







一、前言
本系列第一篇我们讲过查询优化,MySQL引擎总是试图找到一个最优的查询路径,这其中包含了大量的算法,今天我们来重点讨论join和排序算法,主要内容如下:
1、join操作有哪几种优化算法,如何选择?
2、排序算法有哪些?每种算法的使用场景是什么?
3、排序优化注意点有哪些?
二、join算法
join操作就是将两张以上的表进行连接查询,根据连接模式,分为左连接,右连接,内连接。join算法的基础是笛卡尔积,即A表中每个记录都与B表中记录一一连接,A表有M条数据,B表有N条数据,那么笛卡尔积之后有M*N条,如下图所示。

1、Simple Nested Loop Join(SNLJ)
实现笛卡尔积,最简单也是最先能想到的是就是嵌套循环。例如有用户和订单两张表。
select * from User u join Order o on u.U_Id=o.U_Id。

伪代码如下:
for each row1 in user
for each row2 in order
if row1.U_Id == row2.U_Id
join row1 and row2 into resultUser是外层表,称之为驱动表,Order是内层表,称之为被驱动表。
这种算法通过两层嵌套循环,先获取User表的每行数据,逐一与Order表行记录进行比较,如果条件符合,则加入结果集。
该算法简单粗暴,如果每个表有1W条记录,那么就要比较1W*1W=1亿次,显然效率低下,事实上,MySQL在实际运算过程中,也没有使用该算法,而是采用以下两种优化算法。
2、Index Nested Loop
Index Nested Loop的思路是减少内层表数据的匹配次数,由内层表的每行记录比较,优化为内存的索引的高度,还以上面的用户表和订单表查询为例。

此时,查询的次数为User外层表记录数*Order的U_Id的B+数深度,Index Nested Loop的前提是匹配的字段必须要建立索引。需要注意的是,如果匹配的字段索引不是内层表的主键索引(类似例子中的U_Id),那么还需要回表查询;如果是主键,那么效率会更高。
3、Block Nested Loop
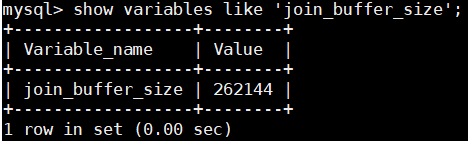
如果匹配的字段没有建立索引,那么采用block nested loop也可以提高查询效率。其原理是将外层表的join列(包括select列)缓存到join buffer,在用join buffer批量与内层表数据进行匹配,将多次比较合成一次,从而减少内循环的次数。通过join_buffer_size参数可设置join buffer的大小。
还以上面的例子:

4、贪心算法
在多表(两个以上)的连接情况下,每两个表连接是有代价值的,MySQL会根据不同的代价值,调整各表的连接顺序,最后算出一条最优或者近似最优解。MySQL采用的贪心算法,如图所示。

贪心算法的前提是确定一个源点,然后找出每一步的最优解,如图所示,以A为源点,G为终点,贪心算法找出的最优解为A->B->D->G,实际上的最优解是A->C->F->G,所以贪心算法给出的是局部最优解,但该算法的复杂度较低,效率高,在连接表数较大的情况下,具有一定的优势。
实际上,多表连接就是无源的的最短路径问题,MySQL由于算法需要,随机选了一个源而已,这也导致最终结果的不精确。在这点上,Postgresql采用的是动态规划的思想,最终的执行计划会更精确,但是算法也会更复杂。
三、排序
对于排序,我们首先想到利用B+树索引实现排序的优化查询,因为B+树天然是有序的。在本系列的第一篇中我们重点研究了索引排序优化,但是索引排序是有条件的,很多情况下还是使用文件排序。下面我们重点研究下文件排序的算法。
1、回表排序(双路排序)
我们还以第一篇的表为例:
CREATE TABLE `test_4` (
`test_4_a` int(11) DEFAULT NULL,
`test_4_b` varchar(45) DEFAULT NULL,
`test_4_c` varchar(45) DEFAULT NULL,
`test_4_d` varchar(45) DEFAULT NULL,
UNIQUE KEY `test_4_a_UNIQUE` (`test_4_a`),
KEY `test_4_b_c` (`test_4_b`,`test_4_c`)
)排序语句:
select * from test_4 t order by t.test_4_d asc;根据test_4_d字段进行升序排序,并返回所有的字段值。那么在回表排序模式下:
- 根据索引或者全表扫描 ,按照过滤条件获得需要查询的排序字段值和row ID;
- 按照排序字段和row ID组成键值对<sort_key,rowid>,存入sort buffer中;
- 如果sort buffer内存大于这些键值对的内存,就无需创建临时文件保存了;否则,每次sort buffer填满后,采用快排对内存的数据进行排序,再写到临时文件;
- 重复以上步骤,直到所有的数据都已读取,并进行了处理;
- 如果用到了临时文件,则利用磁盘外部排序(第4小结我们将详细介绍),将rowid写入到结果文件;
- 根据结果文件中的rowid,再次回表查询所需要的字段,最终返回给用户。
由于在第6步进行了回表,所以称之为回表排序。其中在sort buffer中的排序示意如下:

2、不回表排序(单路排序)
由于回表排序,涉及到两次回表查询,特别是最后一次,是随机查询(如果不进行rowid排序),效率低下。针对以上问题,不回表排序将排序字段与需要返回的字段组成键值对,在上面例子上,<test_4_d,test_4_a,test_4_b,test_4_c>。
- 根据索引或者全表扫描 ,按照过滤条件获得需要查询的排序字段值和需要返回的字段。
- 将排序的字段与待返回的字段组成键值对,存入sort buffer中。
- 如果sort buffer内存大于这些键值对的内存,就无需创建临时文件保存了;否则,每次sort buffer填满后,采用快排对内存的数据进行排序,再写到临时文件;
- 重复以上步骤,直到所有的数据都已读取,并进行了处理;
- 如果用到了临时文件,则利用磁盘外部排序,将排序后的数据写入到结果文件;
- 直接从结果文件中返回用户需要的字段数据。
由于第6步直接返回结果,无需回表查询,所以称之为不回表排序。 其中sort buffer的排序示意如下:

不回表排序采用的是以空间换时间的策略,但是sort buffer不可能无限大,如果用户要查询的数据非常大的话,那么就会保存很多临时文件,后续将浪费很多时间在磁盘外部排序上,导致更多的IO操作,效率可能还不如第一种方式。MySQL提供了一个max_length_for_sort_data参数,当单行键值对的大小>max_length_for_sort_data时,MySQL认为磁盘外部排序的IO效率不如回表的效率,会选择第一种排序模式;反之,会选择第二种不回表的模式。
3、优先队列排序(堆排序)
排序进行和分页组合一起,比如,order by test_4_d limit N,M。对于这种排序,最开始能想到的算法,先将所有的记录进行快排序,然后选择从N到N+M的记录,这种算法空间占用较大,试想如果是1千万条记录,查找从第1条到第10条数据,那么先要排序并记录这1千万条记录的结果。
针对该问题,MySQL在空间层面做了优化,实现了一种新的排序方式,称之为 优先队列排序,由于是采用堆排序实现,也称之为堆排序。堆排序仅需要N+M个元素的sort buffer即可,对于升序,采用大顶堆,最终堆中的元素组成了最小的M个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的M的元素。
我们使用order by test_4_d asc limit 0,5为例,初始化节点为5的大顶堆,当插入(d2,2)后,会引起整个堆的调整,使之重新满足大顶堆结构。依次循环,直到所有的记录扫描完成后,输入5条记录,返回客户端即可。

需要注意的是,并不是所有的分页都采用堆排序,比如对于1百万条数据,limit 990000,10,此时的空间并没有优化多少,而且堆排序的速度慢于快排,MySQL会选择快排。
4、磁盘外排序
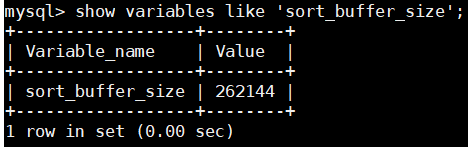
对于前面的几类排序,当数据大于sort buffer size设置的内存,那么将被写入临时文件。该值可配置:
当所有的待排序的行记录扫描完成后,就形成了多个有序的临时文件(实际上是一个文件,采用偏移量分割表示),再将这些有序的临时文件排序合并成一个有序文件,就能完成全局排序,这种多个有序文件合并一个文件很适合归并排序算法。
先看下归并排序算法原理视图如下:

MySQL在内存排序时,当写满sort buffer size内存后,就作为一个block放入到临时文件,所以初始时,一个block就认为是排序好的sort buffer size的大小的文件。其排序过程如下:
第一次循环中,一个block对应一个sort buffer(大小为sort_buffer_size)排序好的数据;每7个做一个归并。
第二次循环中,一个block对应MERGEBUFF (7) 个sort buffer的数据,每7个做一个归并。
… 直到所有的block数量小于MERGEBUFF2 (15),做最后一次归并,完成整个排序过程。
5、排序优化小结
理解了相关的算法原理,下面我们总结下在实践过程中如何优化排序:
1、尽量使用索引排序,避免文件排序。
2、增加sort_buffer_size大小,避免磁盘排序。
3、排序和查询的字段尽量少。只查询你用到的字段,不要使用select *;
4、使用Limit查询必要的行数据;
5、要排序和查询的字段,尽量不要用不确定的字符函数,否则直接分配max_sort_length,导致sort buffer空间不足。
四、总结
回答本篇开头的几个问题作为今天的总结
Q:join操作有哪几种优化算法,如何选择?
A:join算法的基础是笛卡尔积,采用嵌套循环,外层的每条记录与内层的所有记录进行比较,符合条件,写入结果集,称之为SNL。在此基础上,MySQL实现了两种优化算法,分别为INL与BNL。INL是通过对连接字段建立索引,由之前的扫描所有内层记录,优化为扫描连接字段索引,从而减少内循环的次数。BNL是通过join buffer,将多条记录合成一次进行匹配,从而减少循环次数。
如果连接字段建立了索引,优先选用INL,否则选用BNL。
Q:排序算法有哪些?每种算法的使用场景是什么?
A:按是否回表分类,分为回表排序和不回表排序;按是否需要外部临时文件排序,分为内存排序和外部排序。
对于分页排序,采用堆排序算法,提升空间的利用率。
Q:排序优化注意点有哪些?
A:参考第三章节第5小结,优先使用索引排序,然后内存排序,最后再外部排序;查询必要的字段,不要使用select * 。
附:















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









