







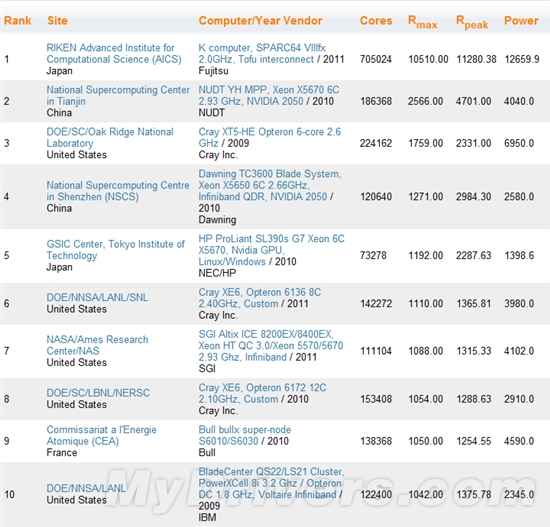
半年前,只建设完成一部分的“京”就轻而易举地将日本带上了超级计算机新王者的宝座,当时的最大性能为8.162千万亿次浮点计算每秒。不同于其它近来表现“猖狂”的高性能计算系统,“京”仍旧完全基于传统处理器,没有使用GPU加速。
现在的“京”配备了88128颗富士通SPARC64 VIIIfx 2.0GHz八核心处理器,核心总量705024个,最大计算性能1.051PFlops(10.51亿亿次每秒),峰值性能1.128038PFlops(11.28亿亿次每秒),有效率高达93.2%,同时总功耗为12659.9千瓦。
中国的“天河一号A”依然位列亚军,性能上完全不变,最大性能只有“京”的24.4%。事实上,除了一路狂奔的“京”之外,从第二名到到第十一名都没有丝毫变化。这种沉寂在高性能计算历史上实属罕见,TOP500总编辑Erich Strohmaier也表示:“自从1993年我们第一次发布(超算)排行榜以来,这是第一次前十名纹丝不动。”
新榜单的其他一些变化:
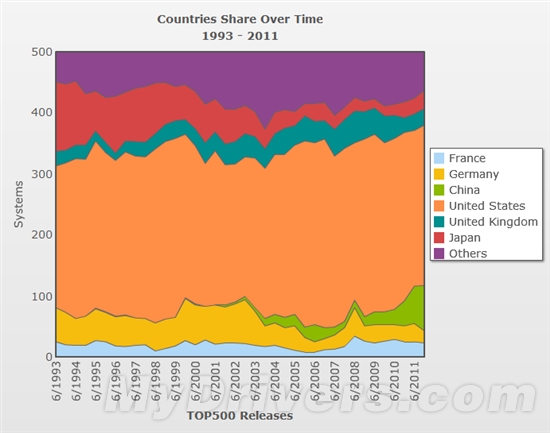
1、中国超算数量从62台大幅增至74台,稳居第二名,身后是日本30台、英国27台、法国23台、德国20台。
2、使用GPU加速的超算从17台猛增至39台,其中35台使用NVIDIA Tesla计算卡、2台使用Cell处理器、2台使用AMD Radeon显卡。
3、使用六核心及以上处理器的系统已经占据62%的份额。
4、Intel处理器所占份额虽然丢掉了0.6个百分点,但依然以76.8%高居第一,总计384台。AMD Opteron目前占据63台,也减少了3台。IBM处理器稳定在49台。
5、凭借“京”的出色表现,富士通在厂商性能方面小幅超过了Cray,但距离IBM依然还很远。
6、千兆以太网是最流行的内部互联技术,占据223台但比去年少了7台。InfiniBand系统从208台增至213台。从性能上看,InfiniBand系统的性能几乎是千兆以太网系统的两倍多,分别为28.7PFlops、14.2PFlops。
7、供应商方面,IBM 223台、惠普140台,分别比半年前增加5台、减少6台。
8、第500名的性能从半年前的39.1TFlops升至50.9TFlops。今年的最后一名半年前可排第305。所有系统总性能从一年前的43.7PFlops、半年前的58.7PFlops增加到74.2PFlops。
再看看功耗方面:
1、29台超算的功耗超过了1000千瓦。
2、“京”的功耗是最高的,12659.9千瓦,不过因为性能更彪悍,能耗比其实是最高的之一,达到了830MFlops/W。
3、能耗比最高的是蓝色基因/Q,2029MFlops/W。
4、所有系统平均能耗比282MFlops/W,比半年前、一年前提高了13.7%、28.8%。
5、前十名平均功耗45.6千瓦,比半年前增加了2.6千瓦,而能耗比维持464MFlops/W不变。
完整榜单:
http://www.top500.org/list/2011/11/100
http://cloud.csdn.net/a/20111116/307545.html















 2262
2262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









