







最小生成树
我们把构造连通网的最小代价生成树称为最小生成树。普里姆算法和克鲁斯卡尔算法是生成最小生成树两种经典算法。
普里姆算法
普里姆算法是基于邻接矩阵存储结构的,
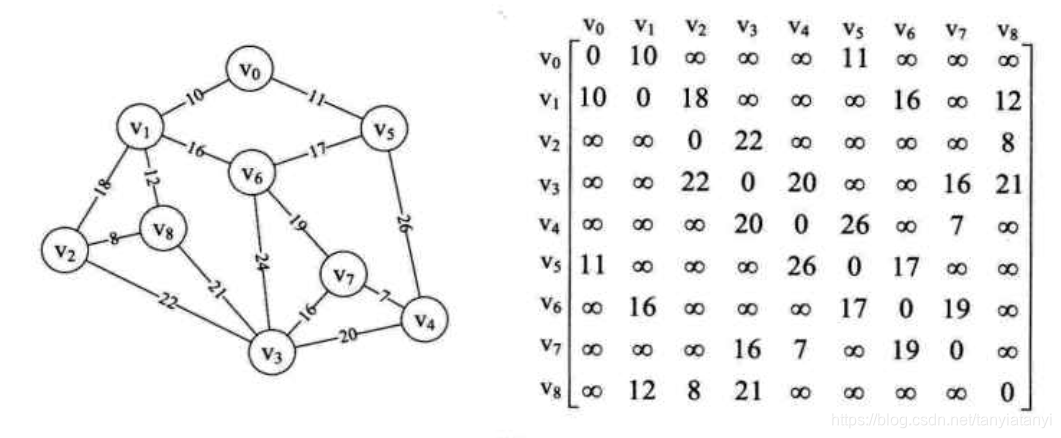
1 需要两个重要的数组adjvex[],lowcost[]。
adjvex[k]这个数组中k代表下一个顶点序号,adjvex[k]这个元素则是上一个顶点的序号,二者的边则是序号为adjvex[k]这个顶点权值最小的那条边。
lowcost[]则是不断并入新的结点的相关边的权值,决定下一步走哪条边权值最小。
2 初始化这两个数组,lowcost[]数组全部赋值起始结点邻接表的行值,adjvex[k]起初全部赋值其实结点的序号
3 开始大循环,每次循环打印一条边,故如果有n个顶点,则有n-1条边,循环从1开始。
4 第一个小循环负责选择出当前相同层(这是最小生成树的打印)顶点下,走哪一个边权值最小,并记录下一个顶点序号
5 根据数组adjvex[k]打印边(adjvex[k],k)
6 开始第二个小循环,把顶点k的邻接表的行,并入当前lowcost[],(比lowcost[]对应元素小的元素才配并入进去)
代码如下:
void MiniSpanTree_Prim(GRPH G)
{
int i,j,k,min;
int adjvex[maxvex];
int lowcost[maxvex];
adjvex[0] = 0;
lowcost[0] = 0;
for(i = 1; i < G.numvertexes; i++)
{
adjvex[i] = 0;
lowcost[i] = G.edges[0][i];
}
for(i = 1; i < G.numvertexes; i++)
{
min = INFINITY;
k = 0;
j = 1;
while(j < G.numvertexes)
{
if((lowcost[j] != 0) && (lowcost[j] < min))
{
min = lowcost[j];
k = j;
}
j++;
}
printf("(%d,%d)",adjvex[k],k);
lowcost[k] = 0;
for(j = 1; j < G.numvertexes; j++)
{
if((lowcost[j] != 0) && (G.edges[k][j] < lowcost[j]))
{
lowcost[j] = G.edges[k][j];
adjvex[j] = k;
}
}
}
}
克鲁斯卡尔算法
克鲁斯卡尔算法是基于边集数组结构的,边集数组结构是由三部分组成:1 边的权值,2 边的起始顶点,3 边的终点顶点。
结构体如下:
typedef struct
{
int begin;
int end;
int weight;
}Edge;
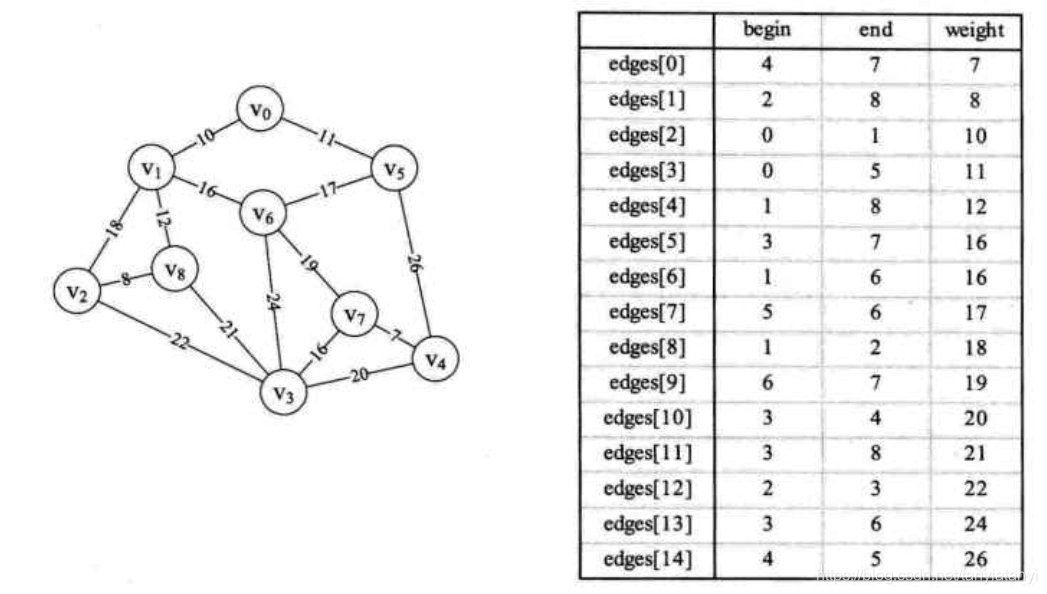
1 定义edges[],parent[]数组。
edges[]用来存储每条边依附的两个顶点,并且按照权值,从小到大排列
parent[]数组是用来存储已经连通的各种连通图,可以方便验证是否形成环了
2 介绍下Find()函数,用来判断某个顶点的边是否访问过,若是访问过则parent[f]>0,根据已经形成的连通图追溯到这个连通图还没有访问的那条边的另一端的顶点,只能从已经出现了的边去回溯。
3 通过循环不断判断连接edges[]数组里面的边是否会使当前的连通图形成环路。
4 若没有形成环路,则打印这条边,并记录新的连通图。
代码如下:
typedef struct
{
int begin;
int end;
int weight;
}Edge;
int Find(int *p,int vex)
{
while(p[vex] > 0)
vex = p[vex];
return vex;
}
void MiniSpanTree_Kruskal(GRPH G)
{
int i,n,m;
Edge edges[maxvex];
int parent[maxvex];
Handle(G,edges); //将邻接表转换成边集数组,并排好序
for(i = 0; i < G.numvertexes; i++)
parent[i] = 0;
for(i = 0; i < G.numvertexes; i++)
{
n = Find(parent,edges[i].begin);
m = Find(parent,edges[i].end);
if(n != m)
{
parent[n] = m;
printf("(%d,%d) %d",edges[i].begin,edges[i].end,edges[i].weight);
}
}
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









