







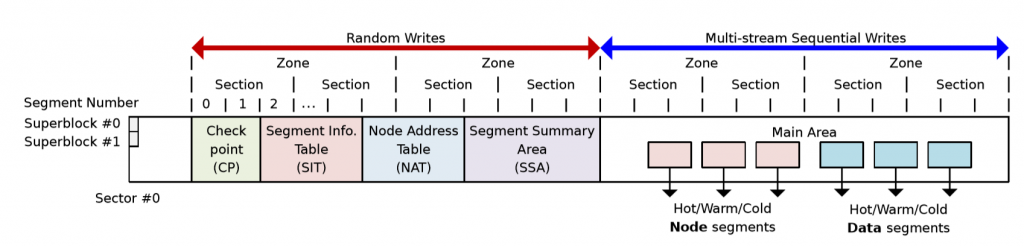
文件系统结构
F2FS将存储设备划分为6个区域,分别是:SuperBlock,CheakPoint,SegmentInformationTable,NodeAddressTable,SegmentSummaryArea,MainData.
数据存放单位
在理解各个元数据区域的基本功能之前,需要了解F2FS数据存放的不同大小的单位。在该文件系统中,数据一共有四个不同等级的存放单位:block,segment,section和zone,分别用于不同的功能粒度。
其中block是闪存中读写的最小粒度,所以最小的文件大小为4KB,元数据也是按照block的大小存放的。一个segment包含512个block,也就是2MB大小。一个segment是一个clean(也就是GC)的基本单位,所以从SuperBlock之后,数据都是按照segment对齐的。f2fs有6个打开的section用于存放MainArea数据,将数据按照数据类型与访问频率进行划分的。最大的数据单位是Zone,设置这个数据单位的目的是想要充分利用设备的并行性,达到六个sections能够并行处理的效果。
元数据
元数据保存文件系统的管理信息。以上六个区域中,前面五个都是元数据区域。其各个元数据区域的主要功能介绍如下:
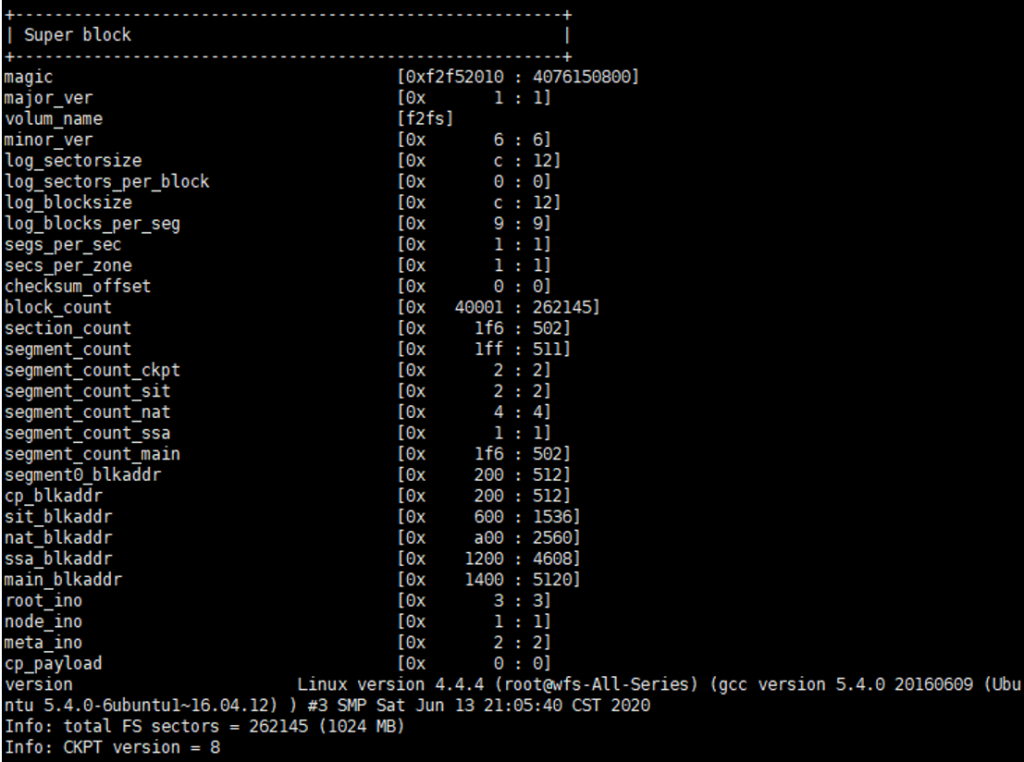
- SuperBlock:存储文件系统大小、6个区域起始地址、根节点等信息。文件系统一旦创建就不能更改。存放在设备的第一个和第二个block中。
- CheakPoint:CP保存文件系统的检查点信息,包括NAT_SIT bitmap,它表示NAT和SIT哪个副本是有效的。
- SegmentInformationTable:表示segment中block是否有效的信息。
- NodeAddressTable:存放inode和逻辑块地址的对应信息。inode是通过在块中的偏移量计算得到的,其具体的计算方法:。
- SegmentSummaryArea:存放文件所属关系和其偏移量,主要用于clean过程。
Super Block解析

F2FS源码中的super block结构。
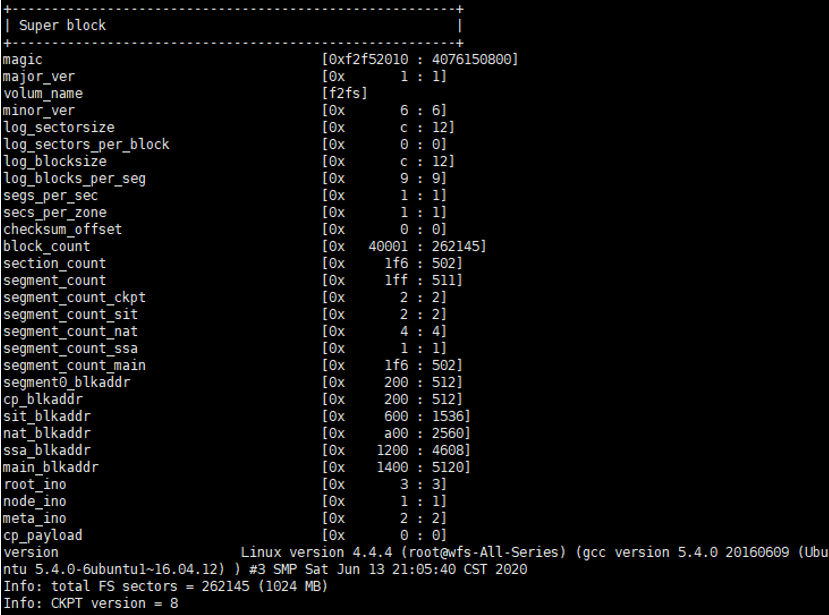
dump.f2fs -d 1 /dev/nvme0n1p1 打印出的文件系统元数据信息。
相关参数解释:
- magic:幻数,和文件系统类型以及该挂载序列相关,在操作系统中注册。
- cp_blkaddr:cheak point起始逻辑块地址。其他的sit_blkaddr同理。
- root_ino :根节点inode号。解析文件系统目录的时候,就是从root inode开始解析的。
Cheak Point解析

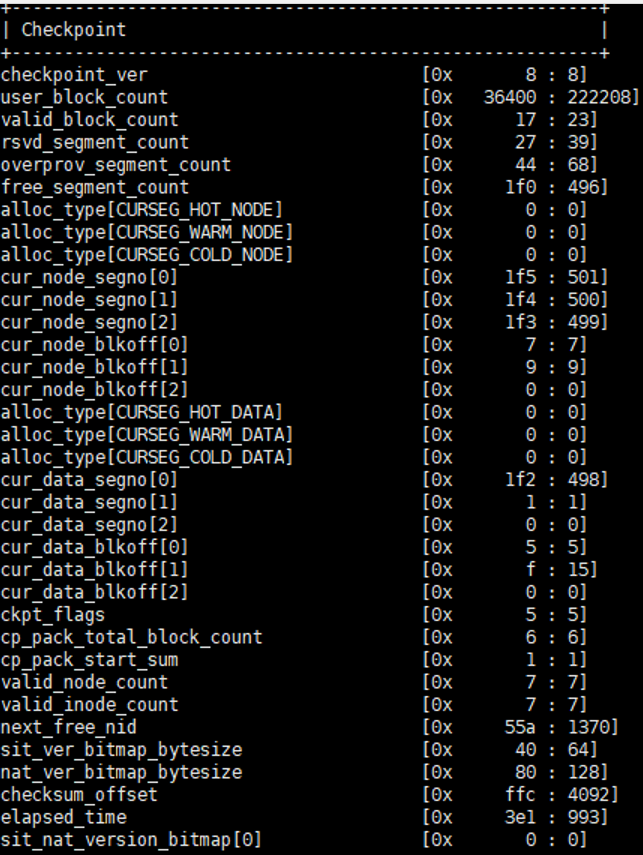
其中,sit_nat_version_bitmap是用来确定SIT 和NAT两个副本中的哪个副本有效的参数。
NAT的组织形式
NAT是作为文件的索引,避免了Wandering Tree的递归修改问题。Wandering Tree出现的原因是因为闪存的擦除问题和数据的增长问题导致数据的逻辑块地址发生变化需要更新,而叶节点的更新必然会导致其父节点的递归更新,导致整个索引结构的更新。而F2FS只需要更新叶节点和NAT。
NAT在源码中的结构:
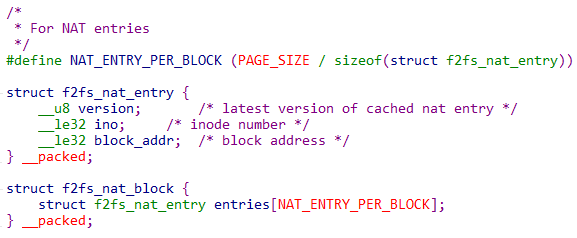
每个NATblock有4096/9 = 455个nat entry。其中每个entry包含version ,ino,block_addr三个参数。其中的ino 表示的是文件的inode number,而不是node id.node id是通过偏移量计算出来的,例如:从零开始第9个entry的node id是9,但是inode number却是8。从NAT中block读取出来的二进制数据如下图,可以看出来:

Segment Information Table
待补充。
Segment Summery Area
待补充。
Main Area
Main Area是用来存放inode信息和文件数据的。其中分为六个不同的数据部分:cold/warm/hot node和cold/warm/hot data。其中,node存放inode block,direct_node block和indirect_node block;inode block是文件第一个inode节点,存放文件的基本信息,在最后存放923个指向文件数据的逻辑块地址,5个间接索引node id。direct_node block存放1018个指向文件数据的逻辑块地址。indirect_node block存放1018个node id。一级间接索引存放直接索引node id,二级间接索引存放一级间接索引node id 。其中hot data存放的是entry data,保存文件的索引条目信息。
node 数据存放
inode block的数据存放格式如下图,按照这样的方式严格存放:

direct_node block:

F2FS源码中的 direct_node 结构定义

读出直接索引数据块的二进制数据。1018个索引项是放在最前面的,存放逻辑块地址,最后有24byte多余的数据。
indirect_node block:

F2FS源码中的 indirect_node结构定义

读出间接索引数据块的二进制数据。1018个索引项是放在最前面的,存放node id,最后有24byte多余的数据。
data 数据中,dentry(hot) 数据的存放
hot data保存的文件条目信息:
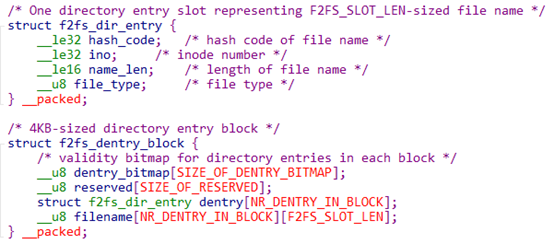
读取出来的entry block的二进制数据如下:

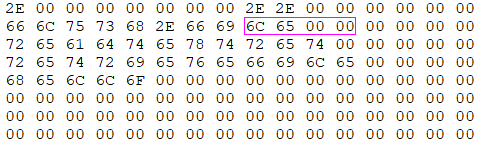
前面是对应的hash值,后面的对应的文件名;2e:. 2e2e:.. 666c7573682e66696c65:flush.file
内存中的目录结构
文件索引的组织形式:
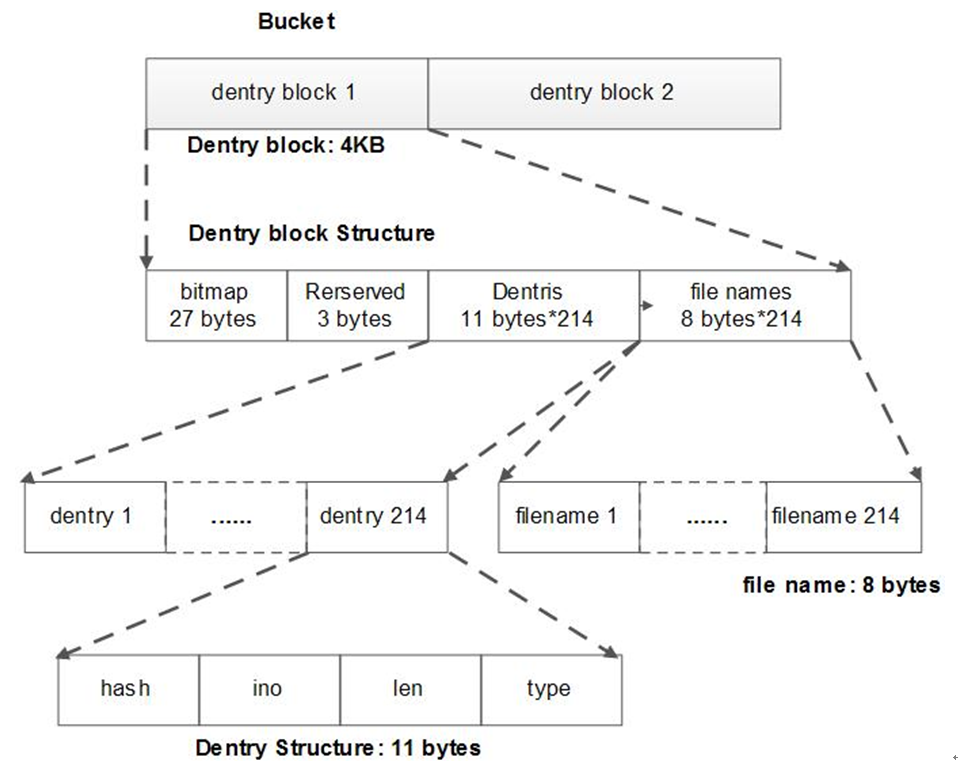
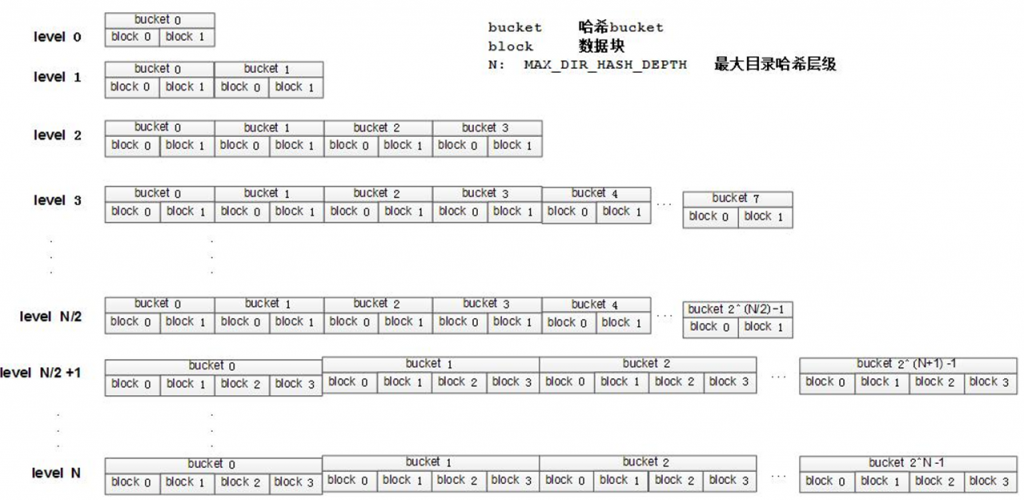

文件索引的存放方式:
文件在创建的时候,会为它分配一个dentry。首先计算其名字的hash值,从level 0开始, 无效的detry,则从下一个level查找。其查找的bucket的地址计算方式:
bucket number to scan in level #n = (hash value) % (# of buckets in level #)
文件索引的查找方式:
文件根据索引查找的时候,根据其存放的方式进行查找。在创建文件的情况下,F2FS 在哈希表的buckets 中找到该创建文件名对应的空的连续的槽位(slots)(这一句的原文是:F2FS finds empty consecutive slots that cover the file name)。F2FS 自哈希表的 level #0 到level #N 从哈希表中给搜索该空闲的槽位,与查找文件系统中已有文件的查找操作一样。
目录文件在main area中的物理组织:
目录文件按照上图中从上到下,从左到右的顺序依次作为数据存放。例如,dir2是一个目录,找到其inode block,其iaddr按顺序存放level 0:block0,block1;leve1 bucket0: block0,block1;leve1 bucket1: block0,block1;
在F2FS的源码中有一个参数:__u8 i_dir_level; /* dentry_level for large dir */。其在计算dentry block的偏移量的时候用到了。其目的就是在原来的dentry组织结构的基础上将每层的Bucket数增加,使该目录能够存更多的文件。
在硬盘上的文件读取过程(从Super Block开始)
1.得到Super Block,得到nat_blkaddr,cp_blkaddr和root_ino.
利用f2fs-tool的dump.f2fs -d 1 /dev/..指令可以得到元数据数据块信息,也可以直接利用nvme cli读闪存的逻辑块地址得到二进制文件自己进行解析。
2.得到想要查询的文件inode number之后,然后读取文件inode信息。
获取文件inode的方法有两种,一种是通过主机端的NFS和F2FS,利用指令:ls –i filename。另一种是在设备端实现,通过从根节点开始进行解析,得到filename以及对应的inode。根节点的iaddr中存放的是dentry数据,只需要解析dentry数据即可得到根节点中存放的数据。解析entry的过程上文有描述。
得到文件inode信息之后,通过NAT的偏移量找到对应的逻辑块地址。
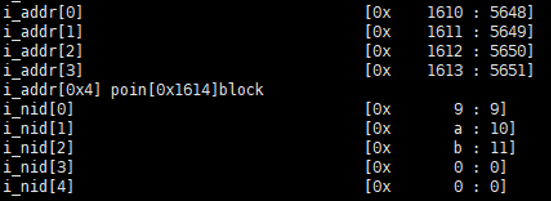
3.解析 inode block,得到相应数据块。inode block中有文件大小信息,i_size和i_block。根据这两个信息可以知道文件是怎么存放的。解析inode block的iaddr和inid,得到相应数据存放的逻辑块地址。例如:下图中有i_nid,i_nid[0]存放的nid为9。那么需要在NAT中得到偏移量为9的逻辑地址块,然后读取该块,得到保存文件的1018个逻辑块地址。而i_nid[2] = b,是二级间接索引,在NAT中得到逻辑块地址后保存的是一级间接索引的1018个逻辑块地址。最后能够解析出来文件的数据块。
















 1363
1363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









