







转载学习:http://blog.csdn.net/a819825294/article/details/51177435,如有侵权,联系删除
1.分类回归树CART
随机森林是由多颗CART树组成的,下面简单叙述下回归树及生成树的算法
(1)最小二乘回归树生成算法

(2)分类树的生成
分类树可以使用基尼指数作为分类标准,至于为什么上面的指标,我们可以从信息论的角度思考。同样采样这样的分类标准会导致生成树选择最优属性时会偏向类别比较多的属性,因此在实际使用的过程中应对数据集进行处理或者控制树的深度。虽然决策树算法可以通过剪枝(正则、验证集测试)或者早停止策略尽量避免过拟合,但性能上依旧不能令人满意。
2.随机森林定义
随机森林是一个树型分类器{h(x,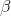
3.随机森林算法(单机版本)
随机选取训练样本集:使用Bagging方法形成每颗树的训练集
随机选取分裂属性集:假设共有p个属性,指定一个属性数p≤m,在每个内部结点,从M个属性中随机抽取F个属性作分裂属性集,以这p个属性上最好的分裂方式对结点进行分裂(在整个森林的生长过程中, F的值一般维持不变)
细节:
用作分类时,m默认取 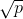
用作回归时,m默认取 p / 3,最小取5
m是一个可调的参数
4.泛化误差
样本点间隔函数:
对于给定的分类器,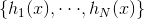
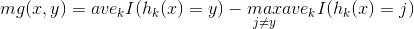
mg(x,y)衡量了分类器集合将样本分对的平均票数与将其错分为其他类的平均票数之差,mg(x,y)>0表明这个样本被这组分类器分类正确,否则被分错,mg(x,y)越大,表明分类器对这个样本的分类性能越好
分类器集合的泛化误差定义为:
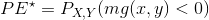
随机森林对于(x,y)的间隔函数为:
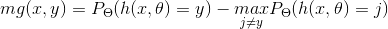
随机森林的分类强度定义为:

随机森林泛化误差的估计:
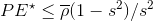
其中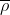
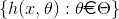
5.影响分类性能的主要因素
森林中单颗树的分类强度(Strength):每颗树的分类强度越大,则随机森林的分类性能越好。
森林中树之间的相关度(Correlation):树之间的相关度越大,则随机森林的分类性能越差。
6.OOB(Out Of Bag)估计
在bootstrapping的过程中,有些数据可能没有被选择,这些数据称为out-of-bag(OOB) examples,对于训练每一个gt,其中用“”标注的数据即是gt的OOB examples。

下面的公式是经过N’次选择之后没有被选择的数据,大约有(1/e)N多的数据没有被选择到,即大约有三分之一的数据没有被选择,这些数据由于没有用来训练模型,故可以用于模型的验证。
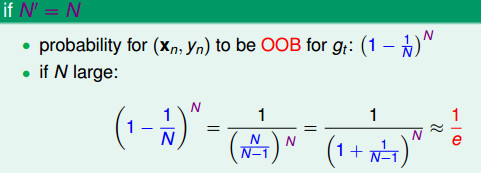
上图中,(xN,yN)这一个数据由于没有用于g2,g3,gT的训练数据,故可以用来作为它们的验证数据。所以(xN,yN)可以作为G-的验证数据,其中G-(x)=average(g2, g3, gT)。
下面给出了OOB Error(Eoob)的公式,G的OOB Error的估算是通过不同的G-来平均得到的,所以,在bootstrap的过程就可以自己去验证模型的性能好坏,不需要单独划分一块数据作为专门的验证数据。
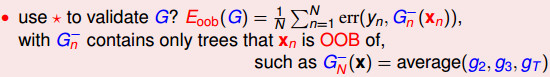
下面是随机森林算法中使用OOB Error进行验证的方法:

随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计
7.特征选择
在随机森林中某个特征X的重要性的计算方法如下:
(1)对于随机森林中的每一颗决策树,使用相应的OOB(袋外)数据计算它的袋外数据误差,记为errOOB1。
(2)随机地对袋外数据所有样本的特征X加入噪声干扰(就可以随机的改变样本在特征X处的值),再次计算它的袋外数据误差,记为errOOB2。
(3)假设随机森林中有Ntree颗树,那么对于特征X的重要性 = ∑(err00B2-errOOB1)/Ntree,之所以可以用这个表达式来作为相应特征的重要性的度量值是因为:若给某个特征随机加入噪声之后,袋外的准确率大幅度下降,则说明这个特征对于样本的分类结果影响很大,也就是说它的重要程度比较高。
8.特点
- 两个随机性的引入,使得随机森林不容易陷入过拟合
- 两个随机性的引入,使得随机森林具有很好的抗噪声能力
- 对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化。
- 可生成一个Proximities=(pij)矩阵,用于度量样本之间的相似性: pij=aij/N, aij表示样本i和j出现在随机森林中同一个叶子结点的次数,N随机森林中树的颗数。
- 可以得到变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量)
9.sklearn-RandomForest参数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
更加详细的内容见 sklearn-RandomForest地址
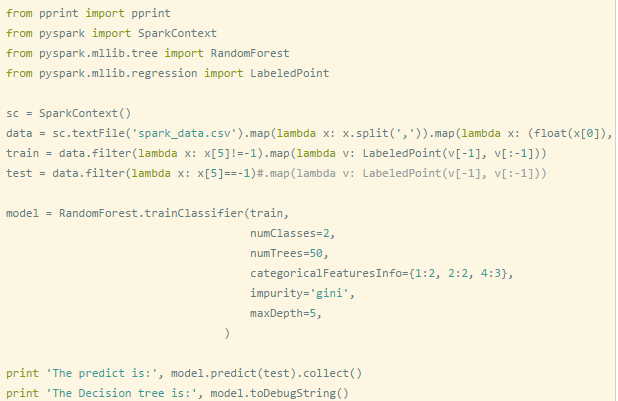
10.分布式spark-mlib-randomForest简单使用
11.随机森林在分布式环境下的优化策略
随机森林算法在单机环境下很容易实现,但在分布式环境下特别是在 Spark 平台上,传统单机形式的迭代方式必须要进行相应改进才能适用于分布式环境,这是因为在分布式环境下,数据也是分布式的,算法设计不得当会生成大量的 IO 操作,例如频繁的网络数据传输,从而影响算法效率。
单机环境下数据存储

分布式环境下数据存储

因此,在 Spark 上进行随机森林算法的实现,需要进行一定的优化,Spark 中的随机森林算法主要实现了三个优化策略:
(1)切分点抽样统计,如下图所示。在单机环境下的决策树对连续变量进行切分点选择时,一般是通过对特征点进行排序,然后取相邻两个数之间的点作为切分点,这在单机环境下是可行的,但如果在分布式环境下如此操作的话,会带来大量的网络传输操作,特别是当数据量达到 PB 级时,算法效率将极为低下。为避免该问题,Spark 中的随机森林在构建决策树时,会对各分区采用一定的子特征策略进行抽样,然后生成各个分区的统计数据,并最终得到切分点。
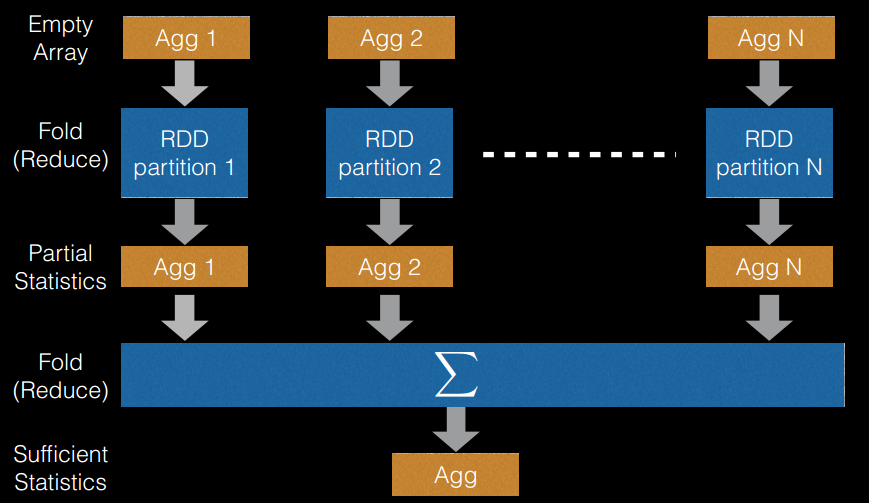
(2)特征装箱(Binning),如下图所示。决策树的构建过程就是对特征的取值不断进行划分的过程。
对于离散的特征,如果有 M 个值,最多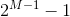
如果是有序的,即按老,中,少的序,那么只有 m-1 个,即 2 种划分,老|中,少;老,中|少。
对于连续的特征,其实就是进行范围划分,而划分的点就是 split(切分点),划分出的区间就是 bin。对于连续特征,理论上 split 是无数的,在分布环境下不可能取出所有的值,因此它采用的是(1)中的切点抽样统计方法。
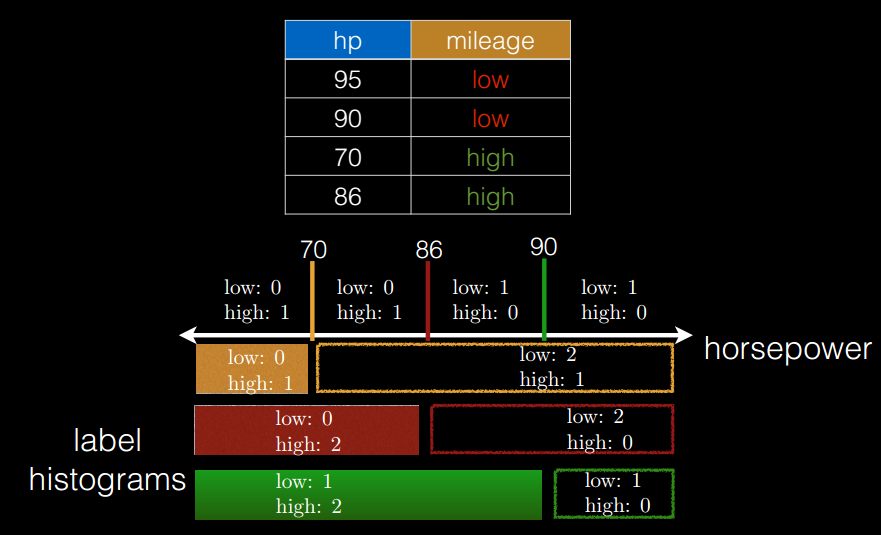
(3)逐层训练(level-wise training),如下图所示。单机版本的决策数生成过程是通过递归调用(本质上是深度优先)的方式构造树,在构造树的同时,需要移动数据,将同一个子节点的数据移动到一起。此方法在分布式数据结构上无法有效的执行,而且也无法执行,因为数据太大,无法放在一起,所以在分布式环境下采用的策略是逐层构建树节点(本质上是广度优先),这样遍历所有数据的次数等于所有树中的最大层数。每次遍历时,只需要计算每个节点所有切分点统计参数,遍历完后,根据节点的特征划分,决定是否切分,以及如何切分。
12.实战Tip
(1)使用RF参数(n_estimators、max_depth、class_weight)很重要
(2)RF可以作为辅助模型进行特征选择
(3)注意样本均衡















 3107
3107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









