








概述
注意:【慢速学数据结构】系列文章的完整代码都在我的Github上。
由于是第一篇,有一些重要的东西需要普及一下,深入理解了ADT概念的可以跳过。
- 抽象数据类型(ADT),是从抽象的角度来描述某种数据结构。抽象的级别可能会很高,比如这里直接用人脑中的形象思维来描述优先队列,会是这样的:一种队列,进去是按时间先后进去,出来是按优先级别出来。同理,队列在我们概念里同样也能用简洁的思维表示出来:让数据能够先进先出的结构。 抽象的东西本来不需要名字,只不过人类要交流,于是便有了名字。
- 用计算机的方式实现ADT。我们知道计算机里有存储器,操作系统使得我们在写程序的时候可以将存储器看成线性的,所以计算机最自然的数据结构就是线性表了,然后我们可以基于它实现ADT。
优先队列的实现,可以有很多方法, 比如用链表,每次插入始终让表保持排序状态,再者用二叉查找树,DeleteMin操作就需要去找到最左结点删除,然而我们并不需要它的所有功能,用它有点奢侈了。这篇文章, 主要讲的是二叉堆,你完全可以把它看作为优先队列而生的数据结构。
什么是堆呢?
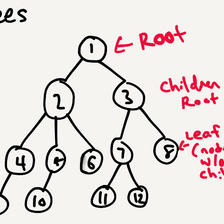
堆是一种基于树的数据结构,并且具有堆序性质。堆序性是指,父节点与孩子节点的关键字的值,始终维持一个顺序关系。因此,最典型的有最大堆或最小堆(如下图)。

值得注意的是,新手往往会把它和动态内存分配时的那个堆搞混淆,然而事实是这两者之间不存在一丝关系,只不过是术语重叠罢了。堆这个术语,一开始就是用来代表数据结构的。而那个代表内存的堆,从操作系统的内存管理来看,也没有用到任何堆序的概念,表示系统内存块的数据结构是位图,或者页表之类的,都是映射型的数据结构。
实现
堆最常见的实现是基于完全二叉树的,通常把这种堆叫做二叉堆,这里用来实现优先队列的就是二叉堆。
完全二叉树很有规律,因为它可以利用数组表示。这带来了两个好处。
一,对于数组中任意位置i的元素,它的左儿子在2i上,右儿子在2i+1上,它的父亲节点则在i/2(向下取整)上。遍历的时候速度很快。
二,由于树的高度为logN,所以那些针对一个元素的算法,复杂度也都是O(logN)。
现在来实现一个简单的基于二叉堆的优先队列(最小堆),先看类声明:
template<typename T>
class PriorityQueue{
public:
PriorityQueue();
PriorityQueue(int size);
virtual ~PriorityQueue();
void clear();
void destroy();
void push();
int pop();
const T& getTop() const;
const int& getSize() const;
const int& getCapacity() const
bool isEmpty() const;
bool IsFull() const;
private:
vector<T> container_;
int capacity_;
int size_;
};构造函数:
PriorityQueue() : container_(21, 0) {
size_ = 0;
capacity_ = container_.size();
// 这里有个技巧,让数组从1开始,这样i/2才能得到正确结果。
container_.push_back(INT_MIN);
}
PriorityQueue(int size) : container_(size*2+1, 0) {
size_ = 0;
capacity_ = container_.size();
container_.push_back(INT_MIN);
}插入函数:
// O(logN)
void push(const T &t){
int i;
// if is full , double size the capacity
if(isFull())
container_.resize( capacity_ = capacity_ * 2, 0);
// percolate up
for(i = ++size_; container_[i/2] > t; i/=2) {
container_[i] = container_[i/2];
}
container_[i] = t;
}删除函数(精华和难点所在):
// O(logN)
void pop() {
if(isEmpty())
return ;
T lastElement = container_[size_--];
auto i = 1, child = 1;
for( ; i * 2 <= size_; i = child) {
// find smaller child. Because the heap based on complete binary tree, if the node only has
// left child , it's child must be the last element, so we can simplify the
// code like this, i think it is clever
child = 2 * i;
if( child != size_ && container_[child] > container_[child+1] )
child++;
// percolate one level
if( lastElement > container_[child] )
container_[i] = container_[child];
else {
break;
}
}
container_[i] = lastElement;
}应用
top(k)问题,比如一百亿个数,求最大的一百个数
class solution {
solution(int k) : k_(k) {
}
vector<int> result;
priority_queue<int, std::vector<int>, std::greater<int>> minHeap;
int k_;
void topk(int n) {
if(minHeap.size()<=100) {
minHeap.push(n);
}else {
if(n>minHeap.top()) {
minHeap.pop();
minHeap.push(n);
}
}
}
const vector<int> getResult() const {
while(!minHeap.empty()) {
result.push_back(minHeap.top());
minHeap.pop();
}
return result;
}
};Dijkstra算法
基于贪心策略,需要不断的取路径中最短的结点,此时可以用优先队列来减少遍历次数















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









