






LightRAG实践详解
部署
LightRAG容器部署
docker build -f ./DockerfileLight -t lightrag .
| "http://hub.staronearth.win/" |
systemctl daemon-reload
systemctl restart docker
tiktoken离线缓存部署参考:
https://github.com/songquanpeng/one-api/issues/680
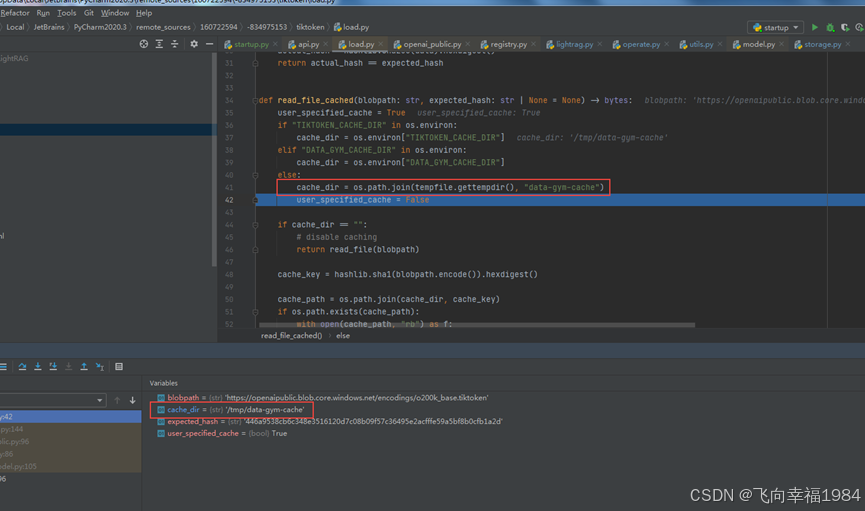
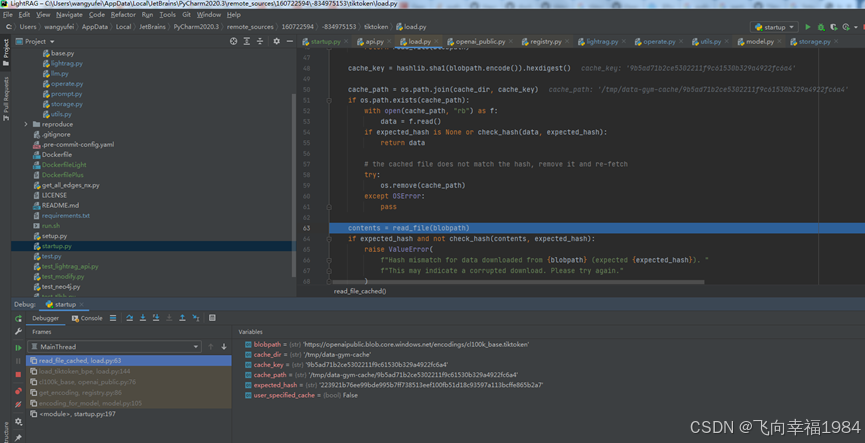
现在服务器网络确实连不上tiktoken的官网
TIKTOKEN_CACHE_DIR=/home/data/LightRAG/data-gym-cache
docker build -f ./DockerfilePlus -t lightrag .
docker commit ebe3c2b38e45 lightrag
docker export c7f102518891 > lightrag.tar
docker run -it -d -p 8020:8020 -e FASTCHAT_WORKER_API_TIMEOUT=600 -e TIKTOKEN_CACHE_DIR=/home/data/LightRAG/data-gym-cache --restart=always -v "/home/data/LightRAG:/home/data/LightRAG" -v /etc/localtime:/etc/localtime:ro lightrag
分析
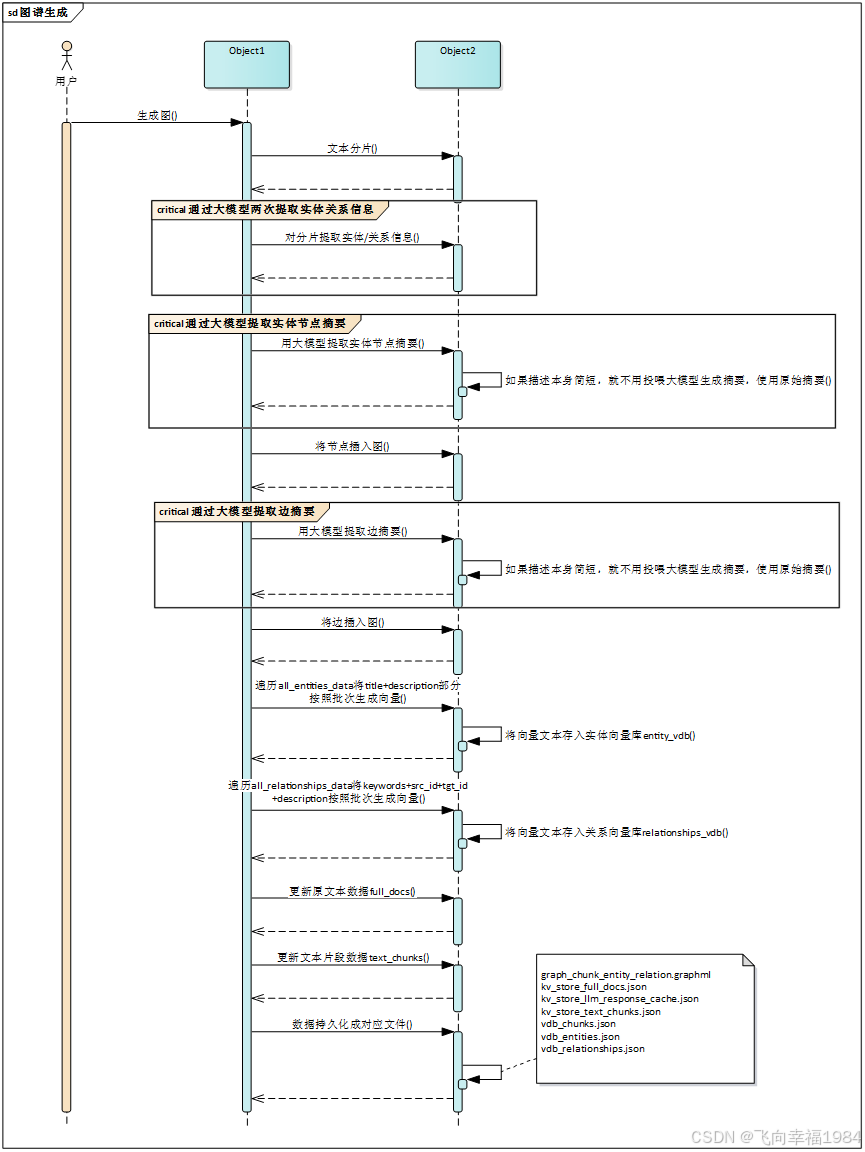
图谱生成
lightrag/lightrag.py
insert -> ainsert
ainsert -> chunking_by_token_size
文本分片
ainsert -> upsert
a) 对每个文本片段生成embedding
b) 将embedding存入list_data
c) list_data存入向量库文件
ainsert -> extract_entities
lightrag/prompt.py
extract_entities -> _process_single_content -> llm_model_func -> openai_complete_if_cache
提取实体/关系信息 (有大模型hash缓存)
a) 通过分片投喂大模型,拿到实体/关系信息,整合存放在maybe_nodes / manybe_edges
lightrag/storage.py
NetworkXStorage存放图结构(networkx)
extract_entities -> _merge_nodes_then_upsert -> _handle_entity_relation_summary
用大模型提取实体节点摘要
a)如果描述本身简短,就不用投喂大模型生成摘要,使用原始摘要
b)如果描述很长,就让大模型生成摘要返回
_merge_nodes_then_upsert -> upsert_node
将node_data插入图
extract_entities -> _merge_edges_then_upsert -> _handle_entity_relation_summary
用大模型提取边摘要
_merge_edges_then_upsert -> upsert_edge
将边插入图
extract_entities -> entity_vdb.upsert
a) 将title+description部分按照批次生成向量
b) 将向量组装到list_data中
c) 将list_data插入向量库
extract_entities -> relationships_vdb.upsert
a) 将keywords+src_id+tgt_id+description按照批次生成向量
b) 将向量组装到list_data中
c) 将list_data插入向量库
ainsert -> full_docs.upsert
更新原文本数据
ainsert -> text_chunks.upsert
更新文本片段数据
ainsert -> _insert_done
数据持久化成对应文件
原生搜索
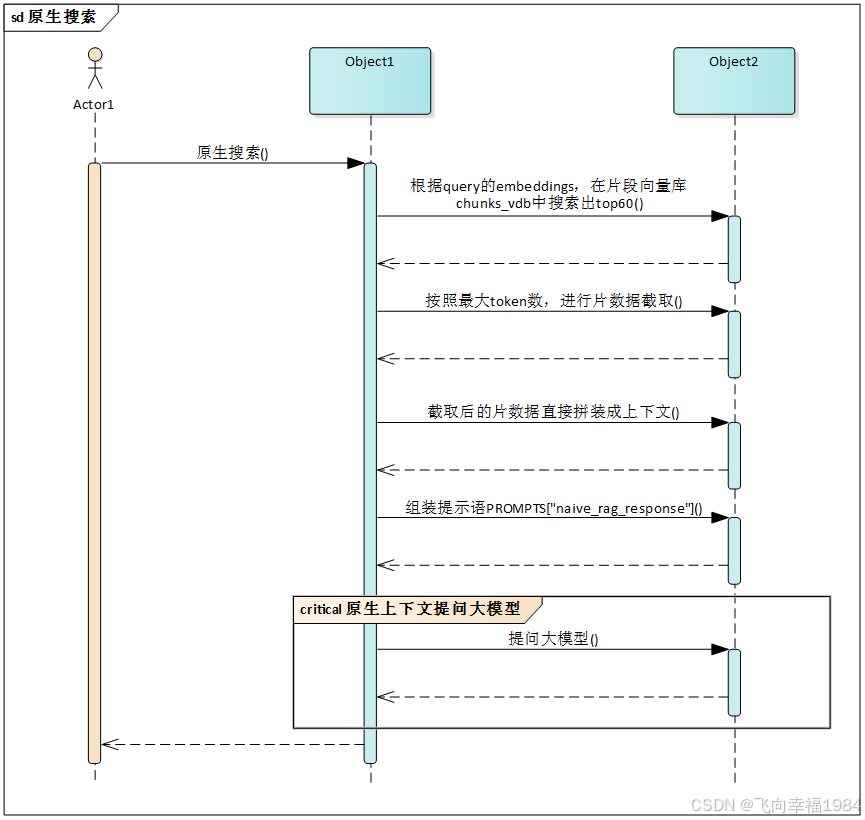
query -> aquery -> naive_query
naive_query -> chunks_vdb.query
a) 根据query的embeddings,搜索出top60,cosine_better_than_threshold = 0.2
b) 获取到文本片id列表chunks_ids
c) 按照最大token数,进行片数据截取
d) 截取后的片数据直接拼装成上下文
e) 组装提示语PROMPTS["naive_rag_response"]
naive_query -> use_model_func
提问大模型
aquery -> _query_done
将kv_store_llm_response_cache.json持久化
本地搜索
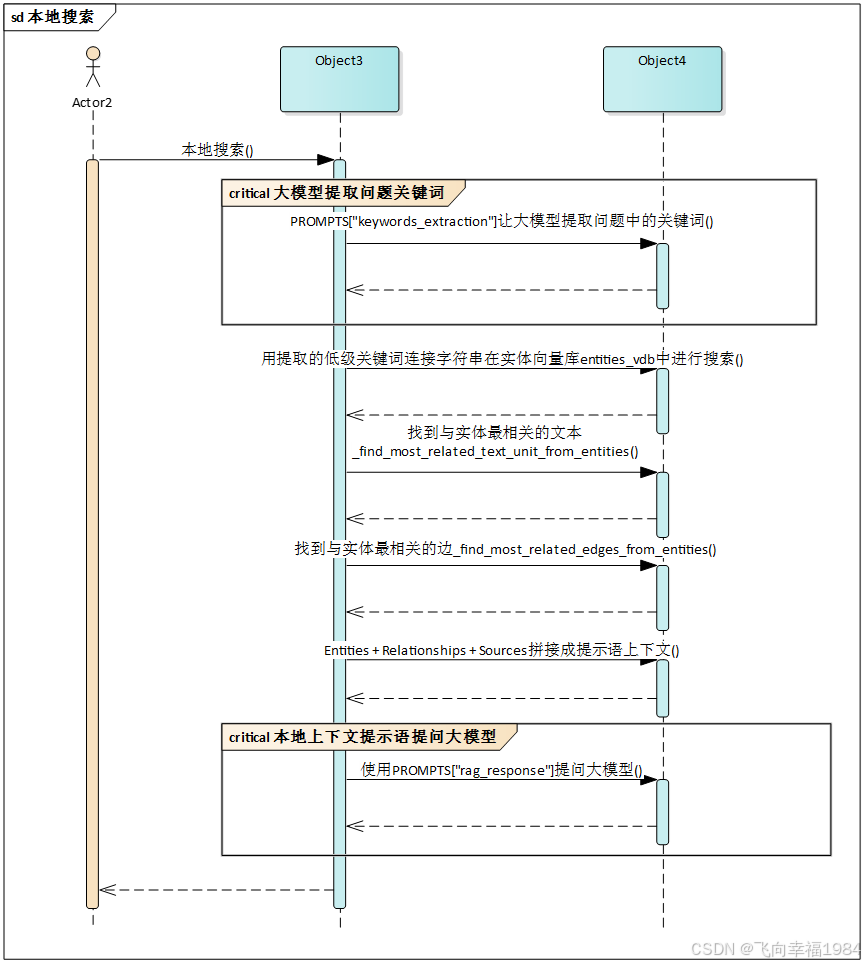
aquery -> local_query -> use_model_func
a) PROMPTS["keywords_extraction"]让大模型提取问题中的关键词
local_query ->_build_local_query_context
-> entities_vdb.query
a) 用提取的关键词在实体向量库中进行搜索
b) 根据搜索出的实体名从图中获取节点信息到node_datas
c) 获取节点的度node_degrees
d) 组装实体名+节点度到新的 node_datas
_build_local_query_context -> _find_most_related_text_unit_from_entities
a) 获取片段id列表
b) 根据实体名从图中获取边信息
c) 遍历边信息组成all_one_hop_nodes
d) 根据nodes id 从图中获取节点信息到all_one_hop_nodes_data
e) 构造实体名查询片段集合的结构体all_one_hop_text_units_lookup
f) 构造片段有多少关系实体的结构all_text_units_lookup,进一步过滤空结构,生成all_text_units
g) 按照order升序,relation_counts降序重新排列all_text_units
h) 按照max_token_size(4000)截取all_text_units , 存入 use_text_units
_build_local_query_context -> _find_most_related_edges_from_entities
a) 根据实体名从图中获取相关节点&边信息
b) 根据边信息获取排序后的边集合all_edges
c) 根据all_edges从图中获取所有边信息到all_edges_pack
d) 根据all_edges从图中获取度信息到all_edges_degree
e) all_edges_data组装all_edges, all_edges_pack, all_edges_degree, 并按照 (rank, weight) 倒序排序
f) 按照x["description"]描述拼接起来小于max_token_size(4000)截取到 all_edges_data ,存入 use_relations
_build_local_query_context
从 node_datas 提取数据,组成 entites_section_list , 进一步生成 entities_context
从 use_relations 提取数据, 组成 relations_section_list , 进一步生成 relations_context
从 use_text_units 提取数据,组成 text_units_section_list , 进一步生成 text_units_context
经以上三种数据拼接成上下文返回 Entities + Relationships + Sources
local_query
使用PROMPTS["rag_response"]提问大模型
全局搜索
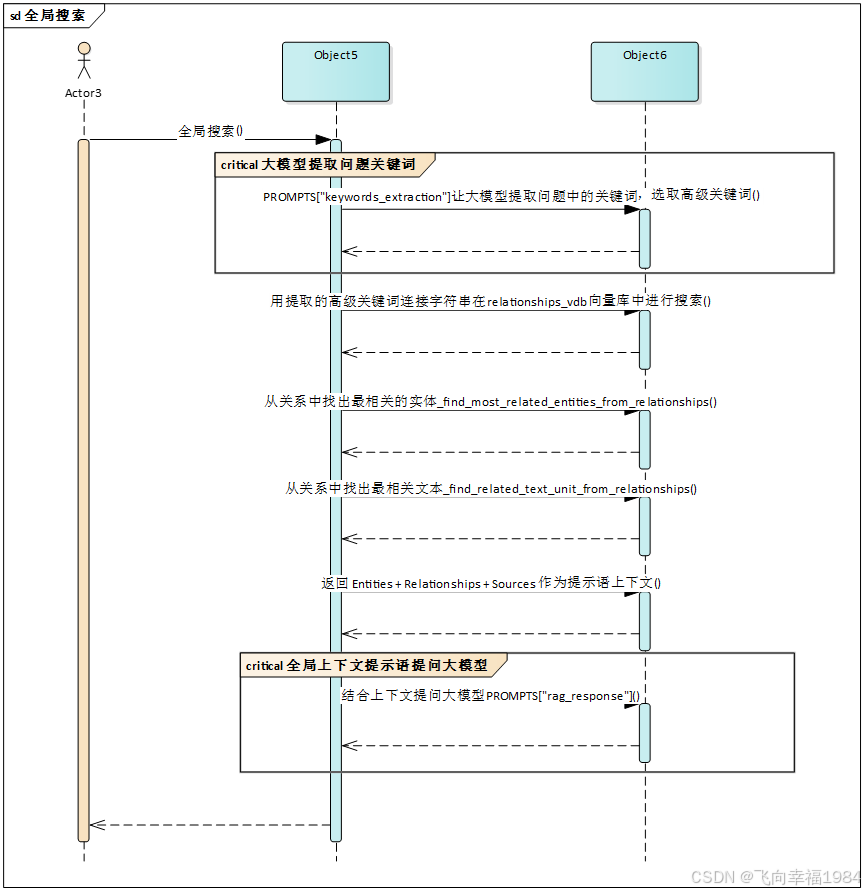
aquery -> global_query -> use_model_func
a) PROMPTS["keywords_extraction"]让大模型提取问题中的关键词,选取高级关键词
global_query -> _build_global_query_context
a) 用提取的关键词在relationships_vdb向量库中进行搜索
b) 获取a中对应的边数据edge_datas
c) 获取边的度edge_degree
d) 将relationships数据 + edge_datas + edge_degree 组装成 edge_datas
e) 将 edge_datas 按照 rank, weight 倒序排序
f) 根据描述的拼接长度小于4000,进行数据截取
_build_global_query_context -> _find_most_related_entities_from_relationships
a) 从edge_datas中提取 entity_names
b) 根据 entity_name 从图中获取节点信息到 node_datas
c) 根据 entity_name 从图中获取节点度到 node_degrees
d) 将 entity_names + node_datas + node_degrees 组装成 node_datas
e) 根据描述的拼接长度小于4000,进行数据截取, 生成 use_entities
_build_global_query_context -> _find_related_text_unit_from_relationships
a) 根据edge_datas获取源文本片段列表text_units
b) 遍历text_units根据c_id获取文本片段数据,并按照文本索引order递增排序,生成 all_text_units
c) 拼接 all_text_units 中 x["data"]["content"],限制长度小于4000,进行数据截取
_build_global_query_context
根据 edge_datas 生成 relations_context
根据 use_entities 生成 entities_context
根据 use_text_units 生成 text_units_context
返回 Entities + Relationships + Sources 作为大模型上下文
global_query
结合上下文提问大模型PROMPTS["rag_response"]
混合搜索
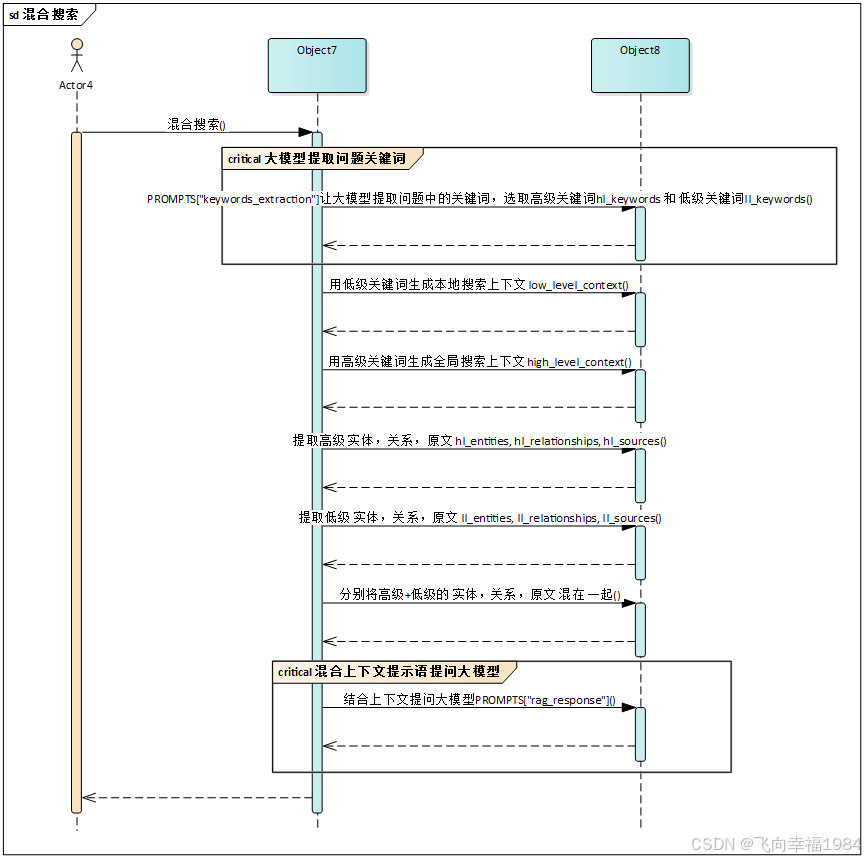
aquery -> hybrid_query
a) PROMPTS["keywords_extraction"]让大模型提取问题中的关键词,选取高级关键词hl_keywords 和 低级关键词ll_keywords
hybrid_query -> _build_local_query_context
a) 生成本地搜索上下文 low_level_context
hybrid_query -> _build_global_query_context
a) 生成全局搜索上下文 high_level_context
hybrid_query -> combine_contexts
a) 提取高级 实体,关系,原文 hl_entities, hl_relationships, hl_sources
b) 提取低级 实体,关系,原文 ll_entities, ll_relationships, ll_sources
combine_contexts -> process_combine_contexts
分别将高级+低级的 实体,关系,原文 混在 一起 (上限4000没有变, 那context应该 double了)
hybrid_query
结合上下文提问大模型PROMPTS["rag_response"]
结论
- LightRAG从多方面看比GraphRAG更高效,抗干扰效果更好
- LightRAG提示语默认不支持前置知识溯源
| GraphRAG | LightRAG | 总结 |
| 实体、关系提取都是两次访问大模型 | ||
| 对每一个边和节点描述访问大模型生成总结 | 只对于长度超出规格的描述列表,访问大模型生成总结 | LightRAG更高效 |
| 用大模型生成社区报告 | 不生成社区报告 | LightRAG更高效 |
| 用问题向量直接在实体描述向量库里搜索top20 | 大模型先提取问题关键词; 用关键词字符串生成的向量在实体向量库中进行搜索 | LightRAG多一步让大模型提取关键词,这样,从理论上来说,命中率,抗干扰效果都会提高 |
| 综合reports + entities + [relationships] + sources 组成上下文 | Entities + Relationships + Sources拼接成提示语上下文 | LightRAG上下文没有reports部分 |
| 需要重新生成图 | 不用重新生成图,动态更新图数据 | LightRAG更高效 |
| Prompt相对长 | Prompt相对更简短 | |
| 提示语支持前置知识溯源 | 提示语不支持前置知识溯源 | |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









