






前言
任务是利用ocr,对多个不同格的表单进行处理,一定格式得到表格文字(不返回手写字符)。
经过一段时间的调研(折磨),有现成的接口,准确度高功能强。用的百度智能云提供的API,但是技术文档万年不更新,在使用的时候有些浪费时间,网上也没相关贴子,所以记录一下我的本次小小尝试,供大家学习参考。
OCR原理
OCR (Optical Character Recognition,光学字符识别)
典型的技术路线为:
需要图像处理、文本检测等技术,巨量的数据集,工作量巨大。故若无特殊需求,可以使用现有识别准确度较高的ocr接口,本次选用百度智能云。
百度云使用

使用高精度含位置检测时,会返回文字部分,以及文字所在位置信息,部分划分按照行,对于同一表格中分行的文字信息并没有进行整合。但是表格文字识别按照表头、主体、表尾三部分识别处理,对于表格中内容,以每一个小格为一个单位,对单位内信息进行整合处理。
表格文字识别的使用
- 得出识别结果
# encoding:utf-8
import requests
import base64
# 获取access_token
appid = "*******"#***需替换部分
client_id = "********************"
client_secret = "************************"
token_url = "https://aip.baidubce.com/oauth/2.0/token"
host = f"{token_url}?grant_type=client_credentials&client_id={client_id}&client_secret={client_secret}"
response = requests.get(host)
access_token = response.json().get("access_token")
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/form"
# 二进制方式打开图片文件 替换自己的文件路径
f = open("E:/OCR/t1.png", 'rb')
img = base64.b64encode(f.read())
params = {"image":img,
"body":"true",
"footer":"true",
"header":"true",
}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
注:需要替换access_token信息、文件路径
- 返回结果处理
得到结果之后,主要是对返回结果进行处理,最重要的是要弄清楚返回数据类型
如上:request.post调用返回的是response.models.Response类型;首先转换成dict类型
这部分官方技术文档没有进行细致描述,只能一点点做如下类似尝试:
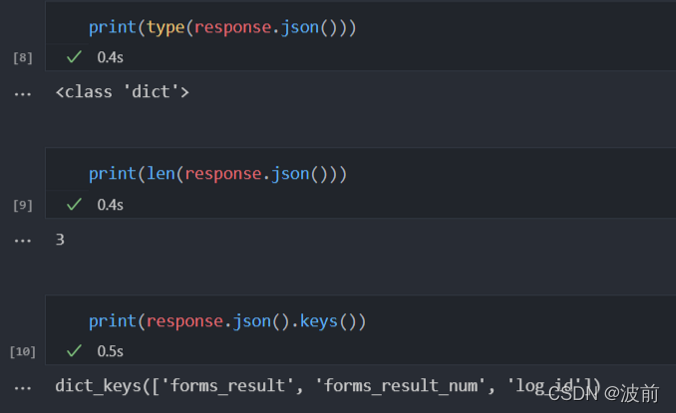
转换后的键为:
forms_result
forms_result_num
log_id
表格结果为forms_result对应的值,数据类型为list, 且长度为1,元素是dict类型,其中含有4个键,分别为:
vertexes_location :值为表格坐标,list类型,长度为4,对应4个顶点,dict类型,键为x,y
body :值为表格主体识别内容,list类型,列表长度为内容个数,列表元素为字典类型,
footer :值为表格尾部识别内容,list类型,同上
header :值为表头识别内容,list类型,同上
对于识别主体内容,body:每一个元素为dict类型,其中键为:
vertexes_location :同上层的vertexes_location,不过是每一小单元格位置信息
words : 对应为string类型,单元格内文本信息,回车也会检测到
row :行号
column :列号
结果输出
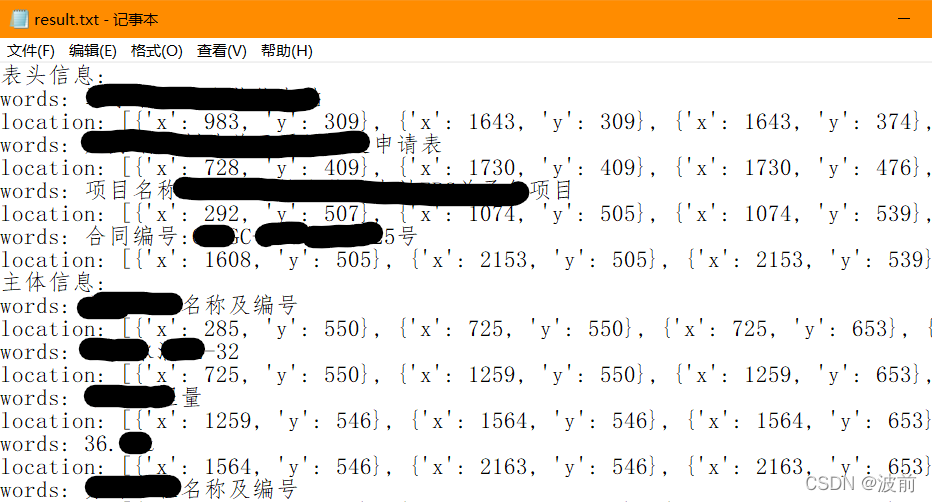
- 把自己所需要的结果,输出到了txt文件,包含表头、表中、表格主体的文本内容以及位置信息
"""
结果写入txt文件
参数数据类型为字典
keys(): 'vertexes_location','body','footer','header'
字典中的值 value均为 list类型
body 主体结果列表个数为识别结果个数,每一个元素均为dict元素,
包含vertexes_location words row column
"""
def ToTxt(fdic):
with open("result.txt",'w') as res:
res.write("表头信息:\n")
for i in range(0,len(fdic['header'])):
w_line = "words: "+ str(fdic['header'][i]['words']) + "\nlocation: " + str(fdic['header'][i]['vertexes_location']) + '\n'
res.write(w_line)
res.write("主体信息:\n")
for i in range(0,len(fdic['body'])):
w_line = "words: "+ str(fdic['body'][i]['words']).replace('\n',' ') + "\nlocation: " + str(fdic['body'][i]['vertexes_location']) + '\n'
res.write(w_line)
res.write("表尾信息:\n")
for i in range(0,len(fdic['footer'])):
w_line = "words: "+ str(fdic['footer'][i]['words']) + "\nlocation: " + str(fdic['footer'][i]['vertexes_location']) + '\n'
res.write(w_line)
结果输出:
小结
- 若要按照要求提取某表格内容,可以利用行、列号、或坐标等,进行数据筛选,得出所需表格内容
- 对于一类的表单,只需设计一次就可以进行批量处理
举个例子:
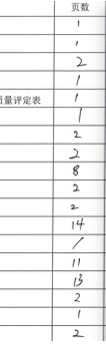
若要得到页数下的手写,先得到words为页数应的列号,再遍历结果中的相等的列号即可。
for i in range(0,len(response.json()['forms_result'][0]['body'])):
if response.json()['forms_result'][0]['body'][i]["words"] == "页数":
col = response.json()['forms_result'][0]['body'][i]["column"]
#print (col)
continue
if response.json()['forms_result'][0]['body'][i]["column"] ==6:
with open("页面.txt",'a') as f:
f.write(response.json()['forms_result'][0]['body'][i]["words"])
print(response.json()['forms_result'][0]['body'][i]["words"])

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









