






Oracle基础概念
Oracle体系结构
安装完Oracle后,其本身就可以看作是一个大的数据库。
实例
但是在使用之前,必须先创建实例。实例官方来说是由一系列的后台进程(Background Processes) 和内存结构(Memory Structures)组成。即instance=SGA+background process简单理解就是,实例是一个独立的数据库,我们安装的Oracle服务器上可以有多个实例。为什么要有实例这个概念呢?因为有些场景是在同一台服务器上,需要安装多个Oracle,来互相隔离,但是甲骨文公司就给出方案说不用安装多个Oracle,直接建多个实例就可以达成同一台服务器上有多个Oracle的效果。实际实现仍然都创建在同一个Oracle服务器上,但是每个实例互不相干。
查看实例:
SELECT * FROM V$INSTANCE;数据文件
数据文件就是Oracle真正存放数据的物理存储单位,以.dbf作为其文件后缀名。数据文件与表空间紧密相连。一个数据文件只能属于一个表空间,并且一个数据文件一旦加入某个表空间后,不能单独删除这个数据文件,只能删掉表空间才能将该数据文件删掉。
日志文件
日志文件就是记录表的变动,做了哪些操作等,记录了数据库所有的变化。后缀名.log。
控制文件(Control File):
- 控制文件是Oracle数据库的一个二进制文件,每个数据库至少需要一个控制文件,通常会有多个控制文件。控制文件记录了当前数据库的结构信息,包含数据文件及日志文件的信息以及相关的状态、归档信息等。
- 当数据库的物理结构发生改变时,例如增加、重命名、删除一个数据文件或者一个重做日志文件,Oracle服务器进程会立即更新控制文件以反映数据库结构的变化。
- 用户不能手工编辑控制文件,控制文件的修改由Oracle自动完成。
- 数据库的启动和正常运行都离不开控制文件,一定要备份控制文件,控制文件损坏将导致整个数据库损坏。
后缀名.ctl。
参数文件(Parameter File):
- 参数文件用于描述Oracle数据库的各种配置信息。它是在数据库实例启动时加载的,决定了数据库的物理结构、内存、数据库的限制以及系统最大量的默认值,以及数据库的各种物理属性,指定数据控制文件名和路径等信息,是进行数据库设计和性能调优的重要文件。
- 参数文件有两种类型:pfile和spfile。在oracle 9i以前的版本中,oracle一直采用pfile方式存储初始化参数,该文件称为文本文件。PFILE的修改必须重启实例才能生效。
后缀名.ora。
表空间
表空间是一个逻辑概念,它是由许多数据文件组成。正是因为它是一个逻辑概念,它对应的不是一片连续的存储空间。我们可以任意选择数据文件加入到这个表空间,所以表空间中的数据文件可能实际分布在各个不同的地方。在Oracle中,我们要创建什么东西都是创建在某个表空间下,我们只需要关注哪个表空间,不需要关注它实际的存储组成。
表空间还被分为了更细的逻辑存储单位,由大到小依次是段、区、数据块。这个道理跟省市县镇的道理一样,划分得越细越方便管理。我们创建的表就是存储在段里,所以一个表也可能包含多个区。
关于段,更细致的分类,见如下两图:


在Oracle中还有一个物理存储概念叫作磁盘块(os块),一个数据文件就是由多个磁盘块组成,我们只需要知道有这个概念就行了。
所以逻辑存储与物理存储之间的关系可见下图(物理结构包含数据文件、日志文件、控制文件、参数文件):

查看表空间:
SELECT * FROM dba_tablespaces;用户
目前了解到,一个Oracle服务器上可以有多个实例,一个实例下有多个表空间。刚刚提到创建的任何多西都在表空间中,那么用户自然也是创建一个表空间中,所以,一个表空间下可以有多个用户,当然,一个用户只属于一个表空间。其实Oracle中的用户相当于mysql中的数据库,我们要开发一个系统就会去创建对应一个用户,然后该用户下就去创建很多表。这些表的物理存储当然就是数据文件了,所以用户下创建的表或者视图等,当然都是在用户所属的表空间中。
查看有哪些用户:
SELECT * FROM ALL_USERS;用户有哪些权限:
SELECT * FROM DBA_SYS_PRIVS WHERE GRANTEE = 'LEO';Oracle还有一些内置用户:
1、SYS
SYS是Oracle中最高权限的超级用户,具有不受限制的访问和管理整个数据库的能力。以SYS用户登录需要使用SYSDBA或SYSOPER角色。SYS用户可以进行诸如创建和删除用户、表空间、数据库实例、备份和恢复等高级操作。由于SYS用户的权限十分强大,因此除非必须进行高级操作,否则应尽量避免使用SYS用户。
2、SYSTEM
SYSTEM用户是安装Oracle时自动创建的第二个用户,是SYS用户的辅助管理员,但是权限较低。SYSTEM用户可以进行数据库的创建、备份、恢复、性能优化、修改用户权限等操作。与SYS用户一样,SYSTEM用户也可以使用SYSDBA和SYSOPER角色登录。
3、SYSMAN
SYSMAN用户是Oracle Enterprise Manager的管理用户,用于管理和监视Oracle数据库、应用服务器和中间件等。SYSMAN用户具有越过其他Oracle用户权限的能力,因此在使用时需要谨慎。
4、DBSNMP
DBSNMP用户也是Oracle Enterprise Manager的管理用户,用于监测Oracle实例和数据库运行状态,以及提供相关的警报和报告。DBSNMP用户需要SYSMAN用户的授权才能访问Oracle数据库。
5、APPQOSSYS
APPQOSSYS用户用于Oracle 11g版本中的应用性能管理和查询优化器。APPQOSSYS用户的主要作用是为优化器提供性能和负载管理数据。
基本查询语句
查询Oracle版本:
SELECT * FROM V$VERSION;
配置文件
tnsnames.ora
LISTENER.ORA
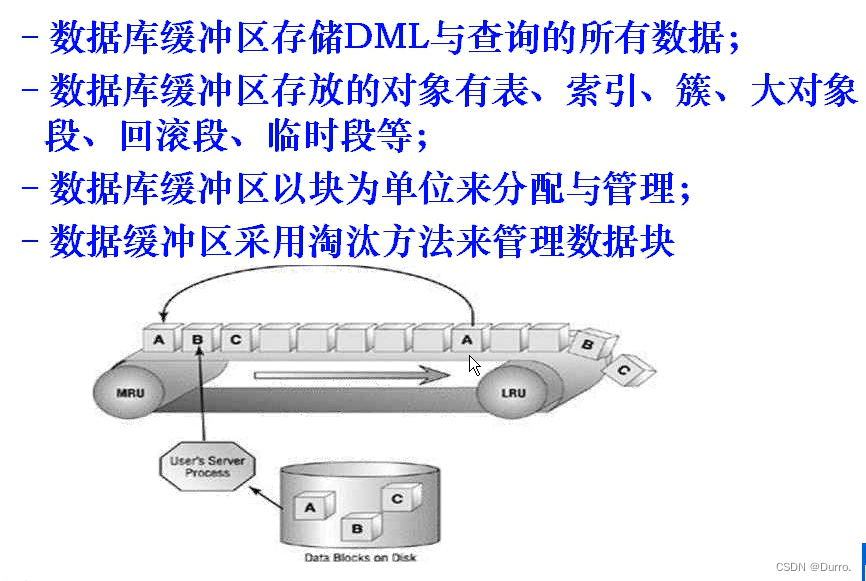
内存结构(SGA)
SGA是Oracle为实例分配的一组共享缓冲存储区,主要用于存放数据库数据和控制信息,该信息为数据库进程所共享(PGA不能共享的),以实现对数据库数据的管理和操作。
SGA=shared_pool_size(共享池大小)+db_block_size*db_block_buffers+log_buffers+java_pool+large_pool+fixed SGA
数据缓存区是构成SGA的一部分,它是以淘汰制管理数据块。数据块先进先出,如果有使用到哪个数据块,再“重新进入”,这样早期进入的又一直没用到的数据块就会被清理出去。
交易事务
Oracle执行DDL和DML必须使用commit进行提交,才能成功,没提交之前都不成功,提交后一起执行。也可以使用rollback进行回滚。
sql语句的执行过程
- 用户发出sql请求,打开游标;
- 把sql语句语法分析,执行计划,数据字典等信息存入内存中共享池内;
- 从数据文件中把相关数据块读入数据缓冲区;
- 做相应操作,若做修改,先加上行级锁,经确认后,把改过前后记录内容存入重做日志缓冲区内;
- 返回结果给用户,关闭游标。
多表查询
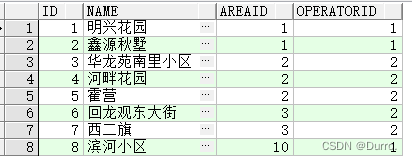
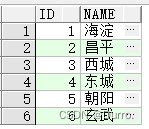
前提有T_ADDRESS表
T_AREA表
广义笛卡尔积
多表查询(连接)离不开传统的集合运算——广义笛卡尔积。广义笛卡尔积很简单,就是把 T_ADDRESS表的每一行与T_AREA表拼一遍,所以最后拼出来的表就是8*6=48行,4+2=6列
广义笛卡尔积sql查询:
SELECT * FROM LEO.T_ADDRESS A,LEO.T_AREA B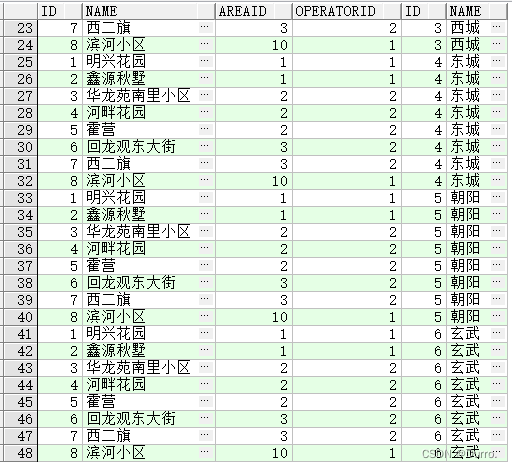
内连接
内连接又称等值连接,它所做的映射就是在广义笛卡尔积的基础上筛选出跟条件符合的行,再通过select语句映射我们想要的列。
例如下面的内连接查询是这样查出来的:
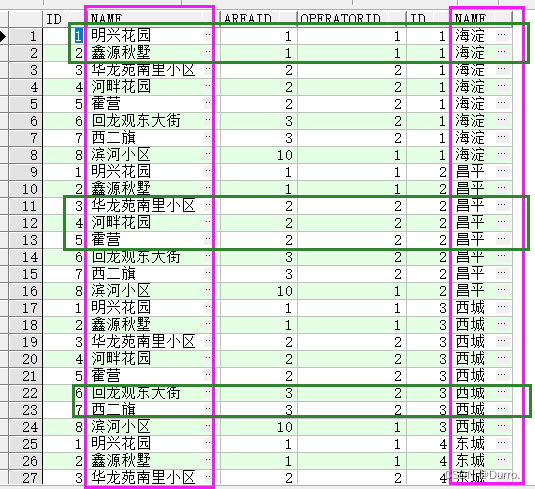
所以内连接的核心就是只返回符合条件的行。
内连接查询:
SELECT A.NAME,B.NAME FROM LEO.T_ADDRESS A INNER JOIN LEO.T_AREA B ON A.AREAID=B.ID或者不加INNER,默认就是内连接:
SELECT A.NAME,B.NAME FROM LEO.T_ADDRESS A JOIN LEO.T_AREA B ON A.AREAID=B.ID或
SELECT A.NAME,B.NAME FROM LEO.T_ADDRESS A,LEO.T_AREA B WHERE A.AREAID=B.ID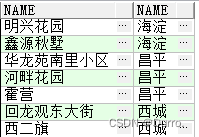
外连接
外连接是在内连接的基础上,再扩展一些行。因为外连接分为左外连接、右外连接和全外连接三种,所以扩展的行也是不同的。官方来说是:为了操作时能保存将被舍弃的元组,提出“外连接”操作。
左外连接
例如下面sql,left左边的T_ADDRESS就叫做主表,若主表在内连接完后还有没匹配到的行,也会显示出来,但是从表也就是另一张表没有与之对应的字段相匹配,那从表在这些行会用空顶上去
SELECT A.NAME,A.AREAID,B.NAME FROM LEO.T_ADDRESS A LEFT JOIN LEO.T_AREA B ON A.AREAID=B.ID以下写法是Oracle独有的左连接写法,在从表的匹配条件字段写上(+),就表示从表是需要添加空来补上来的
SELECT A.NAME,A.AREAID,B.NAME FROM LEO.T_ADDRESS A,LEO.T_AREA B WHERE A.AREAID=B.ID(+)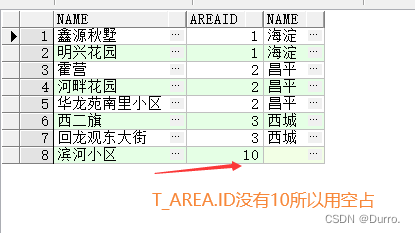
右外连接
右外连接也是一样的道理,在RIGHT的左边的表就不是主表啦,变成从表,另一张也就是B表就是主表,所以现在是A表的字段为空补上:
SELECT A.NAME,B.ID,B.NAME FROM LEO.T_ADDRESS A RIGHT JOIN LEO.T_AREA B ON A.AREAID=B.IDOracle右外连接的独有写法也是很好理解:
SELECT A.NAME,B.ID,B.NAME FROM LEO.T_ADDRESS A,LEO.T_AREA B WHERE A.AREAID(+)=B.ID
全外连接
那全外连接也很好理解,就是在内连接的基础,两张表没匹配上的行都要展示,这就导致两张表的字段都有空的情况出现
SELECT A.NAME,B.ID,B.NAME FROM LEO.T_ADDRESS A FULL JOIN LEO.T_AREA B ON A.AREAID=B.IDsql用法汇集
层次查询
层次查询有很多种用法,这里只简单介绍一个例子。
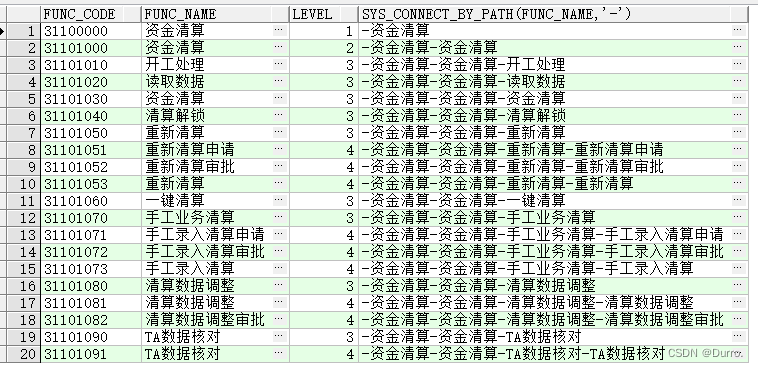
首先层次查询是为了查询具有树形结构的数据,如下面的菜单表:
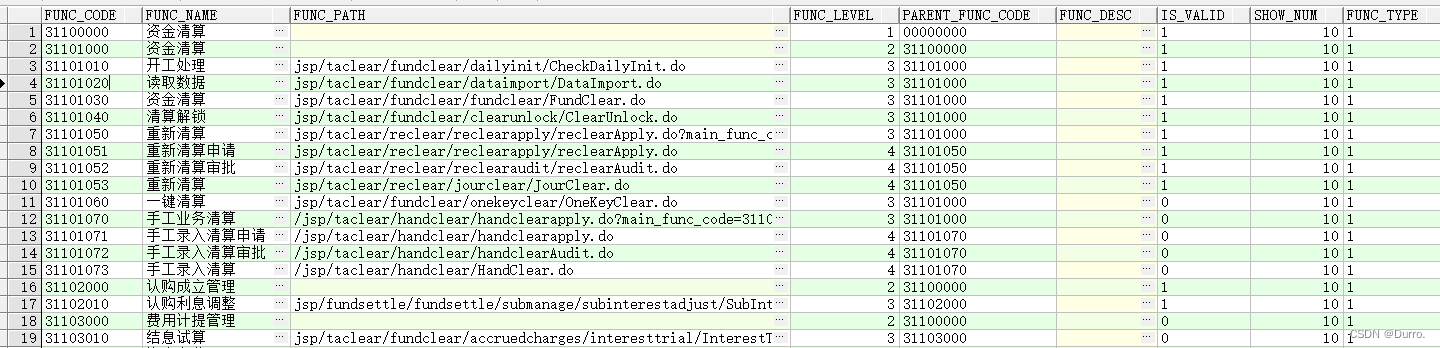
FUNC_CODE是菜单的id,FUNC_NAME是菜单名,PARENT_FUNC_CODE是该菜单的父级菜单。我们要使用层次查询是为了查询出来的数据是树状的,这样展示更加直观。在数据结构中,我们要想“表示一颗树”需要哪些条件?一是指明根节点,在该表中我应事先知道谁是最顶层的菜单,然后start with func_code='根菜单的id'即可表示根节点。二是指明父子之间的关系,在这里用func_code可以表示自己,parent_func_code可以表示父节点,所以可以这样表示:connect by prior func_code=parent_func_code。其中,层次查询还有一些伪列来帮助我们分析数据,比如sys_connect_by_path的作用就是标明从根节点到当前节点的路径。level则表示节点的层级,根节点为1。以上内容用sql完整表示如下:
select t.func_code, t.func_name, level, sys_connect_by_path(func_name, '-')
from es_system.func_def t
start with t.func_code = '31100000'
connect by prior t.func_code = t.parent_func_code;查询结果如下:
EXISTS和NOT EXISTS
exists就是存在的意思,下面有学生表、课程表、选课表来举例说明:
学生表Students:

课程表Courses:

选课表Enrollments:
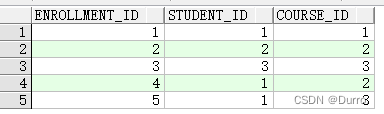
我要查找选修了英语的学生信息,可以这样写:
SELECT *
FROM LEO.Students S
WHERE EXISTS (SELECT *
FROM LEO.Enrollments
WHERE COURSE_ID = 2
AND STUDENT_ID = S.STUDENT_ID);查询结果:

EXISTS的特点就是先查外面的主表:
select * from LEO.Students S;
再查里面的子表:
SELECT * FROM LEO.Enrollments WHERE COURSE_ID = 2;
然后再根据主表与子表的连接关系 STUDENT_ID = S.STUDENT_ID,用主表的每一行去和子表每一行进行匹配,匹配成功就返回true,就会保留这行,匹配不成功就会删掉这行,最后返回最终的结果。
这里有人可能会问,如果不要主表与子表的连接关系 STUDENT_ID = S.STUDENT_ID,直接这样写可不可以呢?
SELECT *
FROM LEO.Students S
WHERE EXISTS (SELECT * FROM LEO.Enrollments WHERE COURSE_ID = 2);这样写的话查询出来就是学生表全部,因为主表代进子表没有连接关系,所以根本无法判断存不存在其中,所以自然就返回学生表全部。
还有人会问,有时会看到EXISTS的语句,子表里面会写成SELETE 1:
SELECT *
FROM LEO.Students S
WHERE EXISTS (SELECT 1
FROM LEO.Enrollments
WHERE COURSE_ID = 2
AND STUDENT_ID = S.STUDENT_ID);此时SELECT 1和SELETE *有什么区别呢?其实这样写最终查询出来的结果是一样的。EXISTS里的查询语句,不管查的什么,只要查出来有值,就是true,查不出来就是false。直接查1,只会显示一个1,效率比查*要更快。
所以EXISTS语句总的来说,就是判断主表的数据在子表中是否存在,存在就是返回true,不存在就返回false。
那NOT EXISTS的效果很简单,它其实和EXISTS一样,会把主表的数据一一去和子表匹配,匹配成功返回true,匹配没有返回false。这里要注意了,NOT EXISTS会把返回的true和false再取反。
现在我们看经典的题目,查找选修了所有课程的学生的姓名和年龄,首先我告诉你,可以这样写:
SELECT STUDENT_NAME, STUDENT_AGE
FROM LEO.Students S
WHERE NOT EXISTS (SELECT COURSE_ID
FROM LEO.Courses
MINUS
SELECT COURSE_ID
FROM LEO.Enrollments
WHERE STUDENT_ID=S.STUDENT_ID);首先我们看如何让这个主表能查询出数据来,也就是让where后面的条件成立。因为我们知道,NOT EXISTS会把结果取反,要想where条件成立,只能让NOT EXISTS里的语句为false。这里NOT EXISTS里面是进行了一个差集计算,要想为false,也就是差集结果得为null,null表示没有也就是false了。这里我们是用所有课程表去减去选课表中的课程,这里条件是学号,要想差集为null也就是得让选课表查出来的课程为全部课程,也就是说,哪个学生选修了全部课程,才能让此差集为null。这样,我们就找到了哪个学生选修了全部课程。
也可以这样写:
SELECT STUDENT_NAME, STUDENT_AGE
FROM LEO.Students S
WHERE NOT EXISTS (SELECT 1
FROM LEO.Courses C
WHERE NOT EXISTS (SELECT 1
FROM LEO.Enrollments
WHERE STUDENT_ID = S.STUDENT_ID
AND COURSE_ID = C.COURSE_ID));这是经典解法双重否定。这里我们还得想一个问题,上面有个例子换成NOT EXISTS执行会怎样:
SELECT *
FROM LEO.Students S
WHERE not EXISTS (SELECT *
FROM LEO.Enrollments
WHERE COURSE_ID = 2
and student_id = s.student_id);其实这里也会把主表的数据一行一行去和子表匹配,不过这里不同的是,反而匹配不上的会保留下来,因为匹配不上也就是false,会被NOT变为true,所以这个的查询结果就是:

我们再回到双重否定的这个解法上来,为什么中间套的是课程表?最里面可以看到,就是一个多表查询,查的是选课表。我们从最外面一开始穿了个学生id进来,这个条件定死了,然后课程表中每个课程id依次传进去看看能否匹配,如果匹配上了就说明该学生选了这门课。
很显然我们要让课程表这个not exists语句里面最终查询出来为false,必须要让所有匹配记录都为true,这意味着该学生选修了所有课程。这样false再与学生表的not exits匹配,就为true了,就可以查询出学生的信息。
那可不可以把not exists换成exists呢?毕竟正正也为正嘛。这是不行的,因为最里面,只要能匹配出一条,那也是true,我们要找的是选修了所有课程的学生,必须得匹配全部。
至于exists和in的区别,可以看这篇文章。















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









