







 本文介绍了Prometheus Agent模式的上手体验,包括拉模式和推模式的对比,Prometheus的HA、持久化和集群方案。重点讲述了Prometheus Agent如何通过远程写入到Thanos进行数据聚合,提供了启用Agent模式的步骤和配置,以及查询数据的流程。该模式适用于Prometheus的高可用、数据持久化和集群场景。
本文介绍了Prometheus Agent模式的上手体验,包括拉模式和推模式的对比,Prometheus的HA、持久化和集群方案。重点讲述了Prometheus Agent如何通过远程写入到Thanos进行数据聚合,提供了启用Agent模式的步骤和配置,以及查询数据的流程。该模式适用于Prometheus的高可用、数据持久化和集群场景。
大家好,我是张晋涛。
Prometheus 几乎已经成为了云原生时代下监控选型的事实标准,它也是第二个从 CNCF 毕业的项目。
当前,Prometheus 几乎可以满足各种场景/服务的监控需求。我之前有写过一些文章介绍过 Prometheus 及其生态,本篇我们将聚焦于 Prometheus 最新版本中发布的 Agent 模式,对于与此主题无关的一些概念或者用法,我会粗略带过。
拉模式(Pull)和 推模式(Push)
众所周知,Prometheus 是一种拉模式(Pull)的监控系统,这不同于传统的基于推模式(Push)的监控系统。
什么是拉模式(Pull)呢?

待监控的服务自身或者通过一些 exporter 暴露出来一些 metrics 指标的接口,由 Prometheus 去主动的定时进行抓取/采集,这就是拉模式(Pull)。即由监控系统主动的去拉(Pull)目标的 metrics。
与之相对应的就是推模式(Push)了。
由应用程序主动将自身的一些 metrics 指标进行上报,监控系统再进行相对应的处理。如果对于某些应用程序的监控想要使用推模式(Push),比如:不易实现 metrics 接口等原因,可以考虑使用 Pushgateway 来完成。
对于拉模式(Pull)和推模式(Push)到底哪种更好的讨论一直都在继续,有兴趣的小伙伴可以自行搜索下。
这里主要是聚焦于单个 Prometheus 和应用服务之间交互的手方式。本篇我们从更上层的角度或者全局角度来看看当前 Prometheus 是如何做 HA、 持久化和集群的。
Prometheus HA/持久化/集群的方案
在大规模生产环境中使用时,很少有系统中仅有一个单实例 Prometheus 存在的情况出现。无论从高可用、数据持久化还是从为用户提供更易用的全局视图来考虑,运行多个 Prometheus 实例的情况就很常见了。
目前 Prometheus 主要有三种办法来将多个 Prometheus 实例的数据进行聚合,并给用户提供一个统一的全局视图。
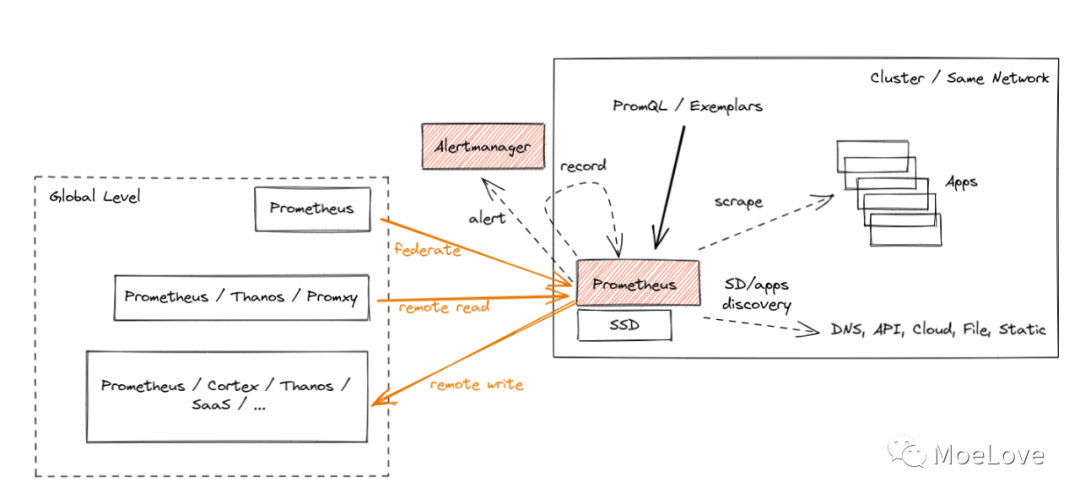
联邦(Federation):是最早期的 Prometheus 内置的数据聚合方案。这种方案下,可以使用某个中心 Prometheus 实例从叶子 Prometheus 实例上进行指标的抓取。这种方案下可以保留 metrics 原本的时间戳,整体也比较简单;
Prometheus Remote Read(远程读):可以支持从远程的存储中读取原始 metrics,注意:这里的远程存储可以有多种选择。当读取完数据后,便可对它们进行聚合,并展现给用户了;
Prometheus Remote Write(远程写):可以支持将 Prometheus 采集到 metrics 等写到远程存储中。用户在使用的时候,直接从远端存储中读取数据,并提供全局视图等;
Prometheus Agent 模式
Prometheus Agent 是自 Prometheus v2.32.0 开始将会提供的一项功能,它主要是采用上文中提到的 Prometheus Remote Write 的方式,将启用了 Agent 模式的 Prometheus 实例的数据写入到远程存储中。并借助远程存储来提供一个全局视图。
前置依赖
由于它使用了 Prometheus Remote Write 的方式,所以我们需要先准备一个 "远程存储" 用于 metrcis 的中心化存储。这里我们使用 Thanos 来提供此能力。当然,如果你想要使用其他的方案,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2614
2614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











