







因为最近项目有关于大本文读取和指定行读取,读取第多少行到多少行记录,所以就从网上查询一些资料和自己的一些代码总结。
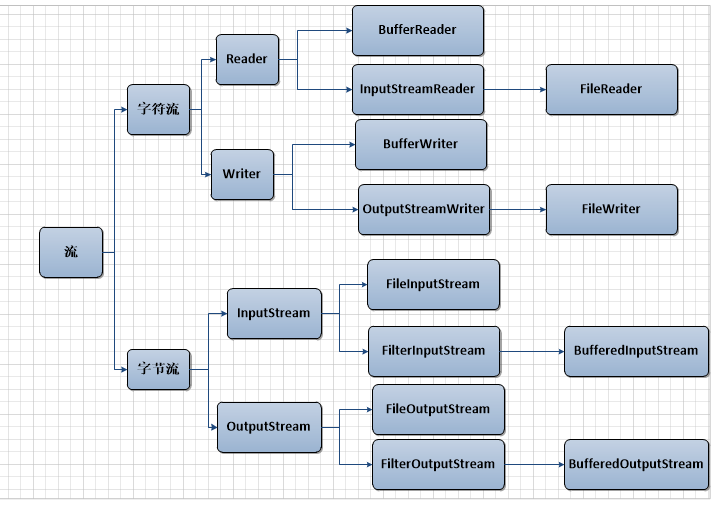
这里通过一个图简单介绍下java的IO流。
IO流分类
- 根据留得数据对象区分:
高端流:所有内存中的流都属于高端流,比如:InputStreamReader。
低端流:所有的外界设备中的流都属于低端流,比如InputStream。 根据数据的流向区分:
输出流:用来写数据的,由程序(内存)–>>外接设备。
输入流:用来读取数据的,由外界设备–>>程序(内存)。
区分:输入流带有Input,输出流带有Output。根据流数据的格式区分:
字节流:处理声音或者图片等二进制的数据的流,比如InputStream 。
字符流:处理文本数据(如txt文件)的流,比如InputStreamReader。根据流数据的包装过程来区分:
原始流:在实例化流的对象的过程中,不需要另外传入一个流作为自己构造方法的参数的流。
包装流:在实例化流的对象的过程中,需要传入另外一个流作为自己构造方法参数的流。
区分:所有的低端流都是原始流,所有的高端流都是包装流。IO流对象的继承关系图
关于更为细致的分类这里略过,下面简单介绍下几个案例。读取第100万之后的100条数据。
方法代码:
// 按照行号读取文本数据
public static String readByNum(int lineNumber) throws Exception {
String str = null;
FileReader fr = new FileReader(path);
LineNumberReader lr = new LineNumberReader(fr);
if (lineNumber < 0 || lineNumber > getTotalLines(new File(path))) {
log.debug("不在文件的行数范围之内。");
}
int i = 1;
long start = System.currentTimeMillis();
while((str=lr.readLine())!=null){
i++;
if(i>=1000000&&i<1000015){
log.debug(lr.readLine());
}
}
long end = System.currentTimeMillis();
fr.close();
lr.close();
log.debug("====方法readByNum(int lineNumber)耗时:"+(end-start)+"毫秒");
return str;
}
// 文件内容的总行数。
public static int getTotalLines(File file) throws IOException {
FileReader in = new FileReader(file);
LineNumberReader reader = new LineNumberReader(in);
String s = reader.readLine();
int lines = 0;
while (s != null) {
lines++;
s = reader.readLine();
}
reader.close();
in.close();
return lines;
}测试结果如下:因为数据太大,这里测试100w的后10条数据
2016-04-12 21:22:17.321 DEBUG [main][ReadbigTxt.java:53] - 0039892655~许水花
2016-04-12 21:22:17.323 DEBUG [main][ReadbigTxt.java:53] - 0036102712~应金兰
2016-04-12 21:22:17.323 DEBUG [main][ReadbigTxt.java:53] - 0031388582~景德镇市五金交电化工总公司供应站
2016-04-12 21:22:17.324 DEBUG [main][ReadbigTxt.java:53] - 0023055030~胡秀梅
2016-04-12 21:22:17.324 DEBUG [main][ReadbigTxt.java:53] - 0043752004~李吕华
2016-04-12 21:22:17.324 DEBUG [main][ReadbigTxt.java:53] - 0023914932~汪炳荣
2016-04-12 21:22:17.324 DEBUG [main][ReadbigTxt.java:53] - 0024564962~胡香凤
2016-04-12 21:22:17.324 DEBUG [main][ReadbigTxt.java:53] - 0048613725~史三女
2016-04-12 21:22:17.324 DEBUG [main][ReadbigTxt.java:53] - 0043763065~朱永有
2016-04-12 21:22:17.325 DEBUG [main][ReadbigTxt.java:53] - 0053238145~夏松林
2016-04-12 21:22:17.325 DEBUG [main][ReadbigTxt.java:53] - 0040854072~程林娇
2016-04-12 21:22:17.325 DEBUG [main][ReadbigTxt.java:53] - 0029429342~张荣玖
2016-04-12 21:22:17.325 DEBUG [main][ReadbigTxt.java:53] - 0048657929~董昌国
2016-04-12 21:22:17.325 DEBUG [main][ReadbigTxt.java:53] - 0021460884~周忠德
2016-04-12 21:22:17.326 DEBUG [main][ReadbigTxt.java:53] - 0036288939~陈伟涛
2016-04-12 21:22:17.570 DEBUG [main][ReadbigTxt.java:60] - ====方法readByNum(int lineNumber)耗时:256毫秒如果文本超过200M以上,需要使用缓存,每次读取10M放入缓存,操作之后再次读取。代码如下:
/**
* 读取txt文件的内容
* @param file 想要读取的文件对象
* 一次读取一行记录
* 每次读取5m数据放入缓存,读取5000行存入文本,然后继续读取
* @return 返回文件内容
* @throws Exception
*/
public static String txt2String(File file) throws Exception{
FileWriter fw = null;
String path = Utils.getProperty("connectPath2");
File f = new File(path);
if (!f.exists()) {
f.createNewFile();
}
//写到文本
FileOutputStream fos = new FileOutputStream(f);
OutputStreamWriter out = new OutputStreamWriter(fos, "UTF-8");
StringBuffer sb = new StringBuffer();
try{
FileInputStream in = new FileInputStream(file);
// 指定读取文件时以UTF-8的格式读取 如果文件超过2G可以改为10M缓存
BufferedReader br = new BufferedReader(new InputStreamReader(in,"UTF-8"),5*1024*1024); // 用5M的缓冲读取文本文件
//BufferedReader br = new BufferedReader(new FileReader(file));//构造一个BufferedReader类来读取文件
String s = null;
int count = 0;//计数器
while((s = br.readLine())!=null){//使用readLine方法,一次读一行
sb.append(s);
//sb.append(processConnect(s));//这个方法是我对读取数据的操作,这里略过直接sb.append(s);
if (count % 5000 == 0) {// 5000条数据写入一次
out.write(sb.toString());
sb.setLength(0);//清空
log.debug("====写入文本成功~");
}
count++;
}
out.close();
br.close();
}catch(Exception e){
e.printStackTrace();
}
return sb.toString();
}执行之后一个221M的文本读完并写入到了另一个文本之中。控制台输入如下:
2016-04-12 22:13:56.443 DEBUG [main][ReadTxt2SQL.java:32] - path=F:/OntologyData/tb_data/data.txt
2016-04-12 22:13:58.846 DEBUG [main][ReadTxt2SQL.java:107] - ====写入文本成功~
2016-04-12 22:13:58.846 DEBUG [main][ReadTxt2SQL.java:109] - ====方法txt2String(File file)耗时:2397毫秒
2016-04-12 22:13:58.847 DEBUG [main][ReadTxt2SQL.java:39] - ====整个文本的处理时间:[2455]毫秒
可能有人会对上面代码String path = Utils.getProperty("connectPath2");有疑惑,这其实就是读取文本的路径,我为了方便写了一个通用类,读取配置文件的内容,可以直接改为绝对路径。
可能有人会疑问,为什么我要读取5000条然后存入文本,继续读取然后在存,这样的因为数据量太大,我们内存空间不足会导致内存溢出,所以需要这样做。改为如下:
while((s = br.readLine())!=null){//使用readLine方法,一次读一行
sb.append(s);
//sb.append(processConnect(s));
/*if (count % 5000 == 0) {// 5000条数据写入一次
out.write(sb.toString());//写入文本
sb.setLength(0);//清空
//log.debug("====写入文本成功~");
}*/
count++;
}
out.write(sb.toString());//写入文本控制台打印:
2016-04-12 22:18:58.343 DEBUG [main][ReadTxt2SQL.java:32] - path=F:/OntologyData/tb_data/data.txt
2016-04-12 22:19:03.531 DEBUG [main][ReadTxt2SQL.java:109] - ====写入文本成功~
2016-04-12 22:19:03.531 DEBUG [main][ReadTxt2SQL.java:111] - ====方法txt2String(File file)耗时:4687毫秒
2016-04-12 22:19:03.661 DEBUG [main][ReadTxt2SQL.java:39] - ====整个文本的处理时间:[5411]毫秒
相对于第一种方法,这种效率低一些,现在我把读取内容每行都做处理//sb.append(test(s));
2016-04-12 22:24:53.187 DEBUG [main][ReadTxt2SQL.java:32] - path=F:/OntologyData/tb_data/data.txt
2016-04-12 22:24:56.134 DEBUG [main][ReadTxt2SQL.java:107] - ====写入文本成功~
2016-04-12 22:24:56.135 DEBUG [main][ReadTxt2SQL.java:109] - ====方法txt2String(File file)耗时:2927毫秒
2016-04-12 22:24:56.150 DEBUG [main][ReadTxt2SQL.java:39] - ====整个文本的处理时间:[3014]毫秒改为一次读完再存
2016-04-12 22:25:54.316 DEBUG [main][ReadTxt2SQL.java:32] - path=F:/OntologyData/tb_data/data.txt
2016-04-12 22:25:57.671 DEBUG [main][ReadTxt2SQL.java:108] - ====写入文本成功~
2016-04-12 22:25:57.672 DEBUG [main][ReadTxt2SQL.java:110] - ====方法txt2String(File file)耗时:3327毫秒
2016-04-12 22:25:57.764 DEBUG [main][ReadTxt2SQL.java:39] - ====整个文本的处理时间:[3499]毫秒这样看基本时间差距不大,今天先写到这里,等有时间我来测试2G数据,这两种方式的效率。















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









