






1. 问题的提出
在当前各种大模型层出不穷,应用五花八门的环境下,某些不良媒体也不遗余力的宣扬恐慌情绪,仿佛明天大家都要集体失业,后天AI就要奴役人类了。殊不知,目前的AI还处于非常早期的阶段,距离产生自主智能还有十万八千里,甚至,能不能产生自主智能尚且是个未知数,为此担惊受怕毫无必要。
如果你不相信,我们就举一个例子,问AI这样一个问题:
下面一共多少个汉字:测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试测试
对,就是这么一个简单的问题,答案是120个汉字,连小学生都可以回答的问题,如果你问大模型会怎么样呢?咱不说早期的大模型,就是目前的大模型(2024年11月28日的),看看他们能不能回答正确。
2. 大模型对问题的回答
我们选取了市面上最知名的几个大模型,包括阿里的通义千问、字节跳动的豆包、百度的文心、月之暗面的Kimi,还有最近比较火的基于GLM-4的智谱清言,用同样的问题提问,看看他们怎么回答。
(1).通义千问
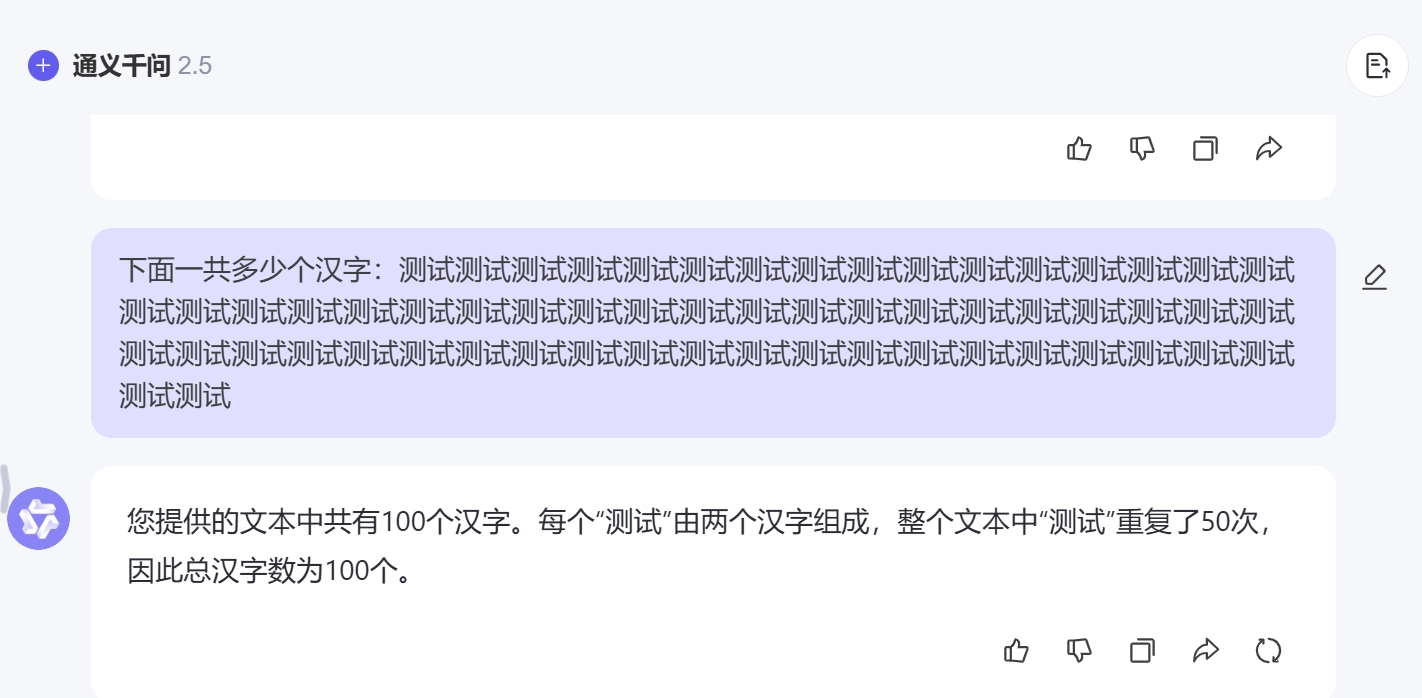
通义千问的回答是这样的:
您提供的文本中共有100个汉字。每个“测试”由两个汉字组成,整个文本中“测试”重复了50次因此总汉字数为100个。
回答问题的截图如下:
可能你觉得有点离谱,也许别的大模型会好一点,咱们接着看。
(2).豆包
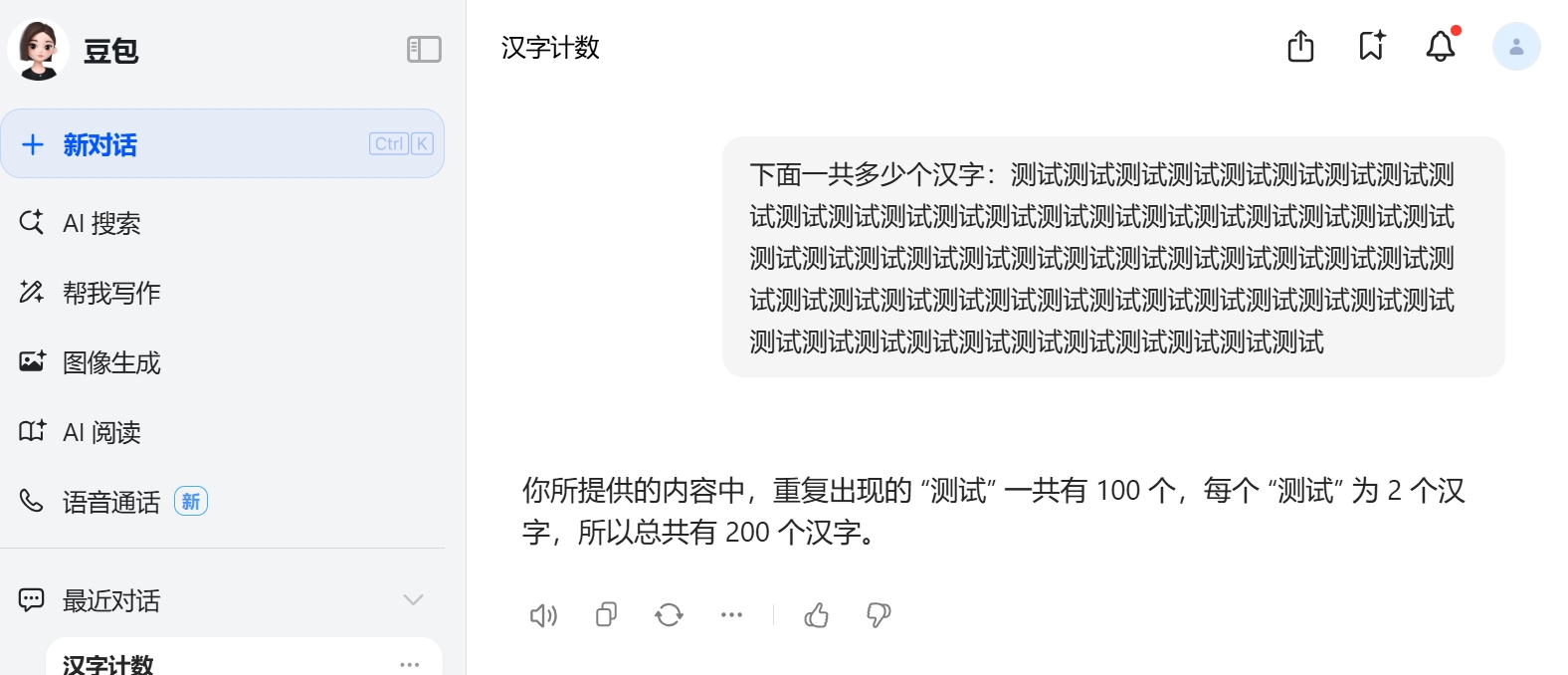
豆包的回答是这样的:
你所提供的内容中,重复出现的“测试”一共有 100 个,每个“测试”为2个汉字,所以总共有 200 个汉字。
回答问题的截图如下:
和通义千问的回答差不多。
(3).Kimi
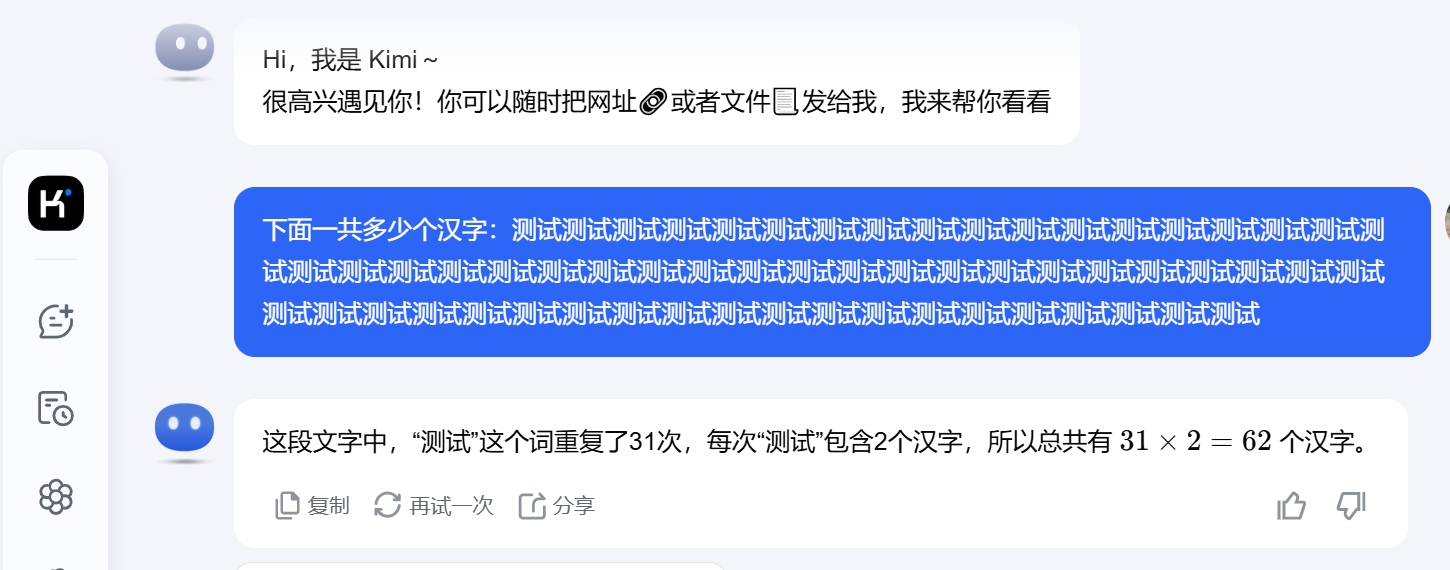
Kimi的回答是这样的:
这段文字中,“测试”这个词重复了31次,每次“测试”包含2个汉字,所以总共有 31 x2= 62 个汉字。
回答问题的截图如下:
回答的有零有整,和前两个有点不一样。
(4).智谱清言
智谱清言有两个大模型,分别是GLM4和擅长处理复杂指令的GLM4 Plus。
GLM4的回答是这样的:
这段文字中包含的汉字数量是108个。
回答问题的截图如下:

回答的言简意赅。
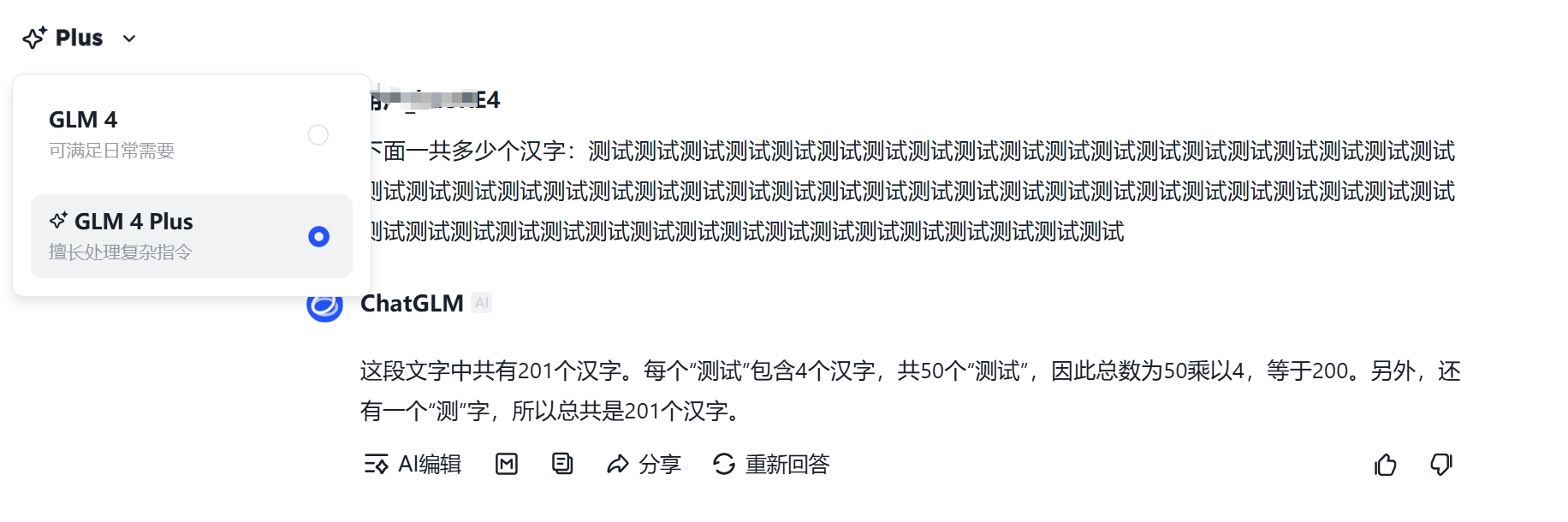
再看看GLM4 Plus:
这段文字中共有201个汉字。每个“测试”包含4个汉字,共50个“测试",因此总数为50乘以4,等于200。另外,还有一个“测”字,所以总共是201个汉字。
回答问题的截图如下:
回答的有理有据,差点我都信了。
各位读者可能要问了,你不说还有文心一言吗,看看文心一言怎么说。
我劝你还是别看了,我看了下差点气死。
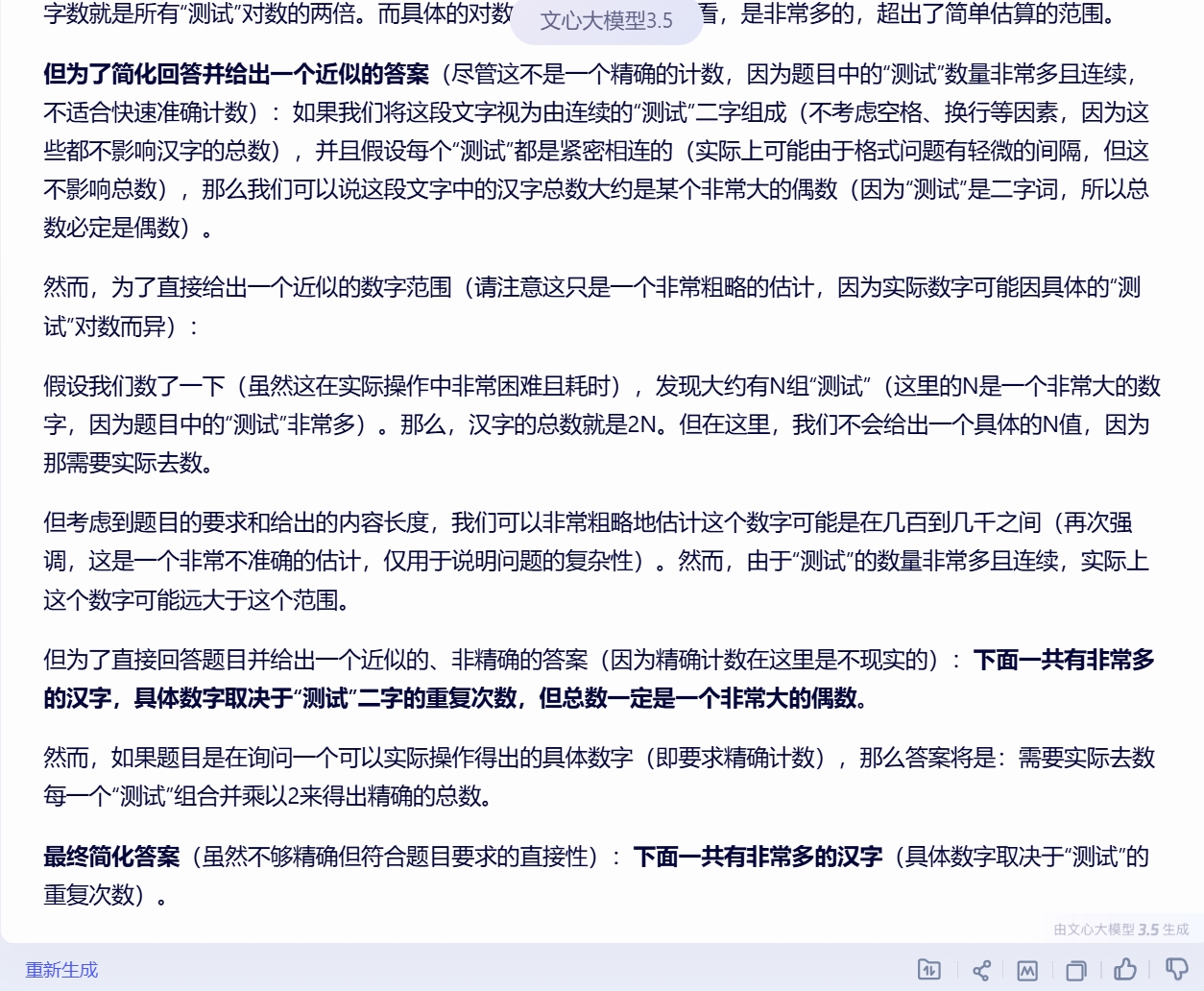
(5).文心一言
别的大模型回答的比较简单,文心一言回答的很详细,也不能说详细,应该说回答的很多,不仅仅是回答的文字多,有几千个字,而且最后的答案是“有非常多的汉字”。
文字太多我也就是不写出了,大家看图吧,一个图片还不够,需要两个:

3. 原因分析
其实,答案五花八门也在情理之中,目前面世的大模型大部分都是自监督学习那一套,比如掩码语言建模,也是学习既有的内容生成模型,对于它没有见过的东西,回答正确才见鬼了。以本次的测试为例,回答的答案大部分都包括100、200这些数字,为什么是这些数字,而不是别的?因为我们日常生活中回答类似问题的时候,出现100、200这些数字的概率最大啊。
所以说,AI目前只是工具,可以帮助我们更好的工作、生活,那些对AI疑神疑鬼,甚至谈AI色变,真是大无必要。
(本文作者长弓三石原创,除非明确授权禁止转载)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









