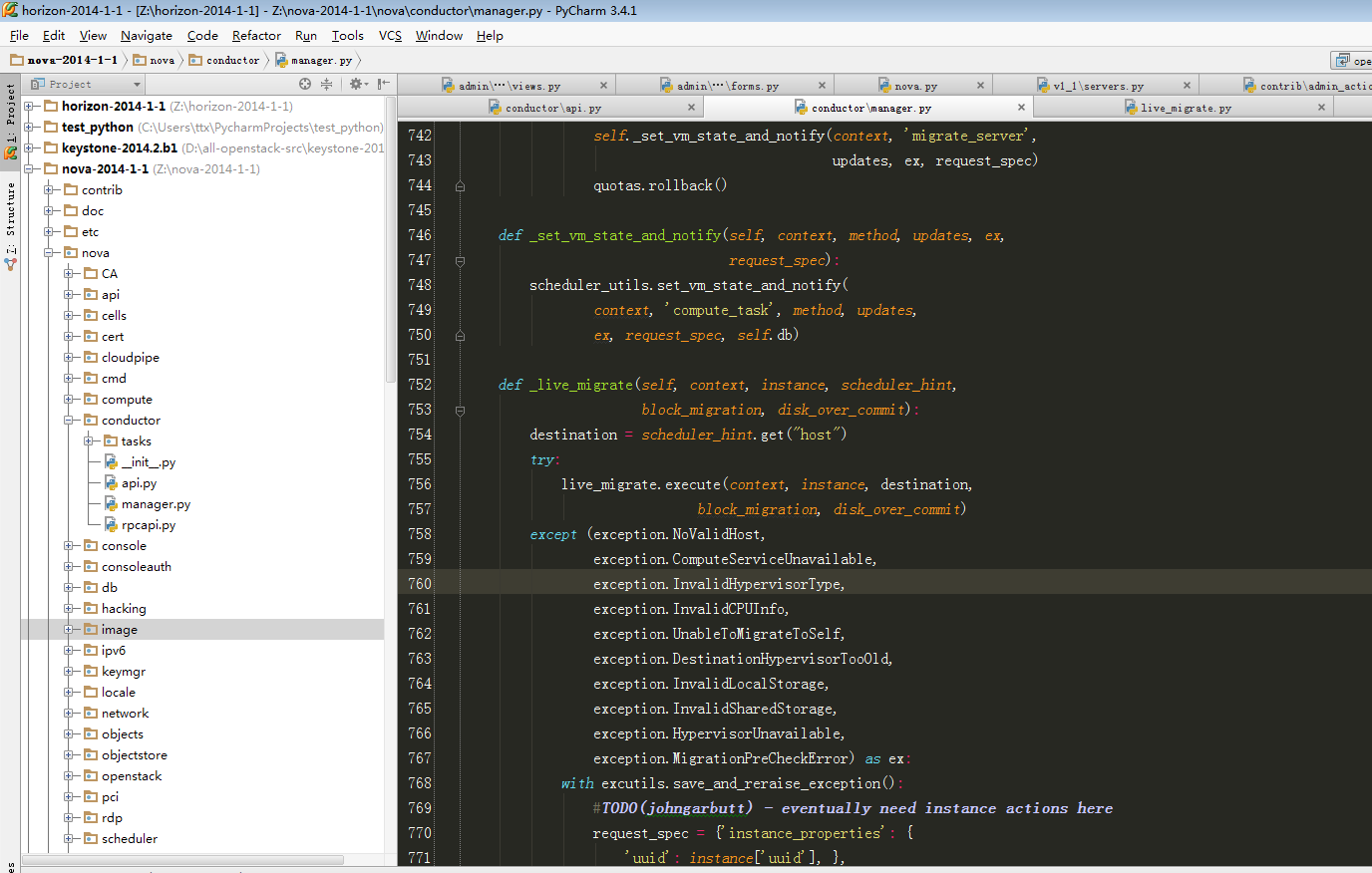
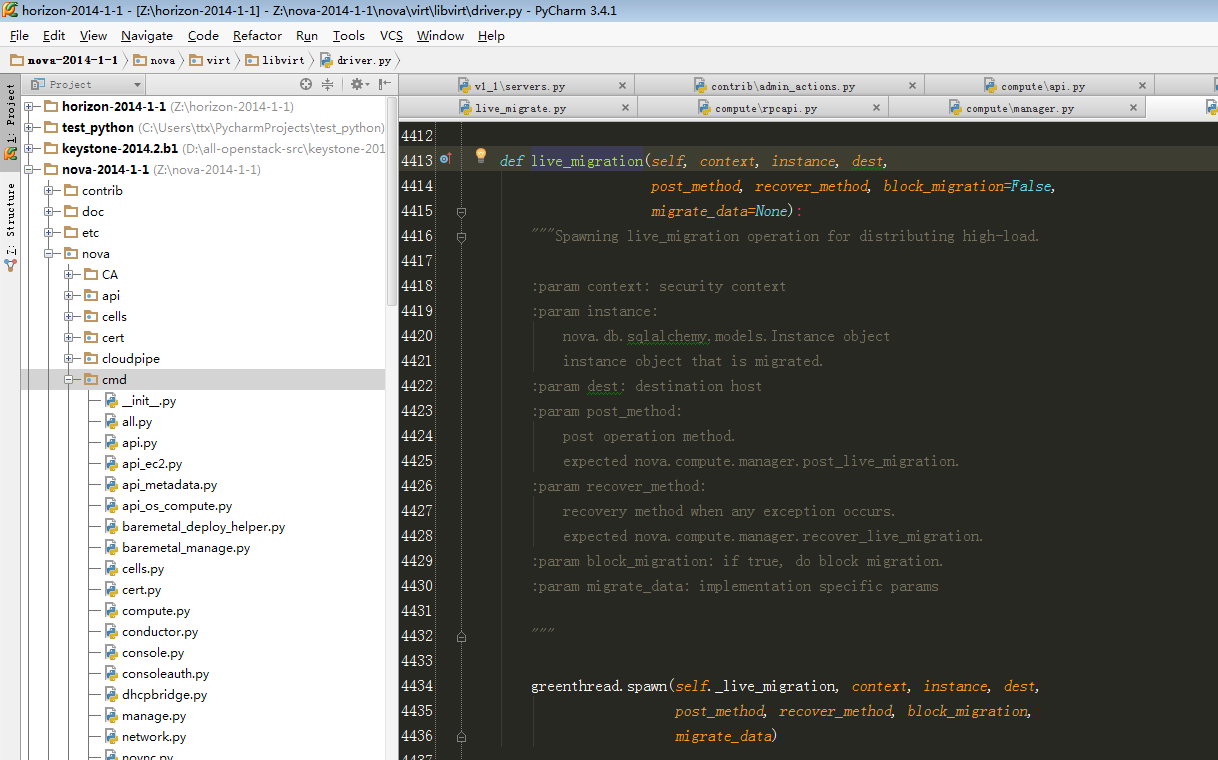
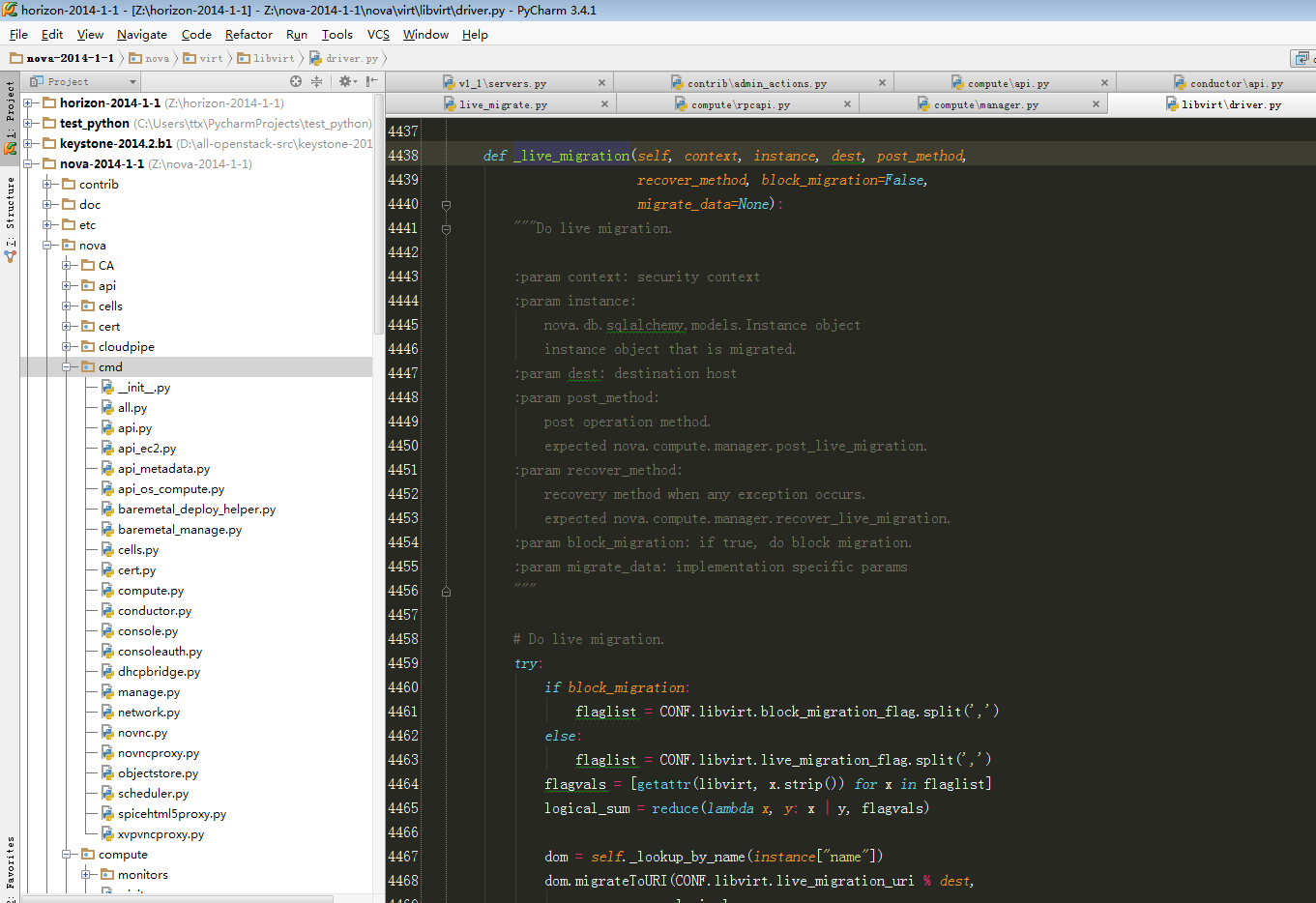
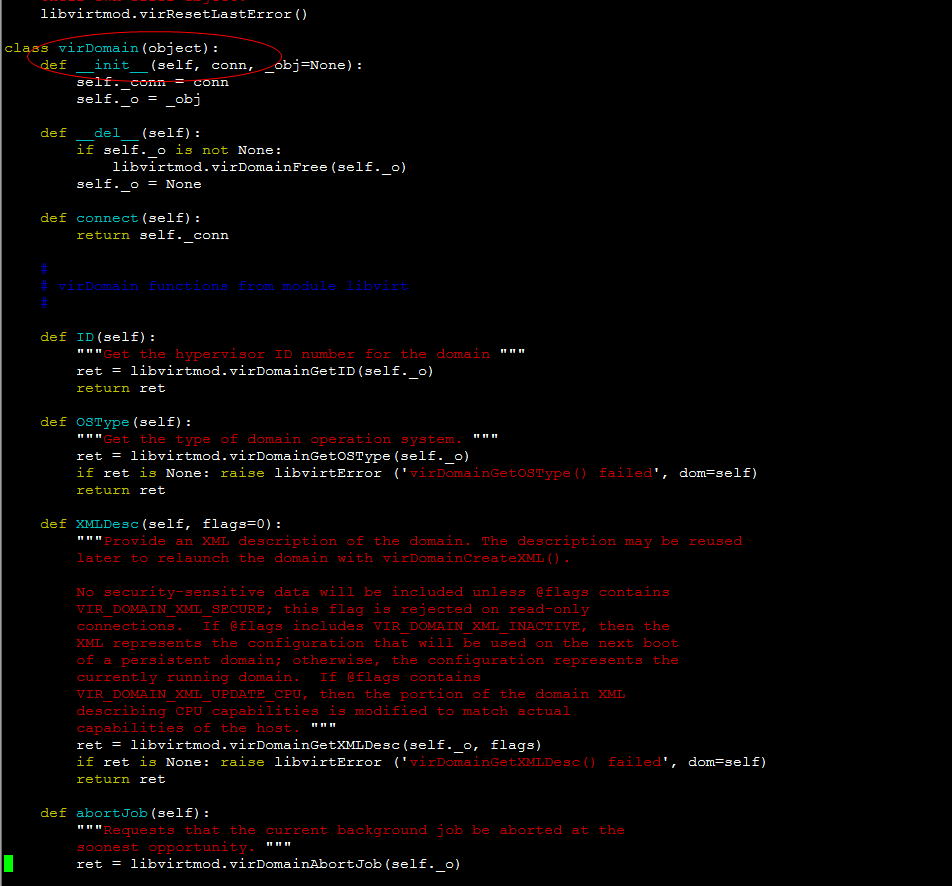
def _live_migration(self, context, instance, dest, post_method,
recover_method, block_migration=False,
migrate_data=None):
"""Do live migration.
:param context: security context
:param instance:
nova.db.sqlalchemy.models.Instance object
instance object that is migrated.
:param dest: destination host
:param post_method:
post operation method.
expected nova.compute.manager.post_live_migration.
:param recover_method:
recovery method when any exception occurs.
expected nova.compute.manager.recover_live_migration.
:param block_migration: if true, do block migration.
:param migrate_data: implementation specific params
"""
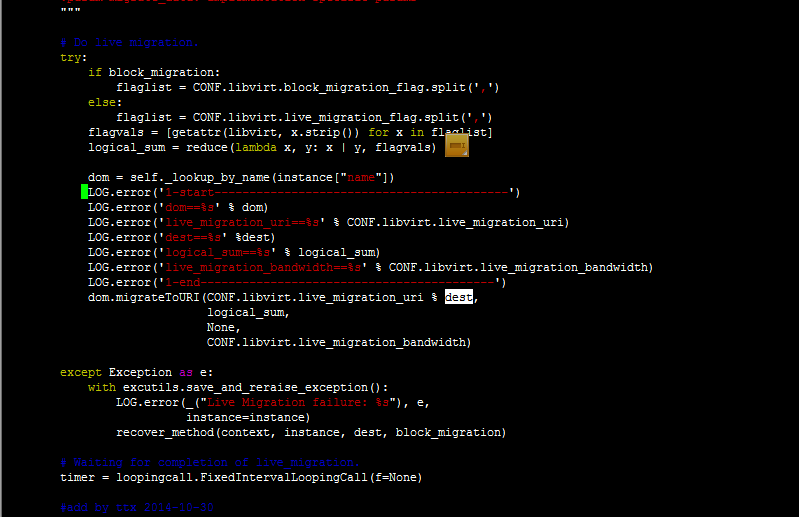
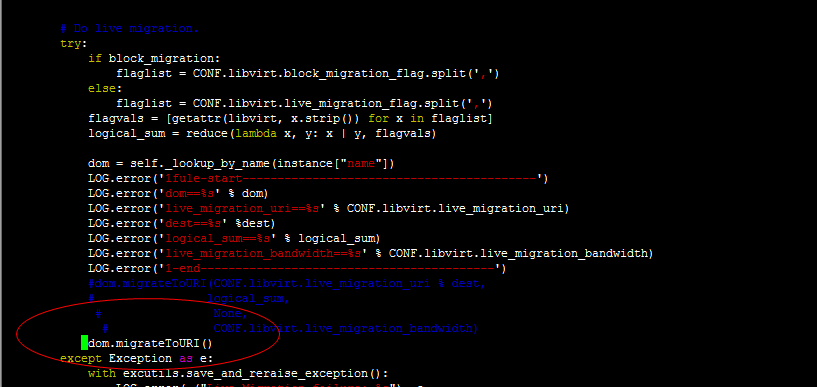
# Do live migration.
try:
if block_migration:
flaglist = CONF.libvirt.block_migration_flag.split(',')
else:
flaglist = CONF.libvirt.live_migration_flag.split(',')
flagvals = [getattr(libvirt, x.strip()) for x in flaglist]
logical_sum = reduce(lambda x, y: x | y, flagvals)
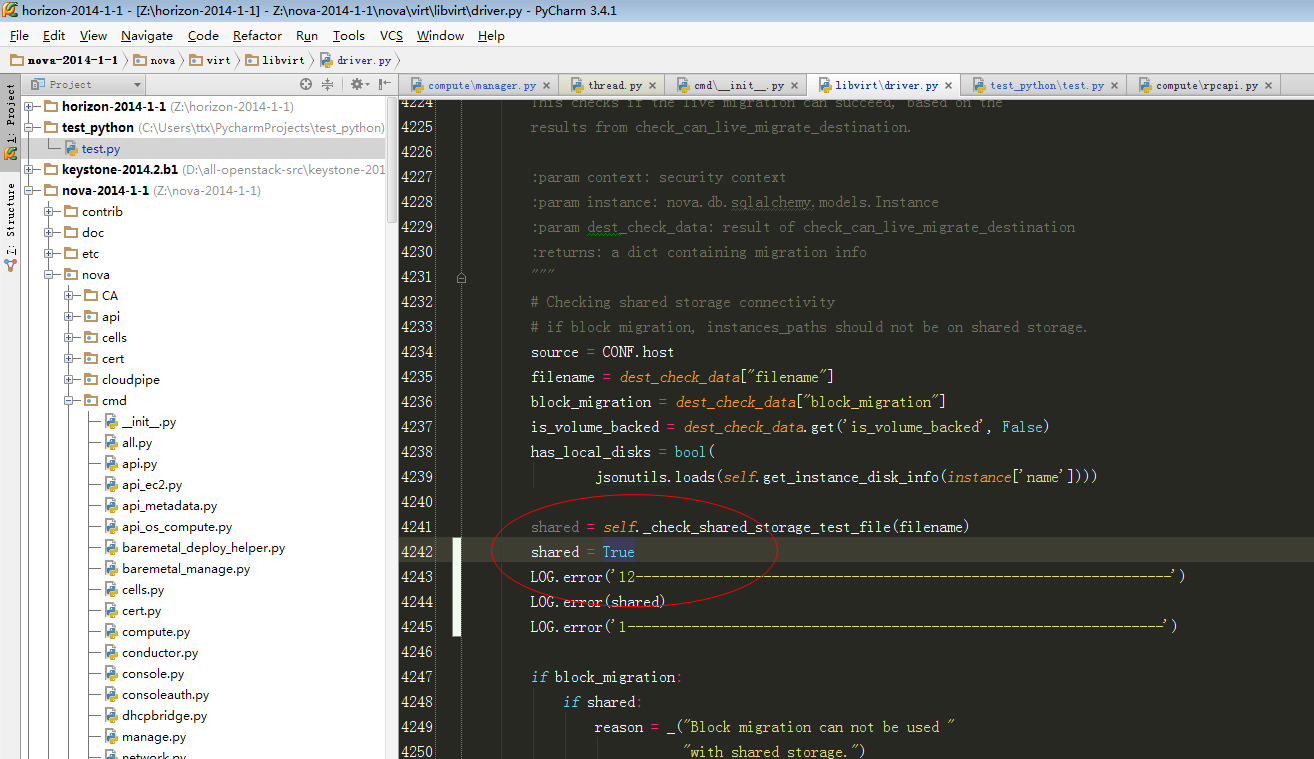
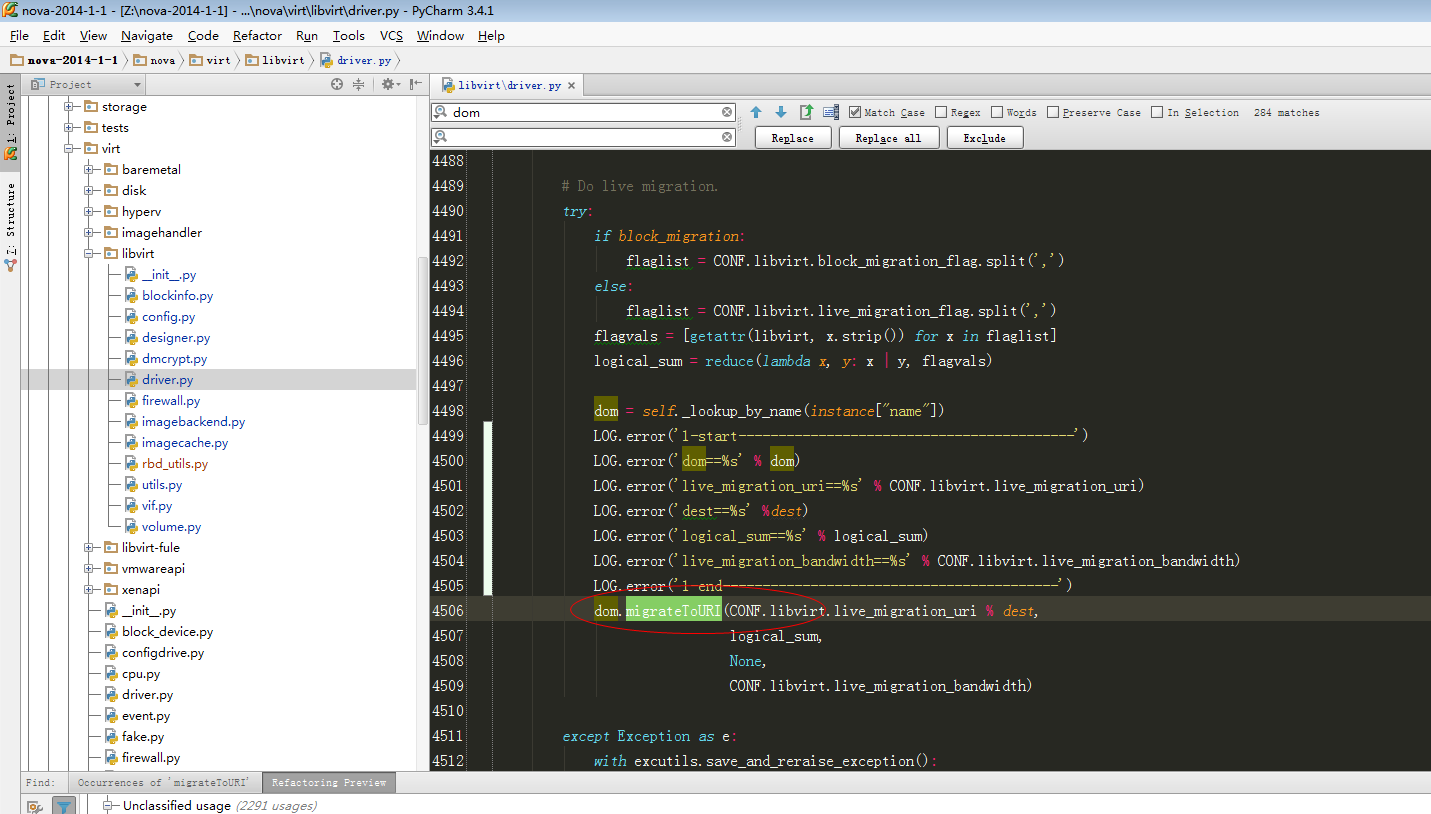
dom = self._lookup_by_name(instance["name"])
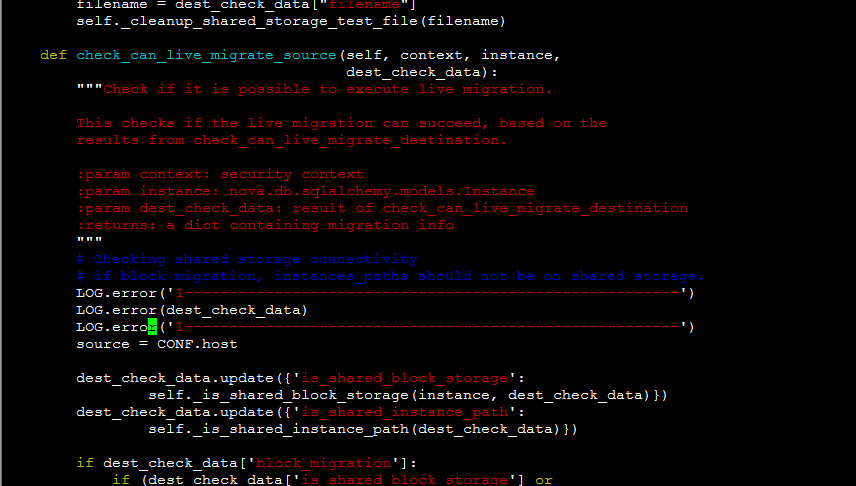
LOG.error('1-start------------------------------------------')
LOG.error('dom==%s' % dom)
LOG.error('live_migration_uri==%s' % CONF.libvirt.live_migration_uri)
LOG.error('dest==%s' %dest)
LOG.error('logical_sum==%s' % logical_sum)
LOG.error('live_migration_bandwidth==%s' % CONF.libvirt.live_migration_bandwidth)
LOG.error('1-end------------------------------------------')
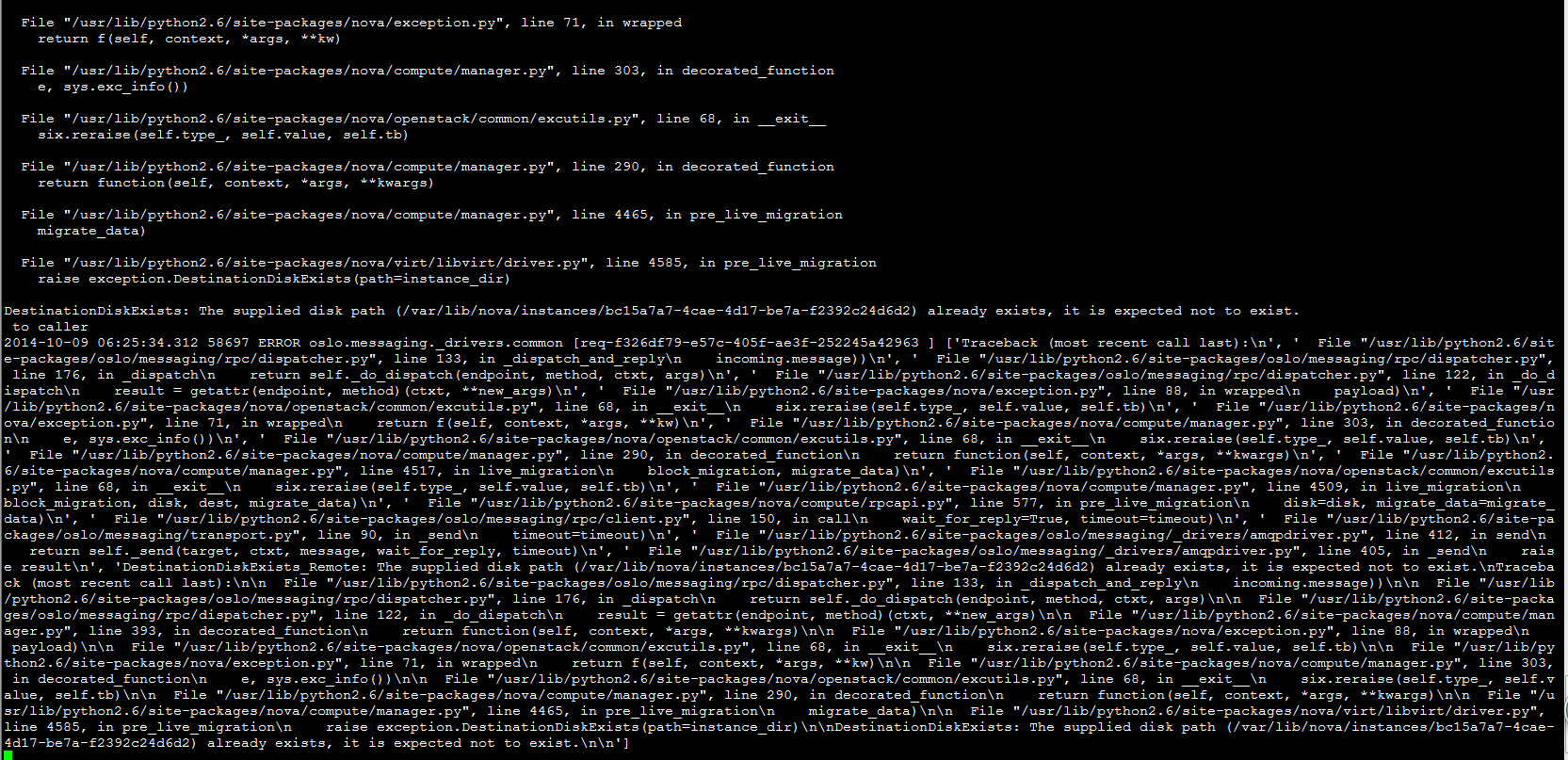
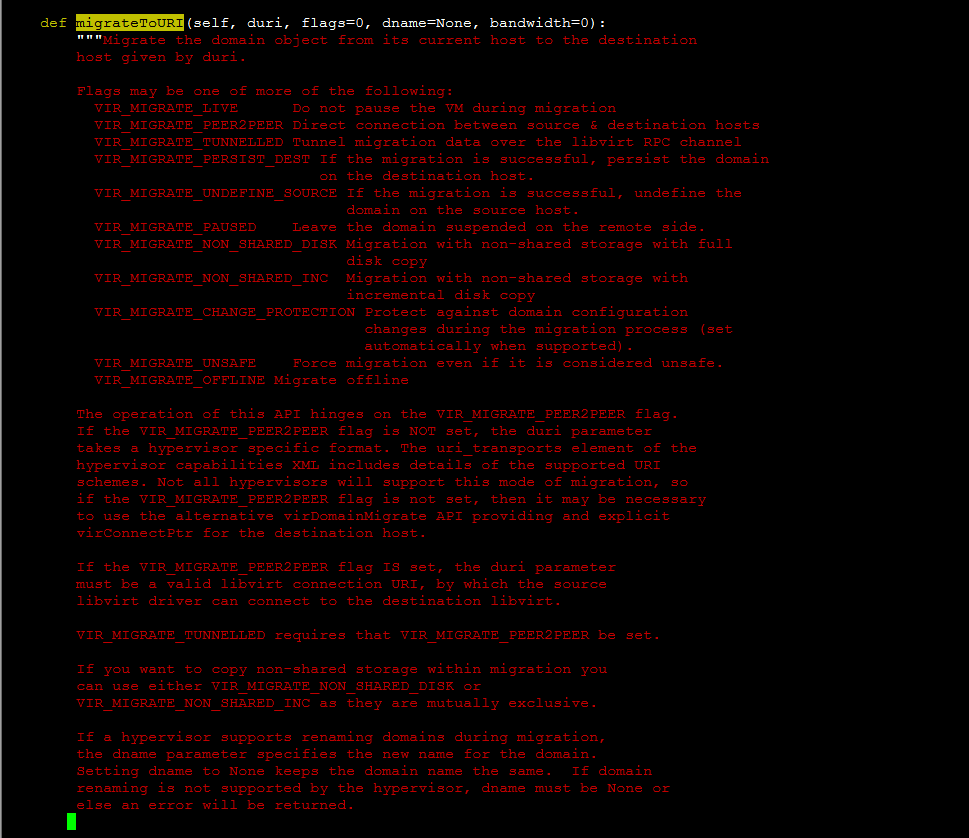
dom.migrateToURI(CONF.libvirt.live_migration_uri % dest,
logical_sum,
None,
CONF.libvirt.live_migration_bandwidth)
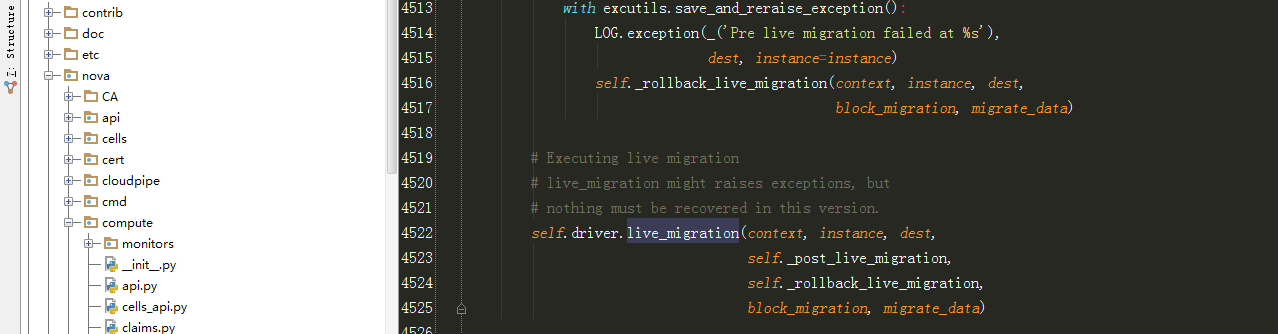
except Exception as e:
with excutils.save_and_reraise_exception():
LOG.error(_("Live Migration failure: %s"), e,
instance=instance)
recover_method(context, instance, dest, block_migration)
|






LIBVIRT_DEBUG=1 virsh list --all
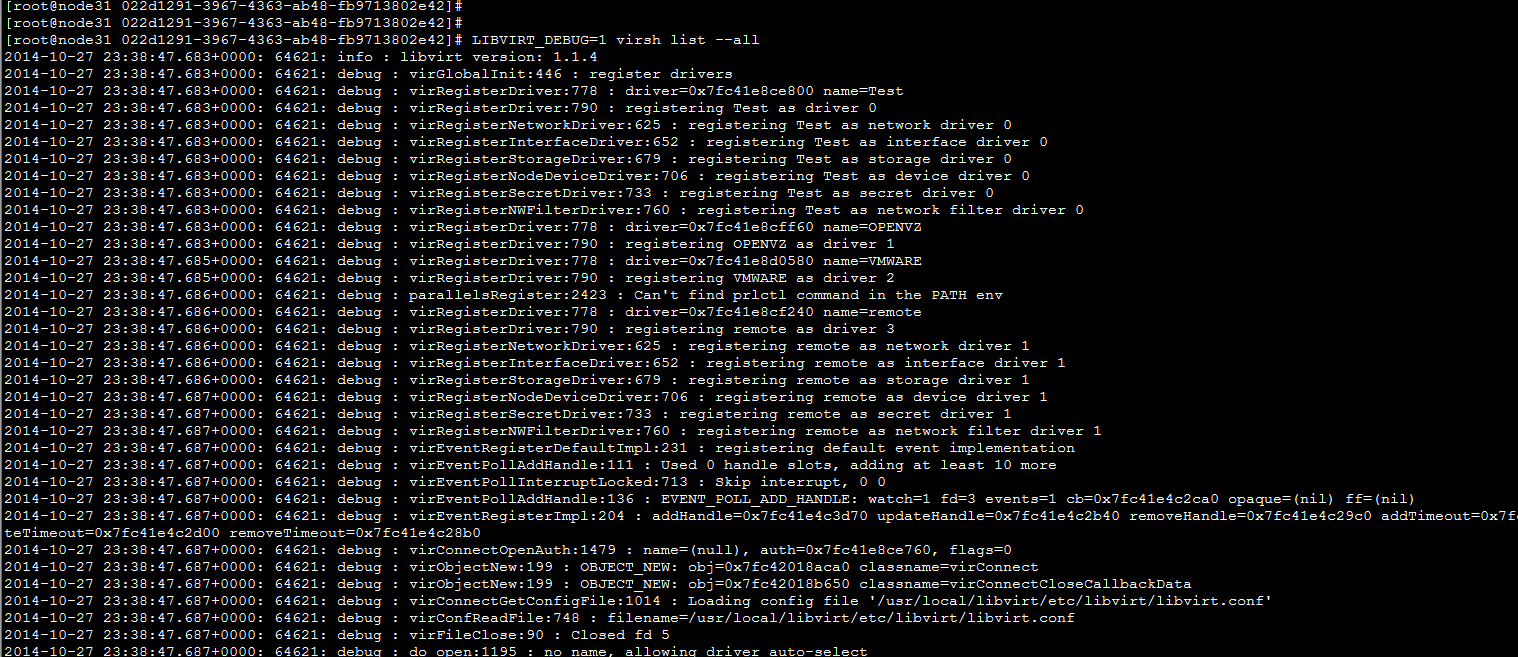
|
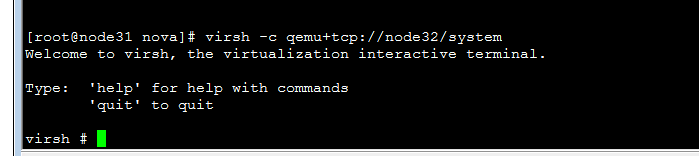
virsh -c qemu+tcp://node32/system
|




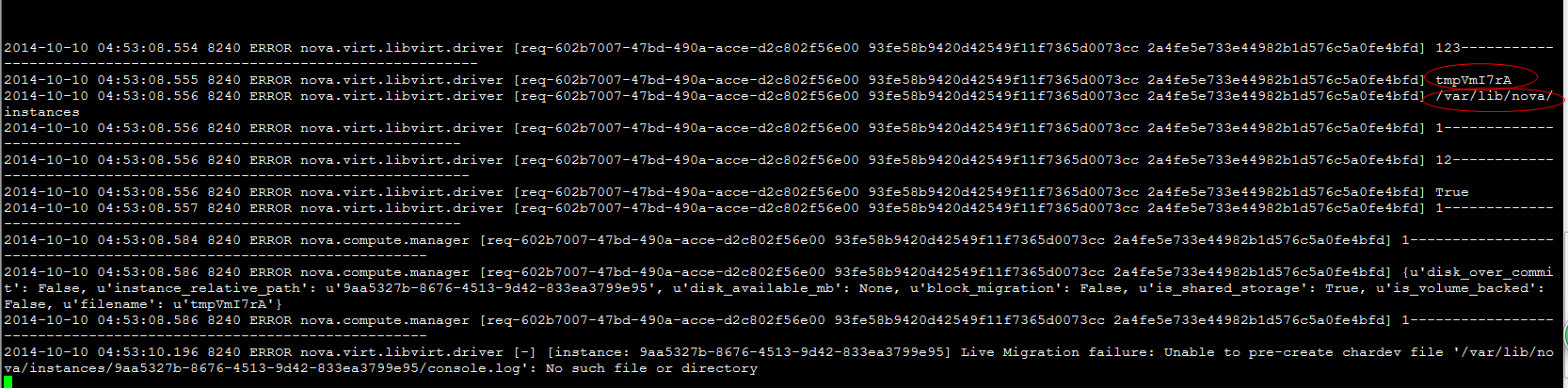
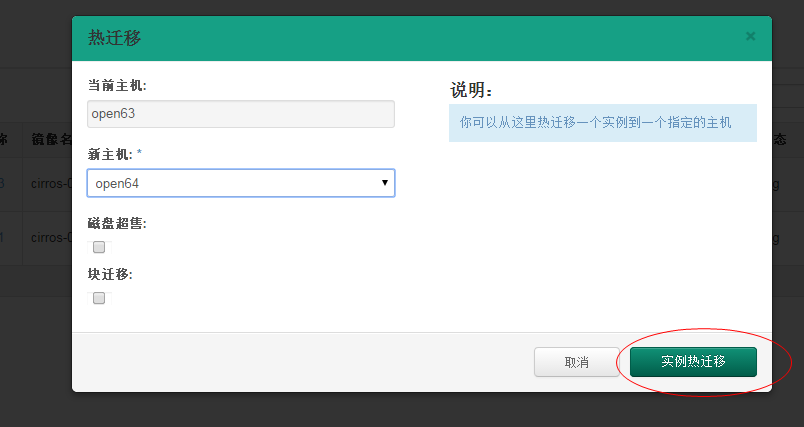
virsh migrate --live --verbose --direct --p2p 5 qemu+tcp://node32/system


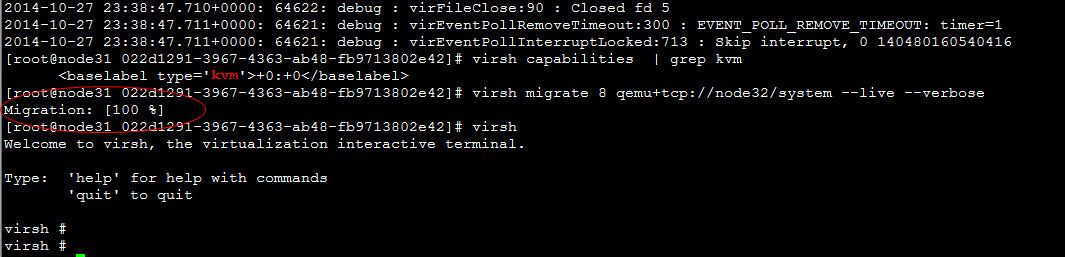


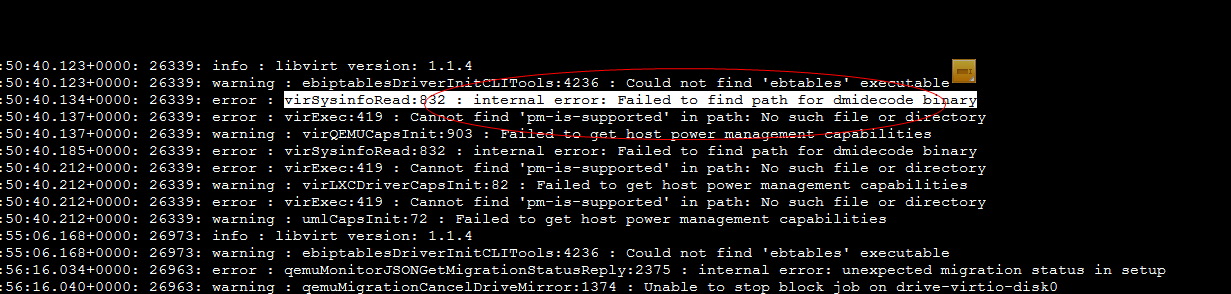
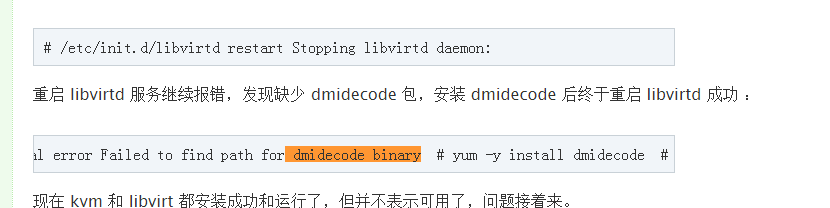
error: Cannot get interface MTU on 'qbrbc05fd4a-43': No such device
error: Timed out during operation: cannot acquire state change lock

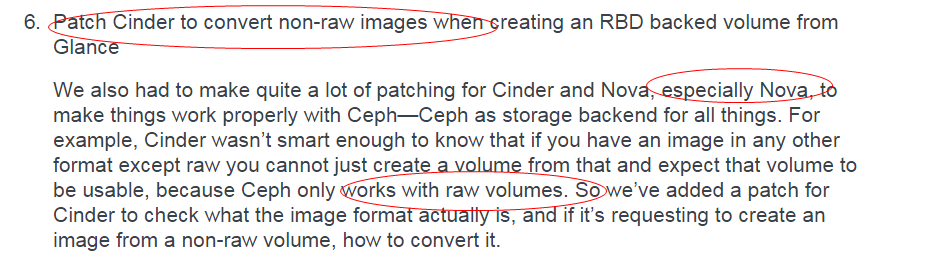


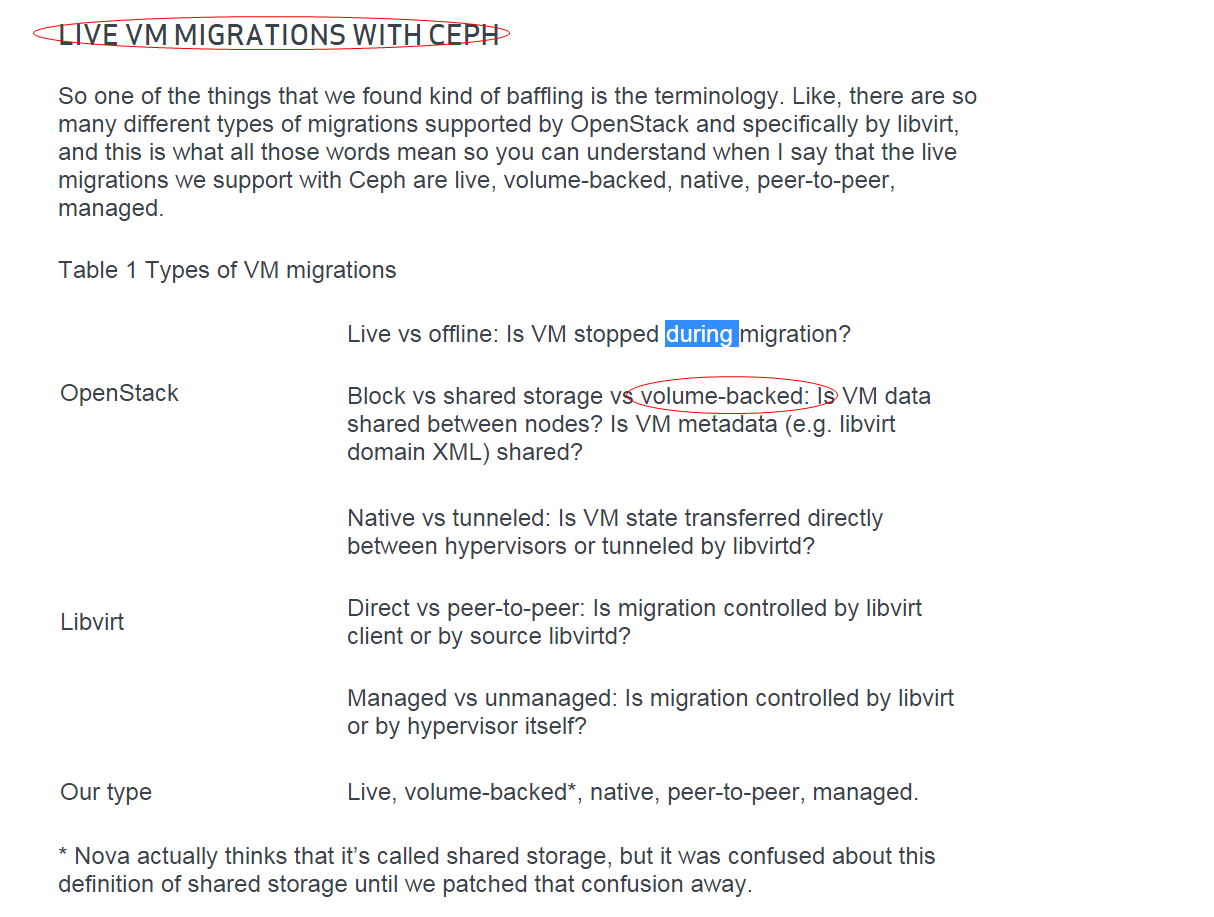

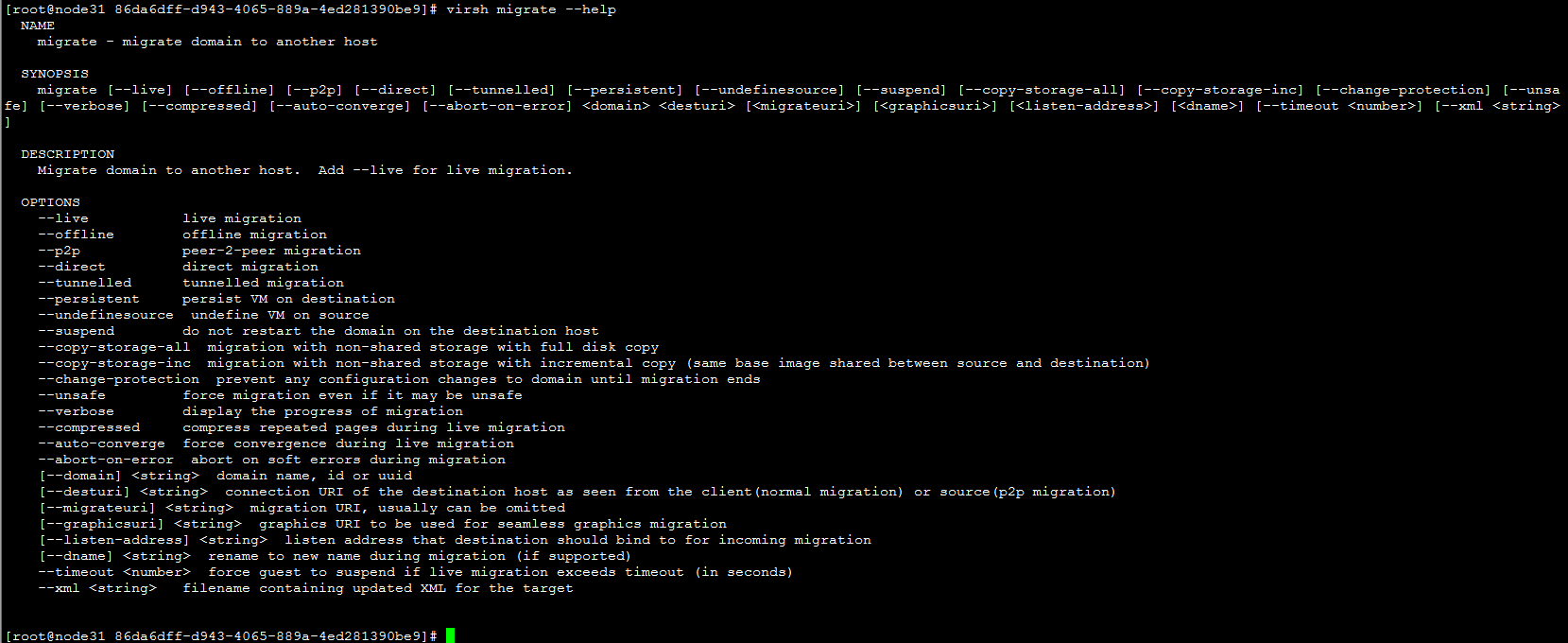













|
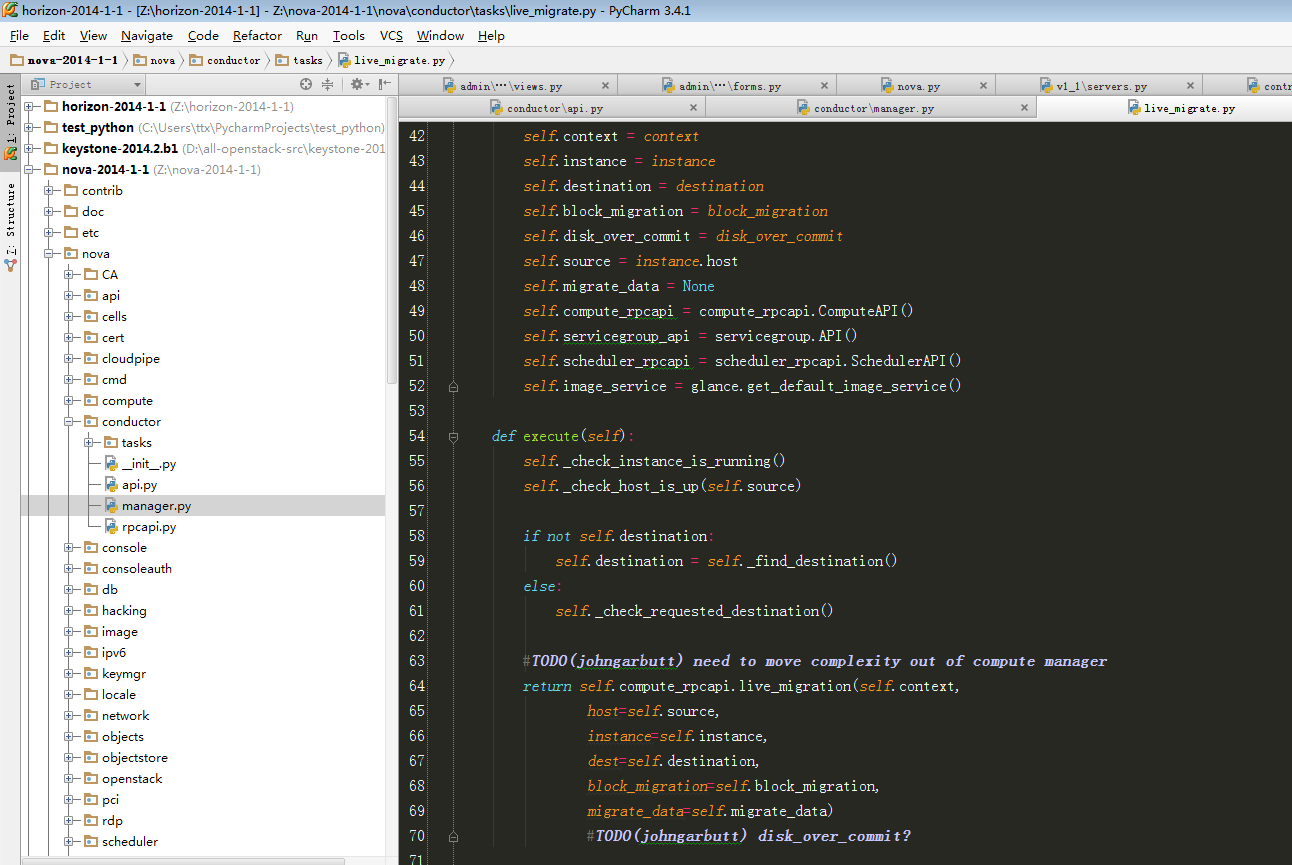
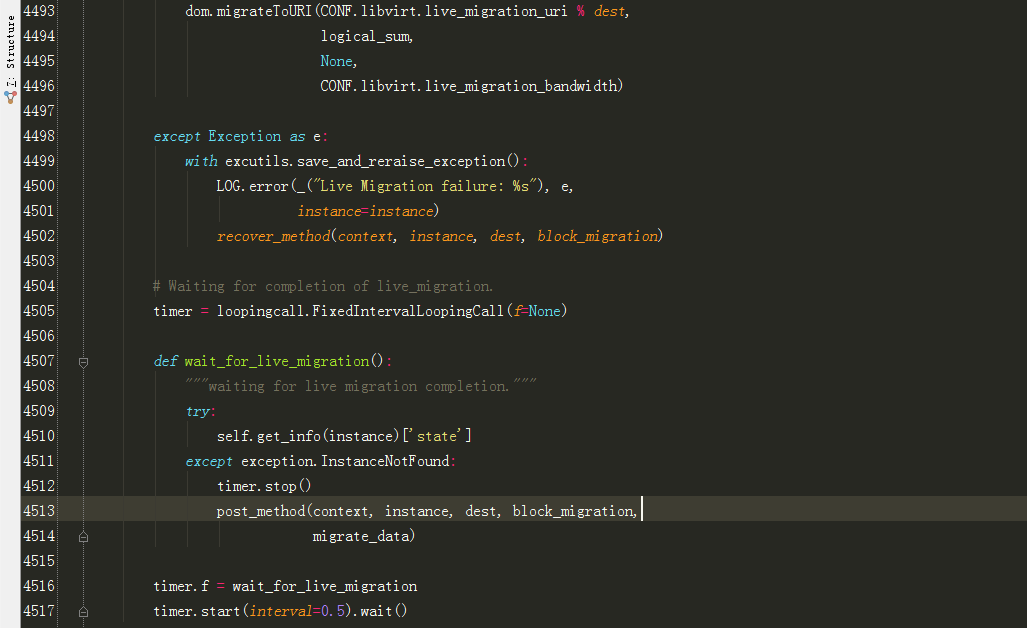
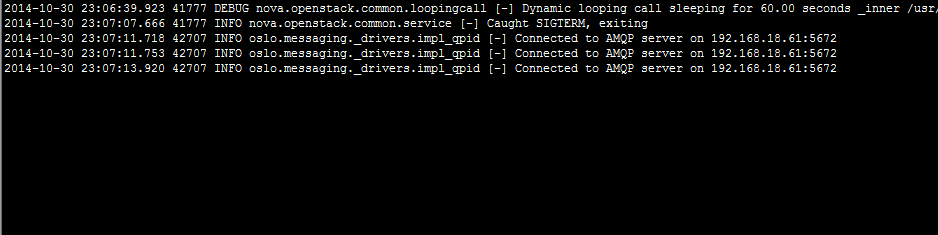
def wait_for_live_migration():
"""waiting for live migration completion."""
try:
self.get_info(instance)['state']
#此处一直获取实例状态,当实例被迁移走了,就会出现异常,说明迁移成功
except exception.InstanceNotFound:
timer.stop()
post_method(context, instance, dest, block_migration,
migrate_data)
|







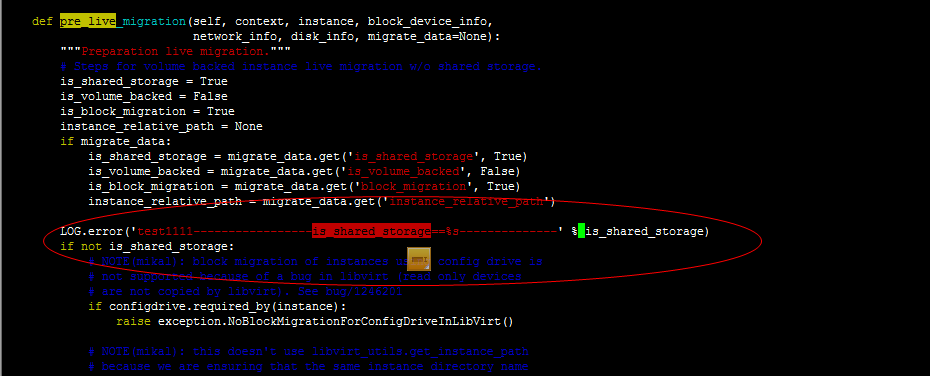

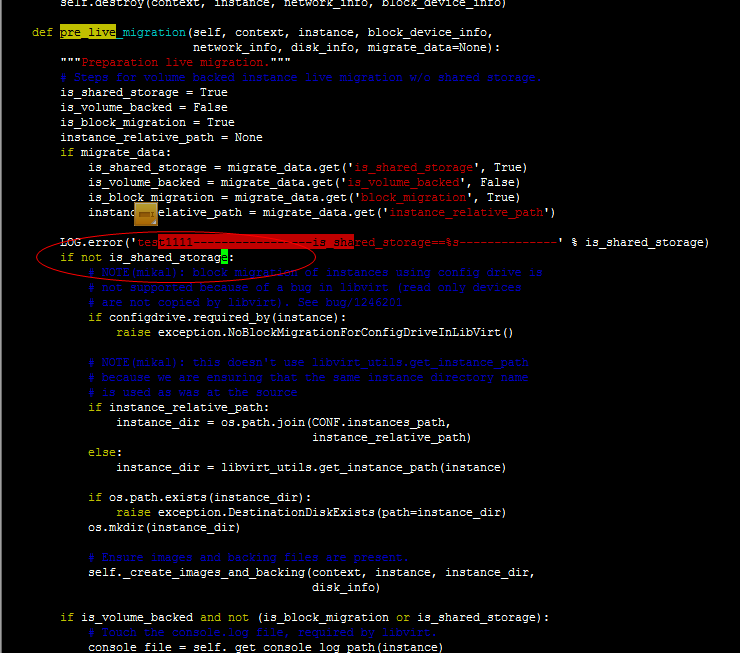
|
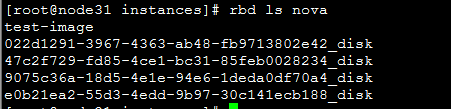
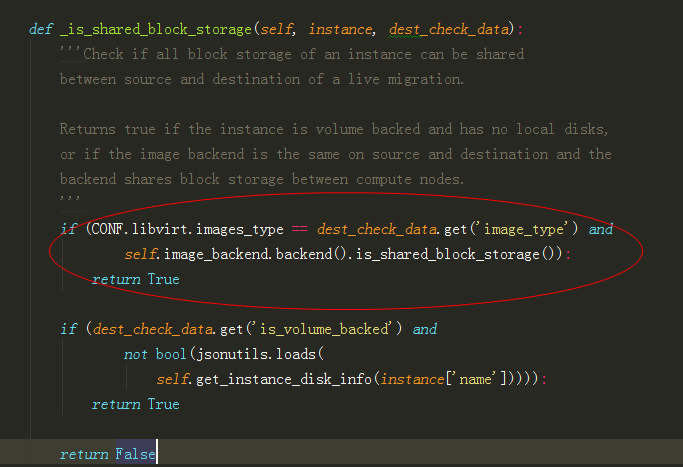
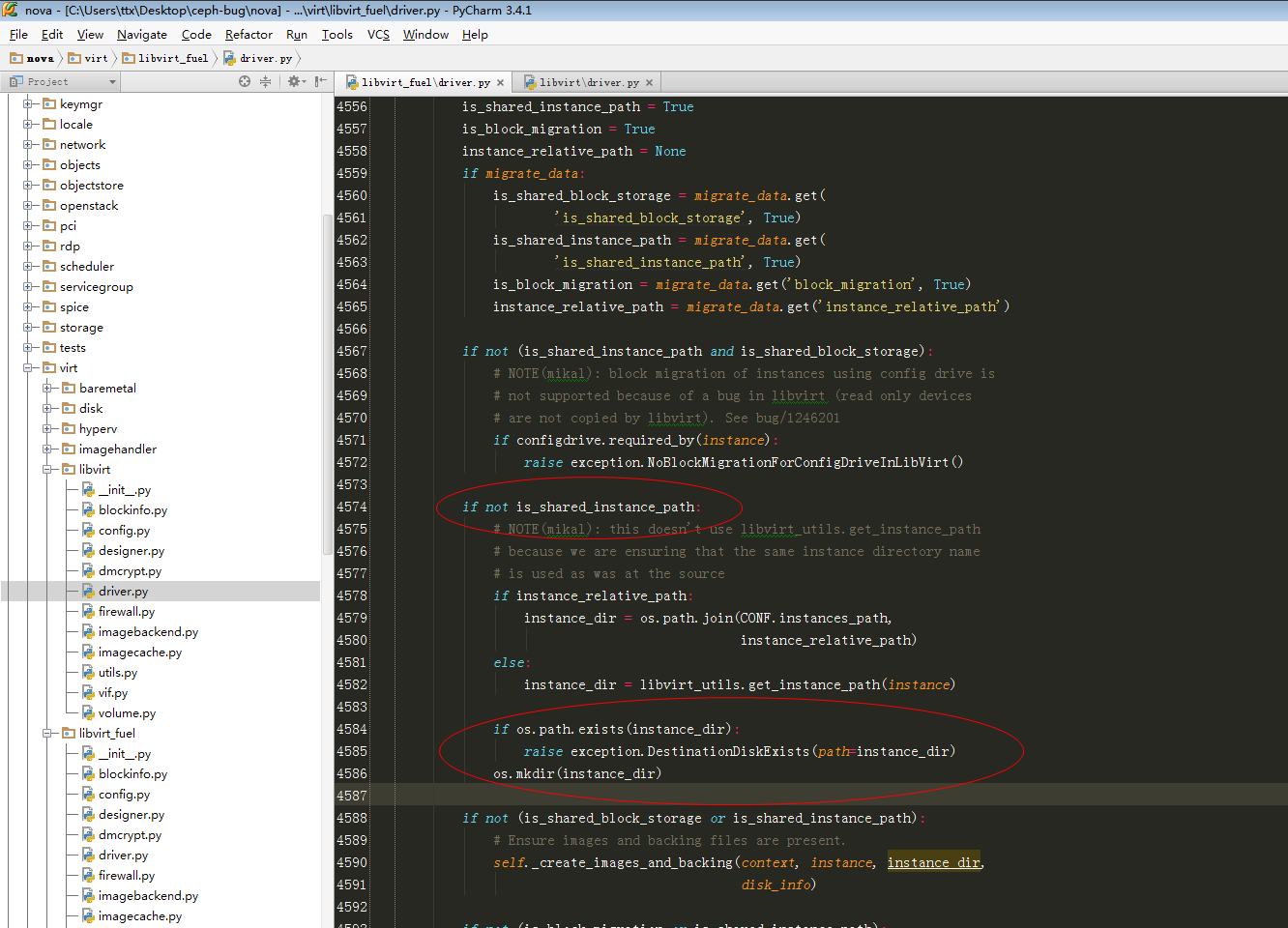
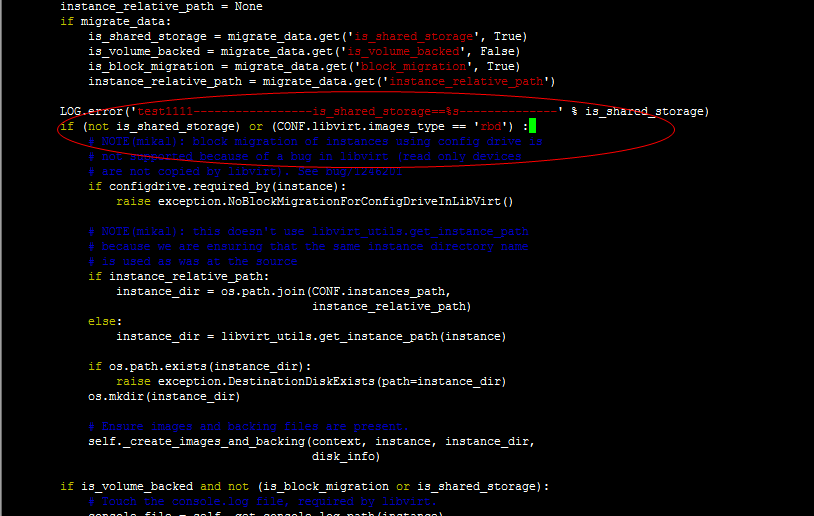
if (not is_shared_storage) or (CONF.libvirt.images_type == 'rbd') :
|


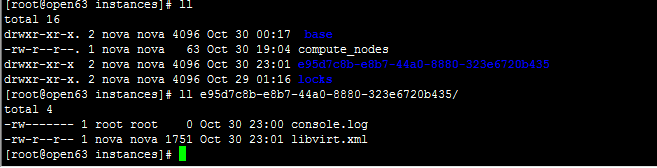
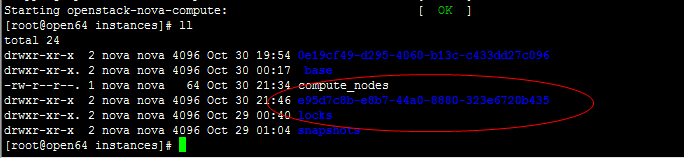
|
def wait_for_live_migration():
"""waiting for live migration completion."""
try:
self.get_info(instance)['state']
#此处一直获取实例状态,当实例被迁移走了,就会出现异常,说明迁移成功
except exception.InstanceNotFound:
timer.stop()
post_method(context, instance, dest, block_migration,
migrate_data)
|
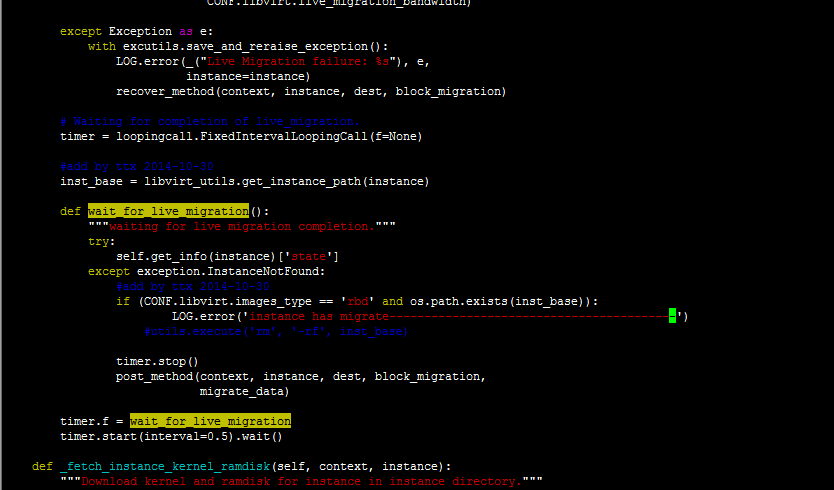

|
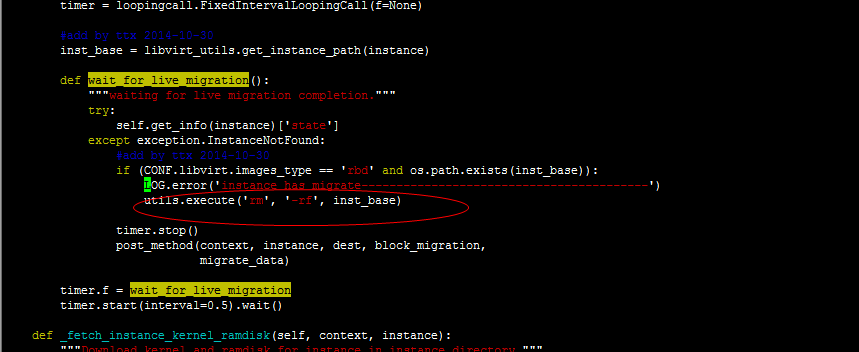
def wait_for_live_migration():
"""waiting for live migration completion."""
try:
self.get_info(instance)['state']
except exception.InstanceNotFound:
#add by ttx 2014-10-30
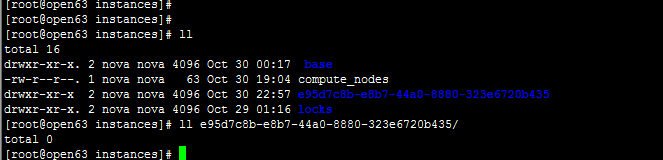
if (CONF.libvirt.images_type == 'rbd' and os.path.exists(inst_base)):
utils.execute('rm', '-rf', inst_base)
timer.stop()
post_method(context, instance, dest, block_migration,
migrate_data)
timer.f = wait_for_live_migration
timer.start(interval=0.5).wait()
|





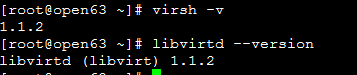
1 安装libvirt1.1.2
- openstack安装脚本openstack_init_env.sh中去掉libvirt的安装,当openstack_init_env.sh执行完之后,手动安装libvirt-1.1.2,安装完之后再执行后续的自动部署脚本。
- 安装libvirt-1.1.2:
解压libvirt-1.1.2源码安装包,进入源码目录
|
yum install -y libpciaccess-devel device-mapper-devel libnl-devel yajl-devel yajl ./configure --prefix=/usr/local/libvirt/ make make install mkdir -p /var/run/libvirt mkdir -p /usr/local/libvirt/var/lock/subsys cp -rf /usr/local/libvirt/bin/* /usr/bin/ cp -rf /usr/local/libvirt/sbin/* /usr/sbin/ cp -rf /usr/local/libvirt/libexec/* /usr/libexec/ cp -rf /usr/local/libvirt/etc/rc.d/init.d/* /etc/rc.d/init.d/ cp -rf /etc/init.d/functions /usr/local/libvirt/etc/rc.d/init.d/ cp -rf /usr/local/libvirt/lib64/python2.6/site-packages/* /usr/lib64/python2.6/site-packages/ cp -rf /usr/local/libvirt/etc/sysconfig/* /etc/sysconfig/ cp -rf /usr/local/libvirt/var/run/libvirt/* /var/run/libvirt check_file_exist "/usr/local/libvirt/etc/libvirt/libvirtd.conf" sed -i "/^[[:blank:]]*#[[:blank:]]*unix_sock_group/s/#unix_sock_group/unix_sock_group/g" /usr/local/libvirt/etc/libvirt/libvirtd.conf sed -i "/^[[:blank:]]*#[[:blank:]]*unix_sock_ro_perms/s/#unix_sock_ro_perms/unix_sock_ro_perms/g" /usr/local/libvirt/etc/libvirt/libvirtd.conf sed -i "/^[[:blank:]]*#[[:blank:]]*unix_sock_rw_perms/s/#unix_sock_rw_perms/unix_sock_rw_perms/g" /usr/local/libvirt/etc/libvirt/libvirtd.conf sed -i "/^[[:blank:]]*#[[:blank:]]*auth_unix_ro/s/#auth_unix_ro/auth_unix_ro/g" /usr/local/libvirt/etc/libvirt/libvirtd.conf sed -i "/^[[:blank:]]*#[[:blank:]]*auth_unix_rw/s/#auth_unix_rw/auth_unix_rw/g" /usr/local/libvirt/etc/libvirt/libvirtd.conf groupadd libvirt service libvirtd start |
- 继续执行剩余的自动部署脚本。
2、 配置libvirt1.1.2
修改文件
vim /usr/local/libvirt/etc/sysconfig/libvirtd
用来启用tcp的端口(本环境中由于libvirt升级过,配置文件目录不一致,默认为/etc/sysconfig/libvirtd)
|
1
2
3
|
LIBVIRTD_CONFIG=/usr/local/libvirt/etc/libvirt/libvirtd.conf
LIBVIRTD_ARGS="--listen"
|
修改文件
vim /usr/local/libvirt/etc/libvirt/libvirtd.conf
|
1
2
3
4
5
6
7
8
9
|
listen_tls = 0
listen_tcp = 1
tcp_port = "16509"
listen_addr = "0.0.0.0"
auth_tcp = "none"
|
运行 libvirtd
|
1
|
service libvirtd restart
|















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









