




 本文介绍了一种基于LSTM的文本意图分类模型实现方法,详细解释了如何通过Python和TensorFlow构建模型,从数据预处理到模型训练全过程,并提供了一个实际的例子。
本文介绍了一种基于LSTM的文本意图分类模型实现方法,详细解释了如何通过Python和TensorFlow构建模型,从数据预处理到模型训练全过程,并提供了一个实际的例子。
基于LSTM(Long-Short Term Memory,长短时记忆人工神经网络,RNN的一种)搭建一个文本意图分类的深度学习模型(基于Python3和Tensorflow1.2),其结构图如下:
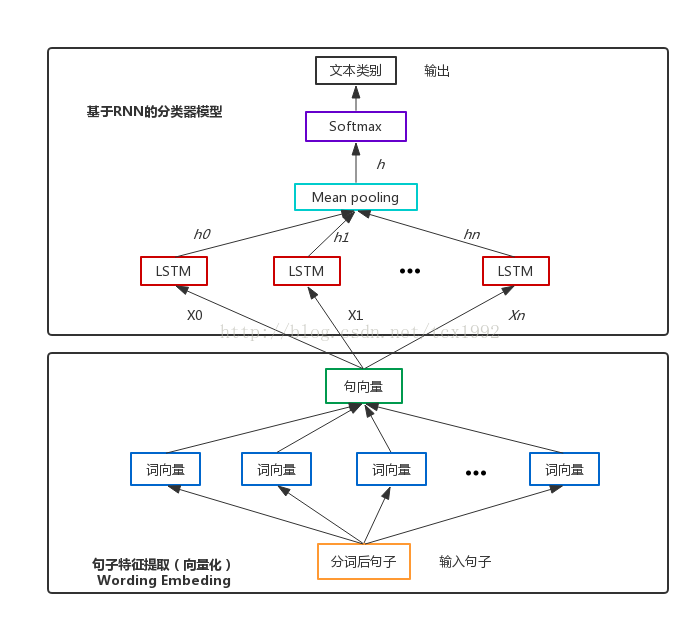
如图1所示,整个模型包括两部分
第一部分:句子特征提取
Step1 读取数据(这里是经过结巴分词后的句子),按比例划分训练集和验证集,这里每个句子都生成了相应的mask向量,用以标记每个输入文本的实际长度(在后期的模型中根据mask向量将padding为0部分所对应的隐藏层输出砍掉)。这里有几个可选项:
1. reverse: 考虑到句子中越靠后的词重要程度越高,因此可对句子进行逆序输入;
2. enhance: 样本数较小的时候可选择数据增强,即打乱句子顺序来构建新样本;
3. sort_by_len: 对句子按照长短进行排序
4. shuffle:打乱样本顺序,随机采样
import numpy as np
import sys
sys.path.append("..")
import random
# file path
# dataset_path = '/data/PycharmProjects/question_matching_framework/work_space/example/dataset/aaa'
def load_cn_data_from_files(classify_files):
count = len(classify_files)
x_text = []
y = []
for index in range(count):
classify_file = classify_files[index]
lines = list(open(classify_file, "r").readlines())
label = [0] * count
label[index] = 1
labels = [label for _ in lines]
if index == 0:
x_text = lines
y = labels
else:
x_text = x_text + lines
y = np.concatenate([y, labels])
x_text = [clean_str_cn(sent) for sent in x_text]
return [x_text, y]
def clean_str_cn(string):
"""
Tokenization/string cleaning for all datasets except for SST.
Original taken from https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py
"""
return string.strip().lower()
def load_data(classify_files, config, sort_by_len=True, enhance = True, reverse=True):
x_text, y = load_cn_data_from_files(classify_files)
new_text = []
if reverse == True:
for text in x_text:
text_list = text.strip().split(' ')
text_list.reverse()
reversed_text = ' '.join(text_list)
new_text.append(reversed_text)
x_text = new_text
else:
pass
y = list(y)
original_dataset = list(zip(x_text, y))
if enhance == True:
num_sample = len(original_dataset)
# shuffle
for i in range(num_sample):
text_list = original_dataset[i][0].split(' ')
random.shuffle(text_list)
text_shuffled = ' '.join(text_list)
label_shuffled = original_dataset[i][1]
x_text.append(text_shuffled)
y.append(label_shuffled)
else:
pass
# Randomly shuffle data
shuffle_indices = list(range(len(y)))
random.shuffle(shuffle_indices)
# print(shuffle_indices)
x_shuffled = []
y_shuffled_tmp = []
for shuffle_indice in shuffle_indices:
x_shuffled.append(x_text[shuffle_indice])
y_shuffled_tmp.append(y[shuffle_indice])
y_shuffled = np.array(y_shuffled_tmp)
# train_set length
n_samples = len(x_shuffled)
# shuffle and generate train and valid data set
sidx = np.random.permutation(n_samples)
n_train = int(np.round(n_samples * (1. - config.valid_portion)))
print("Train/Test split: {:d}/{:d}".format(n_train, (n_samples - n_train)))
valid_set_x = [x_shuffled[s] for s in sidx[n_train:]]
valid_set_y = [y_shuffled[s] for s in sidx[n_train:]]
train_set_x = [x_shuffled[s] for s in sidx[:n_train]]
train_set_y = [y_shuffled[s] for s in sidx[:n_train]]
train_set = (train_set_x, train_set_y)
valid_set = (valid_set_x, valid_set_y)
# test_set = (x_test, y_test)
# test_set_x, test_set_y = test_set
valid_set_x, valid_set_y = valid_set
train_set_x, train_set_y = train_set
def len_argsort(seq):
return sorted(range(len(seq)), key=lambda x: len(seq[x]))
if sort_by_len:
sorted_index = len_argsort(valid_set_x)
valid_set_x = [valid_set_x[i] for i in sorted_index]
valid_set_y = [valid_set_y[i] for i in sorted_index]
sorted_index = len_argsort(train_set_x)
train_set_x = [train_set_x[i] for i in sorted_index]
train_set_y = [train_set_y[i] for i in sorted_index]
train_set=(train_set_x,train_set_y)
valid_set=(valid_set_x,valid_set_y)
max_len = config.num_step
def generate_mask(data_set):
set_x = data_set[0]
mask_x = np.zeros([max_len, len(set_x)])
for i,x in enumerate(set_x):
x_list = x.split(' ')
if len(x_list) < max_len:
mask_x[0:len(x_list), i] = 1
else:
mask_x[:, i] = 1
new_set = (set_x, data_set[1], mask_x)
return new_set
train_set = generate_mask(train_set)
valid_set = generate_mask(valid_set)
train_data = (train_set[0], train_set[1], train_set[2])
valid_data = (valid_set[0], valid_set[1], valid_set[2])
return train_data, valid_data
# return batch data set
def batch_iter(data,batch_size, shuffle = True):
# get data set and label
x, y, mask_x = data
# mask_x = np.array(mask_x)
mask_x = np.asarray(mask_x).T.tolist()
data_size = len(x)
if shuffle:
shuffle_indices = list(range(data_size))
random.shuffle(shuffle_indices)
shuffled_x = []
shuffled_y = []
shuffled_mask_x = []
for shuffle_indice in shuffle_indices:
shuffled_x.append(x[shuffle_indice])
shuffled_y.append(y[shuffle_indice])
shuffled_mask_x.append(mask_x[shuffle_indice])
else:
shuffled_x = x
shuffled_y = y
shuffled_mask_x = mask_x
shuffled_mask_x = np.asarray(shuffled_mask_x).T # .tolist()
shuffled_x = np.array(shuffled_x)
shuffled_y = np.array(shuffled_y)
shuffled_mask_x = np.array(shuffled_mask_x)
# num_batches_per_epoch=int((data_size-1)/batch_size) + 1
num_batches_per_epoch = data_size // batch_size
for batch_index in range(num_batches_per_epoch):
start_index=batch_index*batch_size
end_index=min((batch_index+1)*batch_size,data_size)
return_x = shuffled_x[start_index:end_index]
return_y = shuffled_y[start_index:end_index]
return_mask_x = shuffled_mask_x[:,start_index:end_index]
yield (return_x,return_y,return_mask_x)
Step2 对输入到模型中的句子进行Word Embedding,将每个词表示成一个数值型的词向量。这个过程中对于不同长度的问题文本,pad和截断成一样长度的。太短的就补空格,太长的就截断。从而构建维数一致的模型句向量输入。(这里调用了别人训练好的词向量模型word2vec.bin)
x_embedded = wv.embedding_lookup(len(list(x)), config.num_step, config.embed_dim, list(x), 0)
第二部分:基于RNN的分类器模型
每个词经过embedding之后,进入LSTM层,这里用的是标准的LSTM,然后经过一个时间序列得到的n个隐藏LSTM神经单元的向量,这些向量经过mean pooling层之后,可以得到一个向量h,然后紧接着是一个Softmax层,得到一个类别分布概率向量,取概率值最大的类别作为最终预测结果。
import inspect
import tensorflow as tf
class RNN_Model(object):
def __init__(self, config, num_classes, is_training=True):
keep_prob = config.keep_prob
batch_size = config.batch_size
num_step = config.num_step
embed_dim = config.embed_dim
self.embedded_x = tf.placeholder(tf.float32, [None, num_step, embed_dim], name="embedded_chars")
self.target = tf.placeholder(tf.int64, [None, num_classes], name='target')
self.mask_x = tf.placeholder(tf.float32, [num_step, None], name="mask_x")
hidden_neural_size=config.hidden_neural_size
hidden_layer_num=config.hidden_layer_num
# build LSTM network
def lstm_cell():
if 'reuse' in inspect.signature(tf.contrib.rnn.BasicLSTMCell.__init__).parameters:
return tf.contrib.rnn.BasicLSTMCell(hidden_neural_size, forget_bias=0.0,
state_is_tuple=True,
reuse=tf.get_variable_scope().reuse)
else:
return tf.contrib.rnn.BasicLSTMCell(
hidden_neural_size, forget_bias=0.0, state_is_tuple=True)
attn_cell = lstm_cell
if is_training and keep_prob < 1:
def attn_cell():
return tf.contrib.rnn.DropoutWrapper(
lstm_cell(), output_keep_prob=config.keep_prob)
cell = tf.contrib.rnn.MultiRNNCell(
[attn_cell() for _ in range(hidden_layer_num)], state_is_tuple=True)
self._initial_state = cell.zero_state(batch_size, dtype=tf.float32)
inputs = self.embedded_x
if keep_prob < 1:
inputs = tf.nn.dropout(inputs, keep_prob)
out_put = []
state = self._initial_state
with tf.variable_scope("LSTM_layer"):
for time_step in range(num_step):
if time_step > 0: tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step,:],state)
out_put.append(cell_output)
out_put=out_put*self.mask_x[:,:,None]
with tf.name_scope("mean_pooling_layer"):
out_put = tf.reduce_sum(out_put,0)/(tf.reduce_sum(self.mask_x,0)[:,None])
with tf.name_scope("Softmax_layer_and_output"):
softmax_w = tf.get_variable("softmax_w",[hidden_neural_size,num_classes],dtype=tf.float32)
softmax_b = tf.get_variable("softmax_b",[num_classes],dtype=tf.float32)
# self.logits = tf.matmul(out_put,softmax_w)
# self.scores = tf.add(self.logits, softmax_b, name='scores')
self.scores = tf.nn.xw_plus_b(out_put, softmax_w, softmax_b, name="scores")
with tf.name_scope("loss"):
self.loss = tf.nn.softmax_cross_entropy_with_logits(labels=self.target, logits=self.scores + 1e-10)
self.cost = tf.reduce_mean(self.loss)
with tf.name_scope("accuracy"):
self.prediction = tf.argmax(self.scores, 1, name="prediction")
correct_prediction = tf.equal(self.prediction, tf.argmax(self.target, 1))
self.correct_num = tf.reduce_sum(tf.cast(correct_prediction, tf.float32))
self.accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name="accuracy")
self.probability = tf.nn.softmax(self.scores, name="probability")
# add summary
loss_summary = tf.summary.scalar("loss", self.cost)
# add summary
accuracy_summary = tf.summary.scalar("accuracy_summary", self.accuracy)
if not is_training:
return
self.global_step = tf.Variable(0, name="global_step", trainable=False)
self.lr = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars), config.max_grad_norm)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in zip(grads, tvars):
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
self.grad_summaries_merged = tf.summary.merge(grad_summaries)
self.summary = tf.summary.merge([loss_summary,accuracy_summary,self.grad_summaries_merged])
optimizer = tf.train.GradientDescentOptimizer(self.lr)
optimizer.apply_gradients(zip(grads, tvars))
self.train_op=optimizer.apply_gradients(zip(grads, tvars))
self.new_lr = tf.placeholder(tf.float32,shape=[],name="new_learning_rate")
self._lr_update = tf.assign(self.lr,self.new_lr)
def assign_new_lr(self,session,lr_value):
session.run(self._lr_update,feed_dict={self.new_lr:lr_value})
举例(QA中的问题意图分类):
输入:你好 呀
意图类别:greeting
具体代码参见代码


















 3622
3622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









