







RAM缓存
新RAM缓存算法(CLFUS)
新的RAM缓存使用的创意来自许多缓存替换策略和算法,包括LRU,LFU,CLOCK,GDFS及2Q,它被命名为时钟周期内最小频繁使用大小算法CLFUS(Clocked Least Frequently Used by Size)。它避开了任何专利算法,具有如下特性:
- 均衡最近性(Recentness),频率(Frequency)和大小(Size)以最大化
命中率(hit byte,不是字节命中率byte hit rate) 耐扫描(scan resistant),命中率提取可靠,即使工作集并不适应RAM Cache- 支持
3级压缩率: fastlz, gzip(libz库)和xz(liblzma库),压缩工作可以移至另外一个线程处理 非常低的CPU开销,仅略高于基础的LRU,没有使用O(lgn)堆,而是使用O(1)成本的概率替换策略(probabilistic replacement policy)相对低的内存开销,内存中的每个对象平均大约200字节
强调命中率而不是字节命中率的合理性,是因为从次级存储设备(硬盘)读取更多字节的开销(overhead)较之一个请求的成本(cost)更低。
RAM缓存由最前面的两个LRU/CLOCK对象哈希链表和一个seen哈希表组成。第一个缓存链表包含内存中的对象,但是第二个链表包含了近来放入缓存中或者打算放入缓存中的对象的历史信息(history of objects),seen哈希表用来使算法耐扫描。
下表中的元素(对应源码中的RamCacheCLFUSEntry)记录了下面的信息:
- key
16字节的唯一对象标识符 - auxkeys
相当于8字节的版本号(系统中分区的块),当对象的版本号改变时,旧元素将从缓存中删除掉 - hits
当前时钟周期内的命中数 - size
缓存中对象的大小,包括填充 - len
对象的实际长度,因为压缩和填充的原因,和size有区别。 - compressed_len
对象压缩后的长度 - compressed
压缩类型,可能的值是fastlz, libz和liblzma,不可压缩时值为none - uncompressible
true表示对象内容可以压缩,false表示不可压缩 - copy
对象是否应该复制进来或复制出去(比如,HTTP HDR) - LRU link
所在的LRU链表,有两个(cached list和history list) - HASH link
所在bucket的双链表 - IOBufferData
数据缓存(data buffer)的智能指针
缓存接口是Get和Put操作,Get操作检查一个对象是否在缓存中,在将要读取时调用,Put操作决定是否将给定的对象放入缓存中,它在从磁盘中读取对象后调用。
RamCacheCLFUS::get伪代码算法分析:
if X is in cached list then
move X to the tail of cached list, and return the data in X
else if X is in history list then
move X to the tail of history list
"cache miss"
else
"cache miss"
end if
RamCacheCLFUS::put伪代码算法分析:
if X is in cached list then
move X to the tail of cached list, and update its data
else if X is in history list then
if cached list has room to place X then
insert X to the tail of cached list, and update its data
else
create list V
do
pop one page Y from cached list
//simulate the aging algorithm, for avoiding cache pollution
pop one page Z from history list
if HIT_VALUE(Z) is not greater than 1 then
delete Z
else
let the HIT_VALUE(Z) with 1, and reinserted Z to the tail of history list
end if
//end
if CACHE_VALUE(X) is greater than CACHE_VALUE(Y) then
push it to V
else
insert X to the tail of history list and update its data, return
end if
util cached list has enough room for placing X
end do
for(Z in V)
if cached list has room for both Z and X, then
reinsert Z to the tail of cached list
insert X to the tail of cached list, and update its data
end if
end for
end if
else // X is neither in history list nor in cached list
//judge X is or not first accessed by seen hash
if X is first accessed and history list has no room for it, then
save the record of X in seen hash
else
insert X to the tail of history list
end if
end ifSeen Hash
ATS冷启动后,Cached链表和History链表填满,将激活Seen链表。该链表的作用是缓存耐扫描,这意味着,经过对缓存中只见到一次的对象们做一长串的Get和Put操作,缓存状态一定不能受到影响。这是最本质的,如果没有这点保证,不仅缓存会受到污染,而且会丢失它所关注的对象相关的重要信息。所以,Cache链表和History链表不会受到第一次见到的对象上的Put操作和Get操作的影响是非常关键的。Seen Hash维护着一个16比特哈希标签(hash tags)的集合,未命中对象缓存(Cache链表和History链表中的)的请求,以及不匹配哈希标签的请求,导致哈希标签被更新,否则会被忽略。Seen Hash的大小近似缓存中的对象数,为了匹配用Cached链表和History链表的CLOCK率传给它的个数。
Cached List
Cached链表含有实际在内存中的对象,基本操作就是LRU,新对象插入FIFO队列中,命中导致对象被重新插入链表尾部。当要考虑插入一个对象时,会有一个有趣的bit位,首先检查对象哈希去看对象是否在Cached链表或者History链表中。命中意味着更新hit域并重新插入对象到链表尾部。History命中导致hit域被更新,然后比较对象是否保存在内存中。比较基于Cached链表中的最近最少使用元素,并基于一个加权频率:
CACHE_VALUE = hits / (size + overhead)
该公式类似GDFS算法,用于计算对象的缓存值,这里hits是请求对象的命中率,size是该对象的大小,overhead是一个加权值,在代码中设置为256。该公式从直观上比较易于理解,那些访问次数多的小对象将会更易于进入RAM中,这比较符合事实。
新对象必须有足够的字节值得当前缓存的对象去覆盖它。每次,当一个对象被认为可替换时,CLOCK就向前移动。假如History对象的值更大,就将它插入Cached链表,被替换的对象从内存中移除,并插入到History链表中。视作替换(至少一个)但还没有替换的对象,它们的hits域设为0,被重新插入Cached链表中,这就是Cached链表上的CLOCK操作。
History List
每个CLOCK操作时,History链表中的最少最近使用的元素被取出,假如hits域不超过1(History链表和Cached链表中至少命中一次)将被删除。否则,hits域设为0,被重新放入History链表中。
压缩和解压
压缩被后台操作执行(当前称作Put操作的一部分),后台操作维护了一个指向Cached链表的指针,并向头部正在压缩的元素前进。在Get操作过程中,解压根据要求进行。当对象被标记为copy时,压缩版本将被再次插入LRU中,因为我们需要做一次拷贝,没有标记为copy的那些对象被插入未压缩LRU中,希望它们能以未压缩形式重用。有一个编译时间选项,或许是我们想改变的东西。
下面是三种压缩算法和级别的对比(在Intel i7 920系列CPU上使用单线程测试)
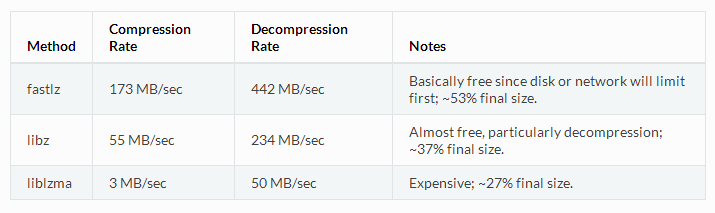
这些都是粗略数字,你的测试结果可能相差很大。比如说,JPEG并不会用上述任何一种算法压缩(或者至少只会在个别级别做这种测试,压缩和解压成本完全没有说服力),对其它许多嵌入某种压缩形式的媒体和二进制文件类型也是如此。RAM缓存探测不到具体的压缩级别,假如压缩后的文件大小不能达到原来大小的90%以下,RAM缓存就认为该文件是不可压缩的,并将这个值缓存下来,RAM缓存不会企图再去压缩它(至少在history中的这段时间内)。
参考文献
https://docs.trafficserver.apache.org/en/latest/developer-guide/architecture/ram-cache.en.html
http://blog.chinaunix.net/uid-23242010-id-147401.html
http://blog.chinaunix.net/uid-23242010-id-147989.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









