







最近我们被客户要求撰写关于RStan的研究报告,包括一些图形和统计输出。
Stan是一种用于指定统计模型的概率编程语言。Stan通过马尔可夫链蒙特卡罗方法(例如No-U-Turn采样器,一种汉密尔顿蒙特卡洛采样的自适应形式)为连续变量模型提供了完整的贝叶斯推断。
可以通过R使用rstan 包来调用Stan,也可以 通过Python使用 pystan 包。这两个接口都支持基于采样和基于优化的推断,并带有诊断和后验分析。
在本文中,简要展示了Stan的主要特性。还显示了两个示例:第一个示例与简单的伯努利模型相关,第二个示例与基于常微分方程的Lotka-Volterra模型有关。
什么是Stan?
- Stan是命令式概率编程语言。
- Stan程序定义了概率模型。
- 它声明数据和(受约束的)参数变量。
- 它定义了对数后验。
- Stan推理:使模型拟合数据并做出预测。
- 它可以使用马尔可夫链蒙特卡罗(MCMC)进行完整的贝叶斯推断。
- 使用变分贝叶斯(VB)进行近似贝叶斯推断。
- 最大似然估计(MLE)用于惩罚最大似然估计。
Stan计算什么?
- 得出后验分布 。
- MCMC采样。
- 绘制
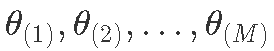 ,其中每个绘制
,其中每个绘制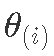 都按后验概率
都按后验概率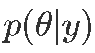 的边缘分布。
的边缘分布。 - 使用直方图,核密度估计等进行绘图
安装 rstan
要在R中运行Stan,必须安装 rstan C ++编译器。在Windows上, Rtools 是必需的。
最后,安装 rstan:
install.packages(rstan)Stan中的基本语法
定义模型
Stan模型由六个程序块定义 :
- 数据(必填)。
- 转换后的数据。
- 参数(必填)。
- 转换后的参数。
- 模型(必填)。
- 生成的数量。
数据块读出的外部信息。
data {
int N;
int x[N];
int offset;
}变换后的数据 块允许数据的预处理。
transformed data {
int y[N];
for (n in 1:N)
y[n] = x[n] - offset;
}参数 块定义了采样的空间。
parameters {
real<lower=0> lambda1;
real<lower=0> lambda2;
}变换参数 块定义计算后验之前的参数处理。
transformed parameters {
real<lower=0> lambda;
lambda = lambda1 + lambda2;
}在 模型 块中,我们定义后验分布。
model {
y ~ poisson(lambda);
lambda1 ~ cauchy(0, 2.5);
lambda2 ~ cauchy(0, 2.5);
}最后, 生成的数量 块允许进行后处理。
generated quantities {
int x_predict;
x_predict = poisson_rng(lambda) + offset;
}类型
Stan有两种原始数据类型, 并且两者都是有界的。
- int 是整数类型。
- real
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









