







1、核心思想
先定义一些字母的含义:
- 文档集合D,topic集合T
- D中每个文档d看作一个单词序列< w1,w2,...,wn >,wi表示第i个单词,设d有n个单词。(LDA里面称之为word bag,实际上每个单词的出现位置对LDA算法无影响)
- D中涉及的所有不同单词组成一个大集合VOCABULARY(简称VOC)
LDA以文档集合D作为输入(会有切词,去停用词,取词干等常见的预处理,略去不表),希望训练出的两个结果向量(设聚成k个Topic,VOC中共包含m个词):
- 对每个D中的文档d,对应到不同topic的概率θd
< pt1,..., ptk >,其中,pti表示d对应T中第i个topic的概率。计算方法是直观的,pti=nti/n,其中nti表示d中对应第i个topic的词的数目,n是d中所有词的总数。 - 对每个T中的topic t,生成不同单词的概率φt
< pw1,..., pwm >,其中,pwi表示t生成VOC中第i个单词的概率。计算方法同样很直观,pwi=Nwi/N,其中Nwi表示对应到topic t的VOC中第i个单词的数目,N表示所有对应到topic t的单词总数。
LDA的核心公式如下:
p(w|d) = p(w|t)*p(t|d)
直观的看这个公式,就是以Topic作为中间层,可以通过当前的θd和φt给出了文档d中出现单词w的概率。其中p(t|d)利用θd计算得到,p(w|t)利用φt计算得到。
实际上,利用当前的θd和φt,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的p(w|d),然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响θd和φt。
LDA学习过程
LDA算法开始时,先随机地给θd和φt赋值(对所有的d和t)。然后上述过程不断重复,最终收敛到的结果就是LDA的输出。再详细说一下这个迭代的学习过程:
1)针对一个特定的文档ds中的第i单词wi,如果令该单词对应的topic为tj,可以把上述公式改写为:
pj(wi|ds) = p(wi|tj)*p(tj|ds)
先不管这个值怎么计算(可以先理解成直接从θds和φtj中取对应的项。实际没这么简单,但对理解整个LDA流程没什么影响,后文再说)。
2)现在我们可以枚举T中的topic,得到所有的pj(wi|ds),其中j取值1~k。然后可以根据这些概率值结果为ds中的第i个单词wi选择一个topic。最简单的想法是取令pj(wi|ds)最大的tj(注意,这个式子里只有j是变量),即
argmax[j]pj(wi|ds)
当然这只是一种方法(好像还不怎么常用),实际上这里怎么选择t在学术界有很多方法,我还没有好好去研究。
3)然后,如果ds中的第i个单词wi在这里选择了一个与原先不同的topic,就会对θd和φt有影响了(根据前面提到过的这两个向量的计算公式可以很容易知道)。它们的影响又会反过来影响对上面提到的p(w|d)的计算。对D中所有的d中的所有w进行一次p(w|d)的计算并重新选择topic看作一次迭代。这样进行n次循环迭代之后,就会收敛到LDA所需要的结果了。
2、公式描述
LDA方法使生成的文档可以包含多个主题,该模型使用下面方法生成1个文档:
Chooseparameter θ ~ p(θ);
For each ofthe N words w_n:
Choose a topic z_n ~ p(z|θ);
Choose a word w_n ~ p(w|z);
其中θ是一个主题向量,向量的每一列表示每个主题在文档出现的概率,该向量为非负归一化向量;p(θ)是θ的分布,具体为Dirichlet分布,即分布的分布;N和w_n同上;z_n表示选择的主题,p(z|θ)表示给定θ时主题z的概率分布,具体为θ的值,即p(z=i|θ)= θ_i;p(w|z)同上。
这种方法首先选定一个主题向量θ,确定每个主题被选择的概率。然后在生成每个单词的时候,从主题分布向量θ中选择一个主题z,按主题z的单词概率分布生成一个单词。其图模型如下图所示:
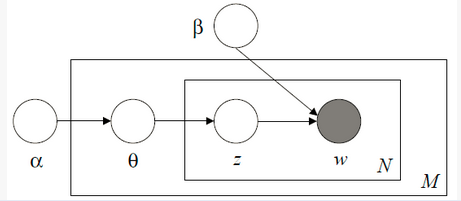
图1为大家经常看到的LDA图模型,其描述公式可表示为
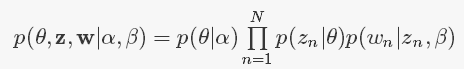
对于一个文档,LDA产生过程为:
(1) 由Dirichlet先验分布求topic的多项式分布参数,即theta ~ Dir(alpha)
Alpha是Dirichlet分布参数,theta=(theta1,theta2,…, theta_k)是产生topic的多项式分布参数,theta_k表示第k个主题被选择的概率。
(2) 根据theta生成一个topic z,即z~Multinormial(theta)
(3) 根据已有的topic,从分布p(w_n|z_n,beta)中选择一个word。
重复步骤(2)和(3),即可生成一篇文档doc。
beta表示一个K个主题、V个单词的K×V矩阵,beta_ij表示有主题z_i生成单词w_j的概率。根据上面描述,图1中的每一过程可进一步如图2细化所示。
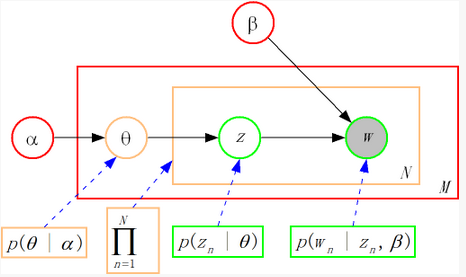
图2 LDA graphic model
图2中,三种颜色对应的表示层的简单说明:
(1) Corpus-level(红色):alpha和beta是语料级别参数,对于所有文档都是一样的,在generate过程中只需sample一次;
(2) Document-level(橙色):theta为文档级别参数,每个文档对应的theta不尽相同,对于每一个文档,都要sample一次theta;
(3) Word-level(绿色):z和w是文档级别变量,z有theta产生,然后再与beta生产w,对于每个word,z和w都要sample一次。

LDA的学习总结(精简):http://blog.csdn.net/a123456ei/article/details/22767429
4、对于参数迭代学习的处理
通过上面对LDA生成模型的讨论,可以知道LDA模型主要是从给定的输入语料中学习训练两个控制参数α和β,学习出了这两个控制参数就确定了模型,便可以用来生成文档。其中α和β分别对应以下各个信息:
α:分布p(θ)需要一个向量参数,即Dirichlet分布的参数,用于生成一个主题θ向量;
β:各个主题对应的单词概率分布矩阵p(w|z)。
把w当做观察变量,θ和z当做隐藏变量,就可以通过EM算法学习出α和β,求解过程中遇到后验概率p(θ,z|w)无法直接求解,需要找一个似然函数下界来近似求解,原文使用基于分解(factorization)假设的变分法(varialtional inference)进行计算,用到了EM算法。每次E-step输入α和β,计算似然函数,M-step最大化这个似然函数,算出α和β,不断迭代直到收敛
概率模型:
D 表示文档集合,最后就是保证P(D|α,β)最大。
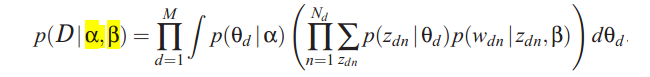
phi的迭代公式,表示文档中单词n在topic i上的分布:
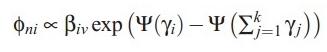
gamma的迭代公式,文档在topic上的分布
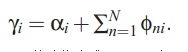
Beta的迭代公式,model中topic-word分布:
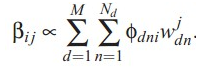
alpha的迭代公式,model中文档-topic分布的先验参数,利用梯度下降法即可求解:
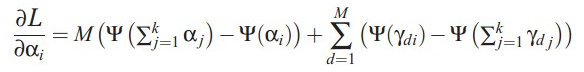
LDA最核心的迭代公式,针对每一篇文档,计算每个词的topic分布,从而计算文档的topic分布:
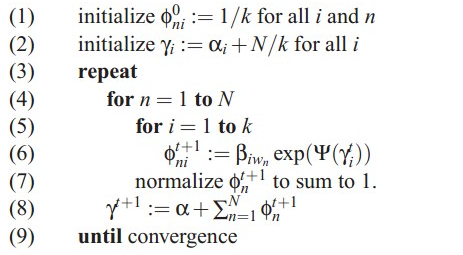
变分后,计算出来的似然函数,其似然值用户判断迭代的收敛程度:

基本逻辑:
1.初始模型参数,开始迭代,执行2,3,4,直至收敛
2.针对每一篇文档,初始gamma以及phi参数,迭代该参数,直至收敛(迭代公式:gamma即程序中theta:pti=nti+alpha/n+t*alpha,phi:pwi=Nwi+beta/N+w*beta,再相乘累加,判断决策。)
2.1.计算文档中每个单词在topic上的分布,利用model中beta以及文档-topic分布(2.2)
2.2.计算文档-topic分布,利用模型参数alpha以及word-topic分布(2.1结果)
3.update模型参数beta,利用word-topic分布。
4.update模型参数alpha,利用2.2的结果gamma
LDA的算法迭代解读与程序实现:http://blog.sina.com.cn/s/blog_4d1865f00101fk0e.html















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









